 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflect to Inform: Boosting Multimodal Reasoning via Information-Gain-Driven Verification
Mar 27, 2026Multimodal Large Language Models (MLLMs) achieve strong multimodal reasoning performance, yet we identify a recurring failure mode in long-form generation: as outputs grow longer, models progressively drift away from image evidence and fall back on textual priors, resulting in ungrounded reasoning and hallucinations. Interestingly, Based on attention analysis, we find that MLLMs have a latent capability for late-stage visual verification that is present but not consistently activated. Motivated by this observation, we propose Visual Re-Examination (VRE), a self-evolving training framework that enables MLLMs to autonomously perform visual introspection during reasoning without additional visual inputs. Rather than distilling visual capabilities from a stronger teacher, VRE promotes iterative self-improvement by leveraging the model itself to generate reflection traces, making visual information actionable through information gain. Extensive experiments across diverse multimodal benchmarks demonstrate that VRE consistently improves reasoning accuracy and perceptual reliability, while substantially reducing hallucinations, especially in long-chain settings. Code is available at https://github.com/Xiaobu-USTC/VRE.
TAMTRL: Teacher-Aligned Reward Reshaping for Multi-Turn Reinforcement Learning in Long-Context Compression
Mar 23, 2026The rapid progress of large language models (LLMs) has led to remarkable performance gains across a wide range of tasks. However, when handling long documents that exceed the model's context window limit, the entire context cannot be processed in a single pass, making chunk-wise processing necessary. This requires multiple turns to read different chunks and update memory. However, supervision is typically provided only by the final outcome, which makes it difficult to evaluate the quality of memory updates at each turn in the multi-turn training setting. This introduces a temporal credit assignment challenge. Existing approaches, such as LLM-as-a-judge or process reward models, incur substantial computational overhead and suffer from estimation noise. To better address the credit assignment problem in multi-turn memory training, we propose Teacher-Aligned Reward Reshaping for Multi-Turn Reinforcement Learning (TAMTRL). TAMTRL leverages relevant documents as teacher signals by aligning them with each turn of model input and assigns rewards through normalized probabilities in a self-supervised manner. This provides fine-grained learning signals for each memory update and improves long-context processing. Experiments with multiple models of varying scales across seven long-context benchmarks show that TAMTRL consistently outperforms strong baselines, demonstrating its effectiveness. Our code is available at https://anonymous.4open.science/r/TAMTRL-F1F8.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025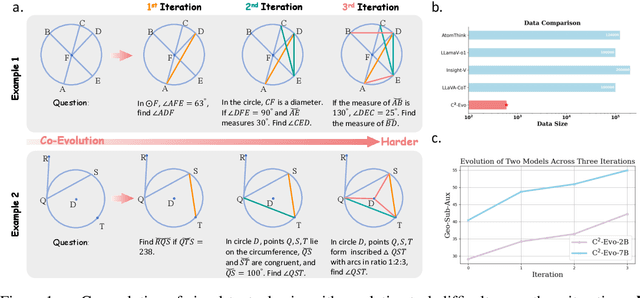

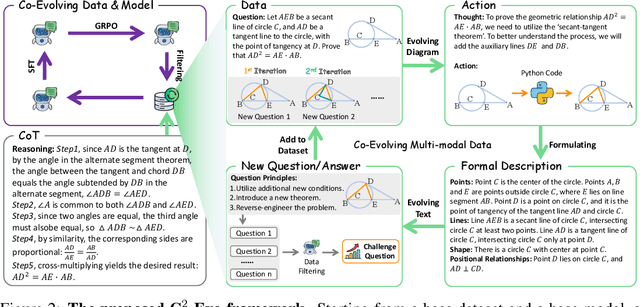
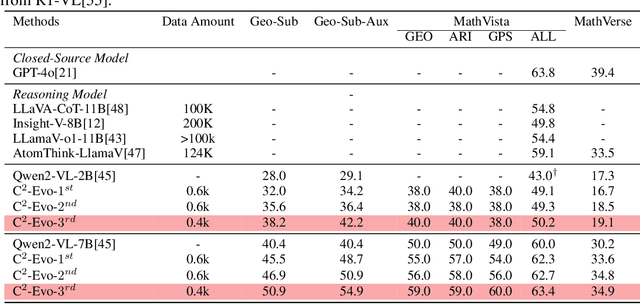
Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
PaMi-VDPO: Mitigating Video Hallucinations by Prompt-Aware Multi-Instance Video Preference Learning
Apr 08, 2025



Direct Preference Optimization (DPO) helps reduce hallucinations in Video Multimodal Large Language Models (VLLMs), but its reliance on offline preference data limits adaptability and fails to capture true video-response misalignment. We propose Video Direct Preference Optimization (VDPO), an online preference learning framework that eliminates the need for preference annotation by leveraging video augmentations to generate rejected samples while keeping responses fixed. However, selecting effective augmentations is non-trivial, as some clips may be semantically identical to the original under specific prompts, leading to false rejections and disrupting alignment. To address this, we introduce Prompt-aware Multi-instance Learning VDPO (PaMi-VDPO), which selects augmentations based on prompt context. Instead of a single rejection, we construct a candidate set of augmented clips and apply a close-to-far selection strategy, initially ensuring all clips are semantically relevant while then prioritizing the most prompt-aware distinct clip. This allows the model to better capture meaningful visual differences, mitigating hallucinations, while avoiding false rejections, and improving alignment. PaMi-VDPOseamlessly integrates into existing VLLMs without additional parameters, GPT-4/human supervision. With only 10k SFT data, it improves the base model by 5.3% on VideoHallucer, surpassing GPT-4o, while maintaining stable performance on general video benchmarks.
Exploiting Vulnerabilities in Speech Translation Systems through Targeted Adversarial Attacks
Mar 05, 2025As speech translation (ST) systems become increasingly prevalent, understanding their vulnerabilities is crucial for ensuring robust and reliable communication. However, limited work has explored this issue in depth. This paper explores methods of compromising these systems through imperceptible audio manipulations. Specifically, we present two innovative approaches: (1) the injection of perturbation into source audio, and (2) the generation of adversarial music designed to guide targeted translation, while also conducting more practical over-the-air attacks in the physical world. Our experiments reveal that carefully crafted audio perturbations can mislead translation models to produce targeted, harmful outputs, while adversarial music achieve this goal more covertly, exploiting the natural imperceptibility of music. These attacks prove effective across multiple languages and translation models, highlighting a systemic vulnerability in current ST architectures. The implications of this research extend beyond immediate security concerns, shedding light on the interpretability and robustness of neural speech processing systems. Our findings underscore the need for advanced defense mechanisms and more resilient architectures in the realm of audio systems. More details and samples can be found at https://adv-st.github.io.
Segue: Side-information Guided Generative Unlearnable Examples for Facial Privacy Protection in Real World
Oct 24, 2023The widespread use of face recognition technology has given rise to privacy concerns, as many individuals are worried about the collection and utilization of their facial data. To address these concerns, researchers are actively exploring the concept of ``unlearnable examples", by adding imperceptible perturbation to data in the model training stage, which aims to prevent the model from learning discriminate features of the target face. However, current methods are inefficient and cannot guarantee transferability and robustness at the same time, causing impracticality in the real world. To remedy it, we propose a novel method called Segue: Side-information guided generative unlearnable examples. Specifically, we leverage a once-trained multiple-used model to generate the desired perturbation rather than the time-consuming gradient-based method. To improve transferability, we introduce side information such as true labels and pseudo labels, which are inherently consistent across different scenarios. For robustness enhancement, a distortion layer is integrated into the training pipeline. Extensive experiments demonstrate that the proposed Segue is much faster than previous methods (1000$\times$) and achieves transferable effectiveness across different datasets and model architectures. Furthermore, it can resist JPEG compression, adversarial training, and some standard data augmentations.
Ada3Diff: Defending against 3D Adversarial Point Clouds via Adaptive Diffusion
Nov 29, 2022Deep 3D point cloud models are sensitive to adversarial attacks, which poses threats to safety-critical applications such as autonomous driving. Robust training and defend-by-denoise are typical strategies for defending adversarial perturbations, including adversarial training and statistical filtering, respectively. However, they either induce massive computational overhead or rely heavily upon specified noise priors, limiting generalized robustness against attacks of all kinds. This paper introduces a new defense mechanism based on denoising diffusion models that can adaptively remove diverse noises with a tailored intensity estimator. Specifically, we first estimate adversarial distortions by calculating the distance of the points to their neighborhood best-fit plane. Depending on the distortion degree, we choose specific diffusion time steps for the input point cloud and perform the forward diffusion to disrupt potential adversarial shifts. Then we conduct the reverse denoising process to restore the disrupted point cloud back to a clean distribution. This approach enables effective defense against adaptive attacks with varying noise budgets, achieving accentuated robustness of existing 3D deep recognition models.
PointCAT: Contrastive Adversarial Training for Robust Point Cloud Recognition
Sep 16, 2022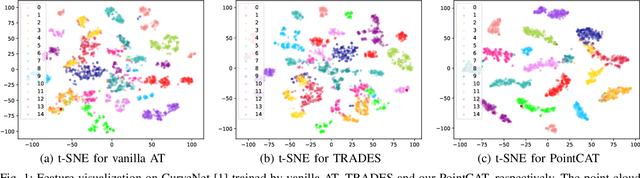
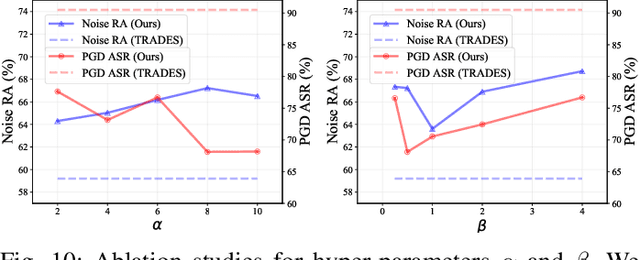
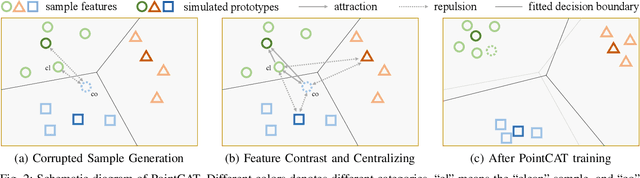
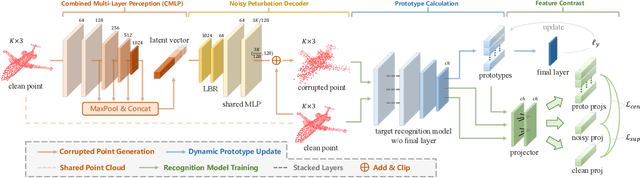
Notwithstanding the prominent performance achieved in various applications, point cloud recognition models have often suffered from natural corruptions and adversarial perturbations. In this paper, we delve into boosting the general robustness of point cloud recognition models and propose Point-Cloud Contrastive Adversarial Training (PointCAT). The main intuition of PointCAT is encouraging the target recognition model to narrow the decision gap between clean point clouds and corrupted point clouds. Specifically, we leverage a supervised contrastive loss to facilitate the alignment and uniformity of the hypersphere features extracted by the recognition model, and design a pair of centralizing losses with the dynamic prototype guidance to avoid these features deviating from their belonging category clusters. To provide the more challenging corrupted point clouds, we adversarially train a noise generator along with the recognition model from the scratch, instead of using gradient-based attack as the inner loop like previous adversarial training methods. Comprehensive experiments show that the proposed PointCAT outperforms the baseline methods and dramatically boosts the robustness of different point cloud recognition models, under a variety of corruptions including isotropic point noises, the LiDAR simulated noises, random point dropping and adversarial perturbations.