 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning
Sep 26, 2025Image captioning is a fundamental task that bridges the visual and linguistic domains, playing a critical role in pre-training Large Vision-Language Models (LVLMs). Current state-of-the-art captioning models are typically trained with Supervised Fine-Tuning (SFT), a paradigm that relies on expensive, non-scalable data annotated by humans or proprietary models. This approach often leads to models that memorize specific ground-truth answers, limiting their generality and ability to generate diverse, creative descriptions. To overcome the limitation of SFT, we propose applying the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm to the open-ended task of image captioning. A primary challenge, however, is designing an objective reward function for the inherently subjective nature of what constitutes a "good" caption. We introduce Captioning Reinforcement Learning (CapRL), a novel training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding image. CapRL employs a decoupled two-stage pipeline where an LVLM generates a caption, and the objective reward is derived from the accuracy of a separate, vision-free LLM answering Multiple-Choice Questions based solely on that caption. As the first study to apply RLVR to the subjective image captioning task, we demonstrate that CapRL significantly enhances multiple settings. Pretraining on the CapRL-5M caption dataset annotated by CapRL-3B results in substantial gains across 12 benchmarks. Moreover, within the Prism Framework for caption quality evaluation, CapRL achieves performance comparable to Qwen2.5-VL-72B, while exceeding the baseline by an average margin of 8.4%. Code is available here: https://github.com/InternLM/CapRL.
ScaleCap: Inference-Time Scalable Image Captioning via Dual-Modality Debiasing
Jun 24, 2025
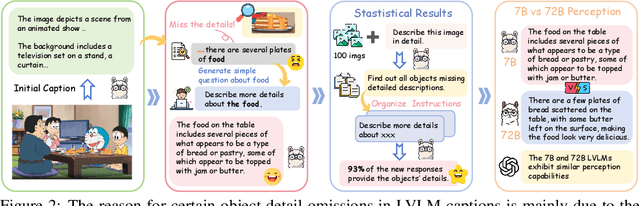


This paper presents ScaleCap, an inference-time scalable image captioning strategy that generates comprehensive and detailed image captions. The key challenges of high-quality image captioning lie in the inherent biases of LVLMs: multimodal bias resulting in imbalanced descriptive granularity, offering detailed accounts of some elements while merely skimming over others; linguistic bias leading to hallucinated descriptions of non-existent objects. To address these issues, we propose a scalable debiased captioning strategy, which continuously enriches and calibrates the caption with increased inference budget. Specifically, we propose two novel components: heuristic question answering and contrastive sentence rating. The former generates content-specific questions based on the image and answers them to progressively inject relevant information into the caption. The latter employs sentence-level offline contrastive decoding to effectively identify and eliminate hallucinations caused by linguistic biases. With increased inference cost, more heuristic questions are raised by ScaleCap to progressively capture additional visual details, generating captions that are more accurate, balanced, and informative. Extensive modality alignment experiments demonstrate the effectiveness of ScaleCap. Annotating 450K images with ScaleCap and using them for LVLM pretraining leads to consistent performance gains across 11 widely used benchmarks. Furthermore, ScaleCap showcases superb richness and fidelity of generated captions with two additional tasks: replacing images with captions in VQA task, and reconstructing images from captions to assess semantic coverage. Code is available at https://github.com/Cooperx521/ScaleCap.
MMRC: A Large-Scale Benchmark for Understanding Multimodal Large Language Model in Real-World Conversation
Feb 17, 2025Recent multimodal large language models (MLLMs) have demonstrated significant potential in open-ended conversation, generating more accurate and personalized responses. However, their abilities to memorize, recall, and reason in sustained interactions within real-world scenarios remain underexplored. This paper introduces MMRC, a Multi-Modal Real-world Conversation benchmark for evaluating six core open-ended abilities of MLLMs: information extraction, multi-turn reasoning, information update, image management, memory recall, and answer refusal. With data collected from real-world scenarios, MMRC comprises 5,120 conversations and 28,720 corresponding manually labeled questions, posing a significant challenge to existing MLLMs. Evaluations on 20 MLLMs in MMRC indicate an accuracy drop during open-ended interactions. We identify four common failure patterns: long-term memory degradation, inadequacies in updating factual knowledge, accumulated assumption of error propagation, and reluctance to say no. To mitigate these issues, we propose a simple yet effective NOTE-TAKING strategy, which can record key information from the conversation and remind the model during its responses, enhancing conversational capabilities. Experiments across six MLLMs demonstrate significant performance improvements.
Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
Feb 12, 2025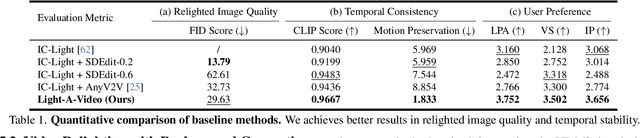
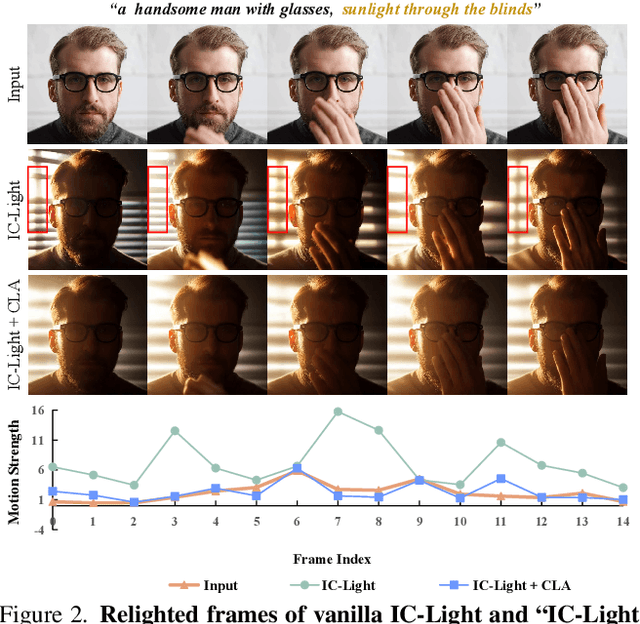
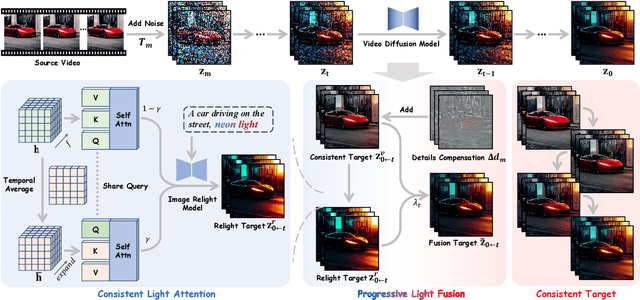
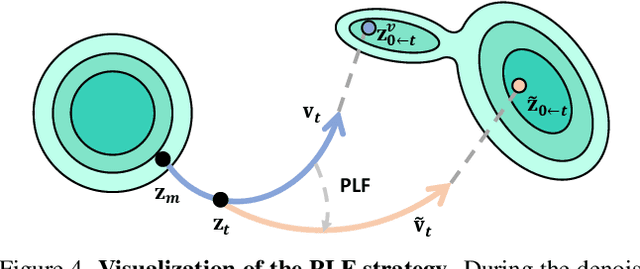
Recent advancements in image relighting models, driven by large-scale datasets and pre-trained diffusion models, have enabled the imposition of consistent lighting. However, video relighting still lags, primarily due to the excessive training costs and the scarcity of diverse, high-quality video relighting datasets. A simple application of image relighting models on a frame-by-frame basis leads to several issues: lighting source inconsistency and relighted appearance inconsistency, resulting in flickers in the generated videos. In this work, we propose Light-A-Video, a training-free approach to achieve temporally smooth video relighting. Adapted from image relighting models, Light-A-Video introduces two key techniques to enhance lighting consistency. First, we design a Consistent Light Attention (CLA) module, which enhances cross-frame interactions within the self-attention layers to stabilize the generation of the background lighting source. Second, leveraging the physical principle of light transport independence, we apply linear blending between the source video's appearance and the relighted appearance, using a Progressive Light Fusion (PLF) strategy to ensure smooth temporal transitions in illumination. Experiments show that Light-A-Video improves the temporal consistency of relighted video while maintaining the image quality, ensuring coherent lighting transitions across frames. Project page: https://bujiazi.github.io/light-a-video.github.io/.
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Oct 22, 2024In large vision-language models (LVLMs), images serve as inputs that carry a wealth of information. As the idiom "A picture is worth a thousand words" implies, representing a single image in current LVLMs can require hundreds or even thousands of tokens. This results in significant computational costs, which grow quadratically as input image resolution increases, thereby severely impacting the efficiency of both training and inference. Previous approaches have attempted to reduce the number of image tokens either before or within the early layers of LVLMs. However, these strategies inevitably result in the loss of crucial image information, ultimately diminishing model performance. To address this challenge, we conduct an empirical study revealing that all visual tokens are necessary for LVLMs in the shallow layers, and token redundancy progressively increases in the deeper layers of the model. To this end, we propose PyramidDrop, a visual redundancy reduction strategy for LVLMs to boost their efficiency in both training and inference with neglectable performance loss. Specifically, we partition the LVLM into several stages and drop part of the image tokens at the end of each stage with a pre-defined ratio, creating pyramid-like visual tokens across model layers. The dropping is based on a lightweight similarity calculation with a negligible time overhead. Extensive experiments demonstrate that PyramidDrop can achieve a 40% training time and 55% inference FLOPs acceleration of LLaVA-NeXT with comparable performance. Besides, the PyramidDrop could also serve as a plug-and-play strategy for inference acceleration without training, with better performance and lower inference cost than counterparts. We hope that the insights and approach introduced by PyramidDrop will inspire future research to further investigate the role of image tokens in LVLMs.
Deciphering Cross-Modal Alignment in Large Vision-Language Models with Modality Integration Rate
Oct 09, 2024



We present the Modality Integration Rate (MIR), an effective, robust, and generalized metric to indicate the multi-modal pre-training quality of Large Vision Language Models (LVLMs). Large-scale pre-training plays a critical role in building capable LVLMs, while evaluating its training quality without the costly supervised fine-tuning stage is under-explored. Loss, perplexity, and in-context evaluation results are commonly used pre-training metrics for Large Language Models (LLMs), while we observed that these metrics are less indicative when aligning a well-trained LLM with a new modality. Due to the lack of proper metrics, the research of LVLMs in the critical pre-training stage is hindered greatly, including the training data choice, efficient module design, etc. In this paper, we propose evaluating the pre-training quality from the inter-modal distribution distance perspective and present MIR, the Modality Integration Rate, which is 1) \textbf{Effective} to represent the pre-training quality and show a positive relation with the benchmark performance after supervised fine-tuning. 2) \textbf{Robust} toward different training/evaluation data. 3) \textbf{Generalize} across training configurations and architecture choices. We conduct a series of pre-training experiments to explore the effectiveness of MIR and observe satisfactory results that MIR is indicative about training data selection, training strategy schedule, and model architecture design to get better pre-training results. We hope MIR could be a helpful metric for building capable LVLMs and inspire the following research about modality alignment in different areas. Our code is at: https://github.com/shikiw/Modality-Integration-Rate.
SimAC: A Simple Anti-Customization Method against Text-to-Image Synthesis of Diffusion Models
Dec 13, 2023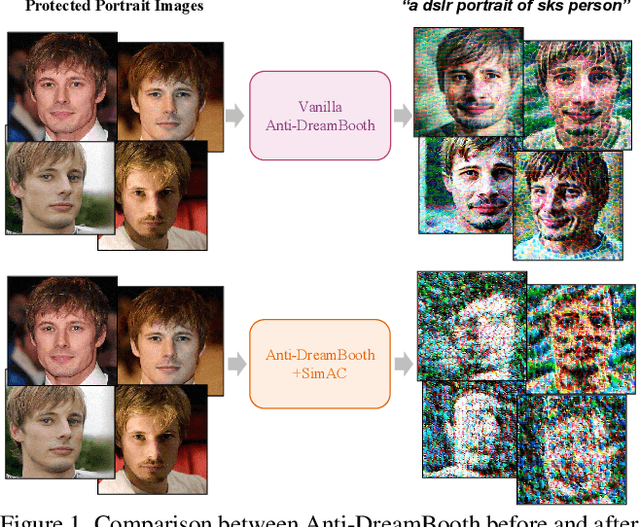
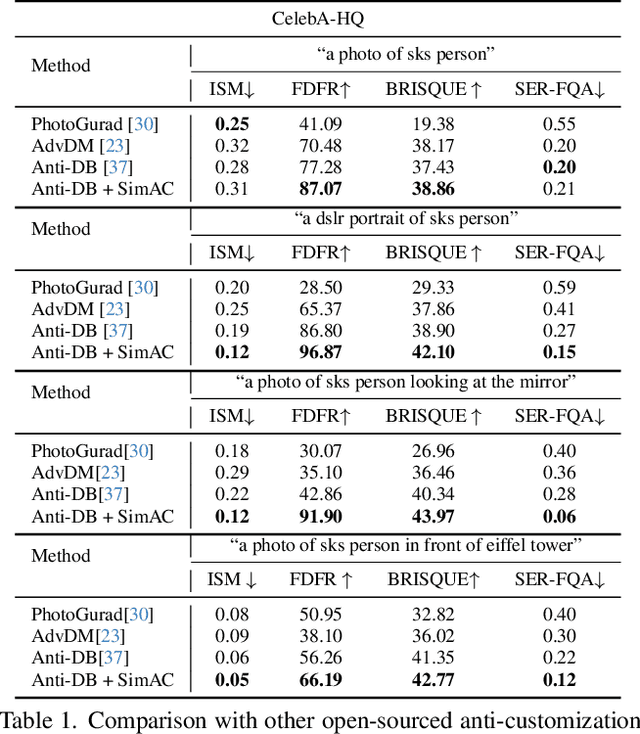
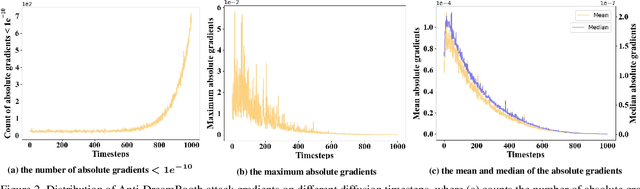
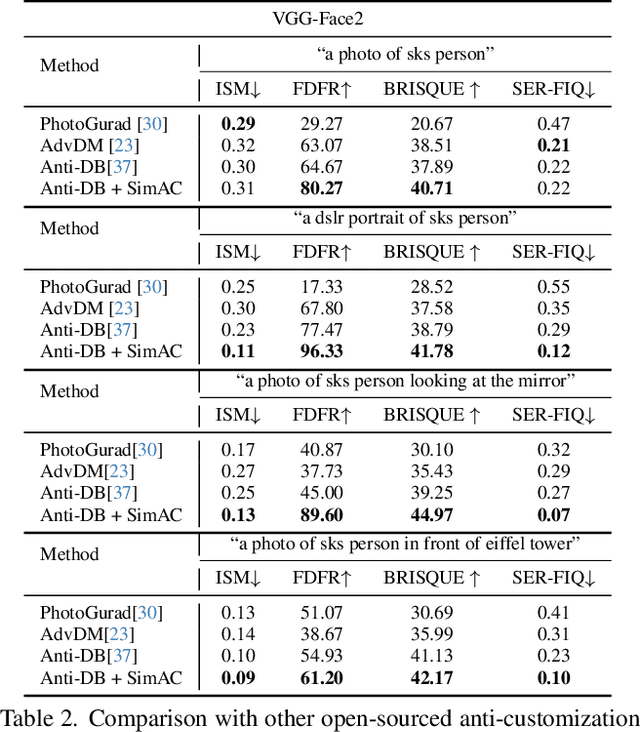
Despite the success of diffusion-based customization methods on visual content creation, increasing concerns have been raised about such techniques from both privacy and political perspectives. To tackle this issue, several anti-customization methods have been proposed in very recent months, predominantly grounded in adversarial attacks. Unfortunately, most of these methods adopt straightforward designs, such as end-to-end optimization with a focus on adversarially maximizing the original training loss, thereby neglecting nuanced internal properties intrinsic to the diffusion model, and even leading to ineffective optimization in some diffusion time steps. In this paper, we strive to bridge this gap by undertaking a comprehensive exploration of these inherent properties, to boost the performance of current anti-customization approaches. Two aspects of properties are investigated: 1) We examine the relationship between time step selection and the model's perception in the frequency domain of images and find that lower time steps can give much more contributions to adversarial noises. This inspires us to propose an adaptive greedy search for optimal time steps that seamlessly integrates with existing anti-customization methods. 2) We scrutinize the roles of features at different layers during denoising and devise a sophisticated feature-based optimization framework for anti-customization. Experiments on facial benchmarks demonstrate that our approach significantly increases identity disruption, thereby enhancing user privacy and security.
OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation
Nov 29, 2023Hallucination, posed as a pervasive challenge of multi-modal large language models (MLLMs), has significantly impeded their real-world usage that demands precise judgment. Existing methods mitigate this issue with either training with specific designed data or inferencing with external knowledge from other sources, incurring inevitable additional costs. In this paper, we present OPERA, a novel MLLM decoding method grounded in an Over-trust Penalty and a Retrospection-Allocation strategy, serving as a nearly free lunch to alleviate the hallucination issue without additional data, knowledge, or training. Our approach begins with an interesting observation that, most hallucinations are closely tied to the knowledge aggregation patterns manifested in the self-attention matrix, i.e., MLLMs tend to generate new tokens by focusing on a few summary tokens, but not all the previous tokens. Such partial over-trust inclination results in the neglecting of image tokens and describes the image content with hallucination. Statistically, we observe an 80%$\sim$95% co-currency rate between hallucination contents and such knowledge aggregation patterns. Based on the observation, OPERA introduces a penalty term on the model logits during the beam-search decoding to mitigate the over-trust issue, along with a rollback strategy that retrospects the presence of summary tokens in the previously generated tokens, and re-allocate the token selection if necessary. With extensive experiments, OPERA shows significant hallucination-mitigating performance on different MLLMs and metrics, proving its effectiveness and generality. Our code is available at: https://github.com/shikiw/OPERA.
Improving Adversarial Robustness of Masked Autoencoders via Test-time Frequency-domain Prompting
Aug 22, 2023In this paper, we investigate the adversarial robustness of vision transformers that are equipped with BERT pretraining (e.g., BEiT, MAE). A surprising observation is that MAE has significantly worse adversarial robustness than other BERT pretraining methods. This observation drives us to rethink the basic differences between these BERT pretraining methods and how these differences affect the robustness against adversarial perturbations. Our empirical analysis reveals that the adversarial robustness of BERT pretraining is highly related to the reconstruction target, i.e., predicting the raw pixels of masked image patches will degrade more adversarial robustness of the model than predicting the semantic context, since it guides the model to concentrate more on medium-/high-frequency components of images. Based on our analysis, we provide a simple yet effective way to boost the adversarial robustness of MAE. The basic idea is using the dataset-extracted domain knowledge to occupy the medium-/high-frequency of images, thus narrowing the optimization space of adversarial perturbations. Specifically, we group the distribution of pretraining data and optimize a set of cluster-specific visual prompts on frequency domain. These prompts are incorporated with input images through prototype-based prompt selection during test period. Extensive evaluation shows that our method clearly boost MAE's adversarial robustness while maintaining its clean performance on ImageNet-1k classification. Our code is available at: https://github.com/shikiw/RobustMAE.
Diversity-Aware Meta Visual Prompting
Mar 14, 2023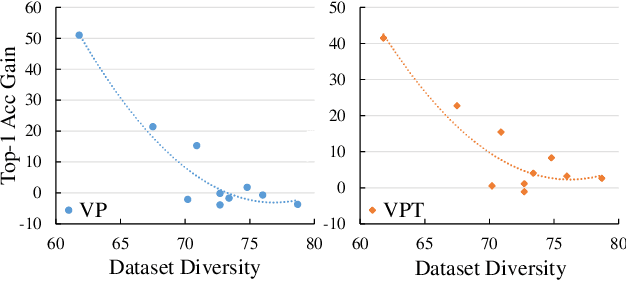
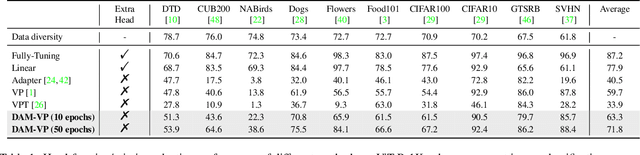
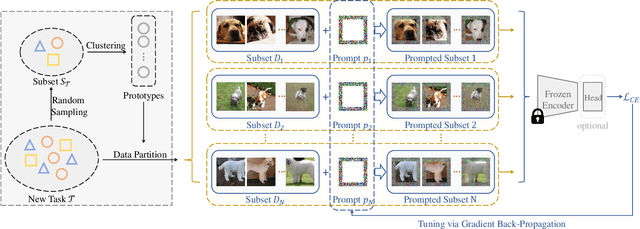
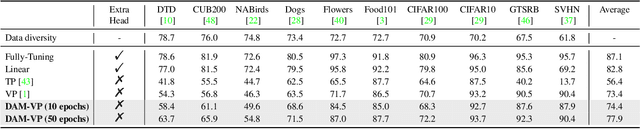
We present Diversity-Aware Meta Visual Prompting~(DAM-VP), an efficient and effective prompting method for transferring pre-trained models to downstream tasks with frozen backbone. A challenging issue in visual prompting is that image datasets sometimes have a large data diversity whereas a per-dataset generic prompt can hardly handle the complex distribution shift toward the original pretraining data distribution properly. To address this issue, we propose a dataset Diversity-Aware prompting strategy whose initialization is realized by a Meta-prompt. Specifically, we cluster the downstream dataset into small homogeneity subsets in a diversity-adaptive way, with each subset has its own prompt optimized separately. Such a divide-and-conquer design reduces the optimization difficulty greatly and significantly boosts the prompting performance. Furthermore, all the prompts are initialized with a meta-prompt, which is learned across several datasets. It is a bootstrapped paradigm, with the key observation that the prompting knowledge learned from previous datasets could help the prompt to converge faster and perform better on a new dataset. During inference, we dynamically select a proper prompt for each input, based on the feature distance between the input and each subset. Through extensive experiments, our DAM-VP demonstrates superior efficiency and effectiveness, clearly surpassing previous prompting methods in a series of downstream datasets for different pretraining models. Our code is available at: \url{https://github.com/shikiw/DAM-VP}.