 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-Classifier: Leveraging Video Diffusion Priors for Universal Guidance Classifier
Mar 20, 2026In practical AI workflows, complex tasks often involve chaining multiple generative models, such as using a video or 3D generation model after a 2D image generator. However, distributional mismatches between the output of upstream models and the expected input of downstream models frequently degrade overall generation quality. To address this issue, we propose Uni-Classifier (Uni-C), a simple yet effective plug-and-play module that leverages video diffusion priors to guide the denoising process of preceding models, thereby aligning their outputs with downstream requirements. Uni-C can also be applied independently to enhance the output quality of individual generative models. Extensive experiments across video and 3D generation tasks demonstrate that Uni-C consistently improves generation quality in both workflow-based and standalone settings, highlighting its versatility and strong generalization capability.
From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
Mar 13, 2026Group Relative Policy Optimization (GRPO) has emerged as a powerful framework for preference alignment in text-to-image (T2I) flow models. However, we observe that the standard paradigm where evaluating a group of generated samples against a single condition suffers from insufficient exploration of inter-sample relationships, constraining both alignment efficacy and performance ceilings. To address this sparse single-view evaluation scheme, we propose Multi-View GRPO (MV-GRPO), a novel approach that enhances relationship exploration by augmenting the condition space to create a dense multi-view reward mapping. Specifically, for a group of samples generated from one prompt, MV-GRPO leverages a flexible Condition Enhancer to generate semantically adjacent yet diverse captions. These captions enable multi-view advantage re-estimation, capturing diverse semantic attributes and providing richer optimization signals. By deriving the probability distribution of the original samples conditioned on these new captions, we can incorporate them into the training process without costly sample regeneration. Extensive experiments demonstrate that MV-GRPO achieves superior alignment performance over state-of-the-art methods.
EndoCoT: Scaling Endogenous Chain-of-Thought Reasoning in Diffusion Models
Mar 12, 2026Recently, Multimodal Large Language Models (MLLMs) have been widely integrated into diffusion frameworks primarily as text encoders to tackle complex tasks such as spatial reasoning. However, this paradigm suffers from two critical limitations: (i) MLLMs text encoder exhibits insufficient reasoning depth. Single-step encoding fails to activate the Chain-of-Thought process, which is essential for MLLMs to provide accurate guidance for complex tasks. (ii) The guidance remains invariant during the decoding process. Invariant guidance during decoding prevents DiT from progressively decomposing complex instructions into actionable denoising steps, even with correct MLLM encodings. To this end, we propose Endogenous Chain-of-Thought (EndoCoT), a novel framework that first activates MLLMs' reasoning potential by iteratively refining latent thought states through an iterative thought guidance module, and then bridges these states to the DiT's denoising process. Second, a terminal thought grounding module is applied to ensure the reasoning trajectory remains grounded in textual supervision by aligning the final state with ground-truth answers. With these two components, the MLLM text encoder delivers meticulously reasoned guidance, enabling the DiT to execute it progressively and ultimately solve complex tasks in a step-by-step manner. Extensive evaluations across diverse benchmarks (e.g., Maze, TSP, VSP, and Sudoku) achieve an average accuracy of 92.1%, outperforming the strongest baseline by 8.3 percentage points.
Unified Personalized Reward Model for Vision Generation
Feb 02, 2026Recent advancements in multimodal reward models (RMs) have significantly propelled the development of visual generation. Existing frameworks typically adopt Bradley-Terry-style preference modeling or leverage generative VLMs as judges, and subsequently optimize visual generation models via reinforcement learning. However, current RMs suffer from inherent limitations: they often follow a one-size-fits-all paradigm that assumes a monolithic preference distribution or relies on fixed evaluation rubrics. As a result, they are insensitive to content-specific visual cues, leading to systematic misalignment with subjective and context-dependent human preferences. To this end, inspired by human assessment, we propose UnifiedReward-Flex, a unified personalized reward model for vision generation that couples reward modeling with flexible and context-adaptive reasoning. Specifically, given a prompt and the generated visual content, it first interprets the semantic intent and grounds on visual evidence, then dynamically constructs a hierarchical assessment by instantiating fine-grained criteria under both predefined and self-generated high-level dimensions. Our training pipeline follows a two-stage process: (1) we first distill structured, high-quality reasoning traces from advanced closed-source VLMs to bootstrap SFT, equipping the model with flexible and context-adaptive reasoning behaviors; (2) we then perform direct preference optimization (DPO) on carefully curated preference pairs to further strengthen reasoning fidelity and discriminative alignment. To validate the effectiveness, we integrate UnifiedReward-Flex into the GRPO framework for image and video synthesis, and extensive results demonstrate its superiority.
$\text{G}^2$RPO: Granular GRPO for Precise Reward in Flow Models
Oct 02, 2025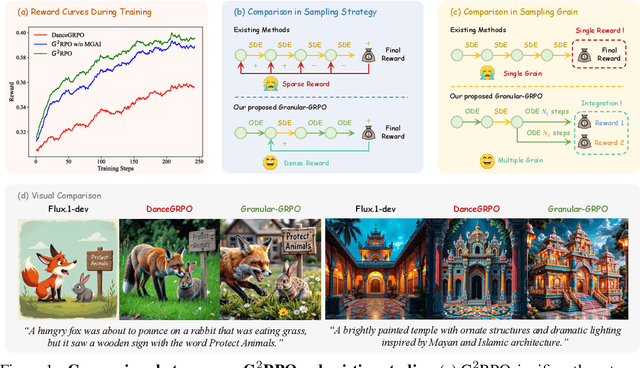
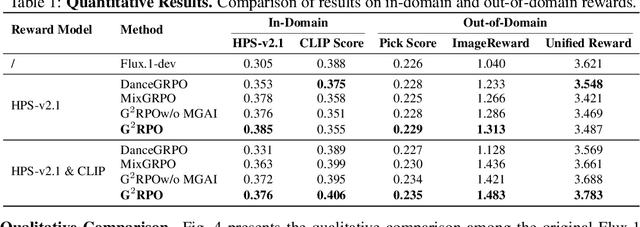
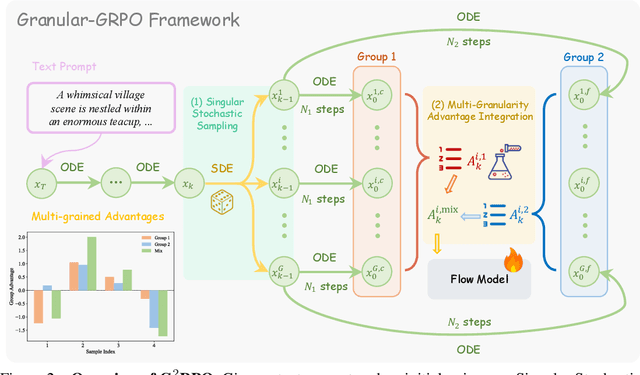
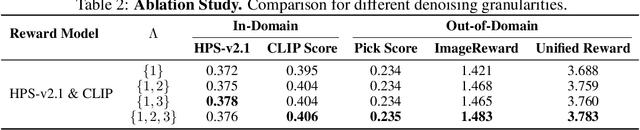
The integration of online reinforcement learning (RL) into diffusion and flow models has recently emerged as a promising approach for aligning generative models with human preferences. Stochastic sampling via Stochastic Differential Equations (SDE) is employed during the denoising process to generate diverse denoising directions for RL exploration. While existing methods effectively explore potential high-value samples, they suffer from sub-optimal preference alignment due to sparse and narrow reward signals. To address these challenges, we propose a novel Granular-GRPO ($\text{G}^2$RPO ) framework that achieves precise and comprehensive reward assessments of sampling directions in reinforcement learning of flow models. Specifically, a Singular Stochastic Sampling strategy is introduced to support step-wise stochastic exploration while enforcing a high correlation between the reward and the injected noise, thereby facilitating a faithful reward for each SDE perturbation. Concurrently, to eliminate the bias inherent in fixed-granularity denoising, we introduce a Multi-Granularity Advantage Integration module that aggregates advantages computed at multiple diffusion scales, producing a more comprehensive and robust evaluation of the sampling directions. Experiments conducted on various reward models, including both in-domain and out-of-domain evaluations, demonstrate that our $\text{G}^2$RPO significantly outperforms existing flow-based GRPO baselines,highlighting its effectiveness and robustness.
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Aug 28, 2025Recent advancements highlight the importance of GRPO-based reinforcement learning methods and benchmarking in enhancing text-to-image (T2I) generation. However, current methods using pointwise reward models (RM) for scoring generated images are susceptible to reward hacking. We reveal that this happens when minimal score differences between images are amplified after normalization, creating illusory advantages that drive the model to over-optimize for trivial gains, ultimately destabilizing the image generation process. To address this, we propose Pref-GRPO, a pairwise preference reward-based GRPO method that shifts the optimization objective from score maximization to preference fitting, ensuring more stable training. In Pref-GRPO, images are pairwise compared within each group using preference RM, and the win rate is used as the reward signal. Extensive experiments demonstrate that PREF-GRPO differentiates subtle image quality differences, providing more stable advantages and mitigating reward hacking. Additionally, existing T2I benchmarks are limited by coarse evaluation criteria, hindering comprehensive model assessment. To solve this, we introduce UniGenBench, a unified T2I benchmark comprising 600 prompts across 5 main themes and 20 subthemes. It evaluates semantic consistency through 10 primary and 27 sub-criteria, leveraging MLLM for benchmark construction and evaluation. Our benchmarks uncover the strengths and weaknesses of both open and closed-source T2I models and validate the effectiveness of Pref-GRPO.
DiCache: Let Diffusion Model Determine Its Own Cache
Aug 24, 2025

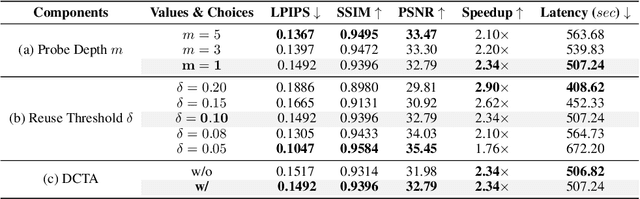
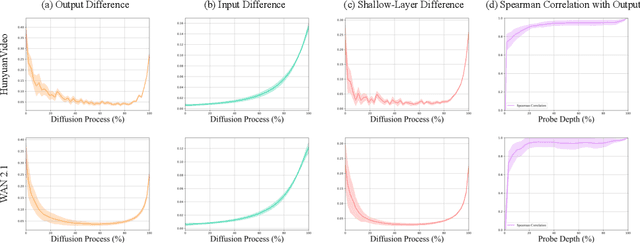
Recent years have witnessed the rapid development of acceleration techniques for diffusion models, especially caching-based acceleration methods. These studies seek to answer two fundamental questions: "When to cache" and "How to use cache", typically relying on predefined empirical laws or dataset-level priors to determine the timing of caching and utilizing handcrafted rules for leveraging multi-step caches. However, given the highly dynamic nature of the diffusion process, they often exhibit limited generalizability and fail on outlier samples. In this paper, a strong correlation is revealed between the variation patterns of the shallow-layer feature differences in the diffusion model and those of final model outputs. Moreover, we have observed that the features from different model layers form similar trajectories. Based on these observations, we present DiCache, a novel training-free adaptive caching strategy for accelerating diffusion models at runtime, answering both when and how to cache within a unified framework. Specifically, DiCache is composed of two principal components: (1) Online Probe Profiling Scheme leverages a shallow-layer online probe to obtain a stable prior for the caching error in real time, enabling the model to autonomously determine caching schedules. (2) Dynamic Cache Trajectory Alignment combines multi-step caches based on shallow-layer probe feature trajectory to better approximate the current feature, facilitating higher visual quality. Extensive experiments validate DiCache's capability in achieving higher efficiency and improved visual fidelity over state-of-the-art methods on various leading diffusion models including WAN 2.1, HunyuanVideo for video generation, and Flux for image generation.
HiFlow: Training-free High-Resolution Image Generation with Flow-Aligned Guidance
Apr 08, 2025

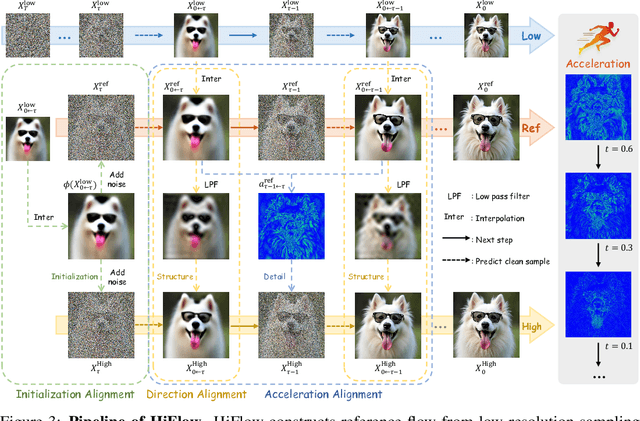

Text-to-image (T2I) diffusion/flow models have drawn considerable attention recently due to their remarkable ability to deliver flexible visual creations. Still, high-resolution image synthesis presents formidable challenges due to the scarcity and complexity of high-resolution content. To this end, we present HiFlow, a training-free and model-agnostic framework to unlock the resolution potential of pre-trained flow models. Specifically, HiFlow establishes a virtual reference flow within the high-resolution space that effectively captures the characteristics of low-resolution flow information, offering guidance for high-resolution generation through three key aspects: initialization alignment for low-frequency consistency, direction alignment for structure preservation, and acceleration alignment for detail fidelity. By leveraging this flow-aligned guidance, HiFlow substantially elevates the quality of high-resolution image synthesis of T2I models and demonstrates versatility across their personalized variants. Extensive experiments validate HiFlow's superiority in achieving superior high-resolution image quality over current state-of-the-art methods.
Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
Feb 12, 2025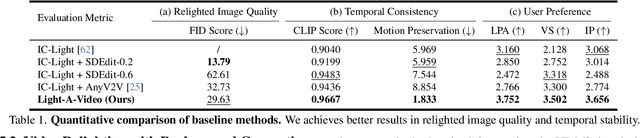
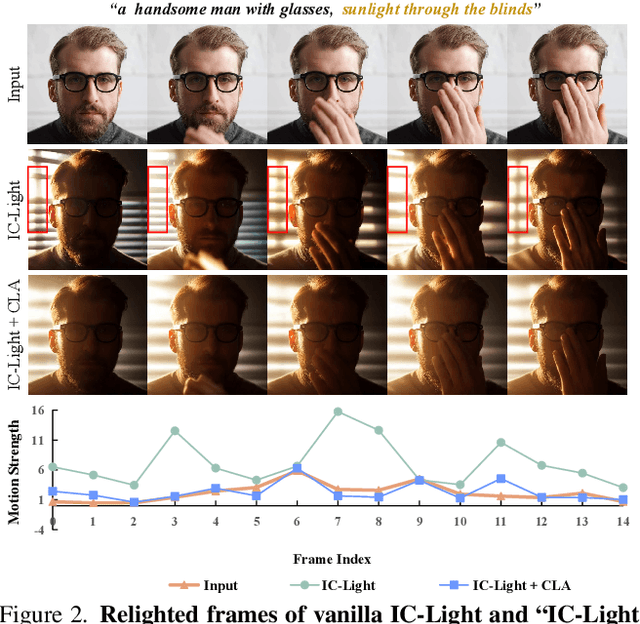
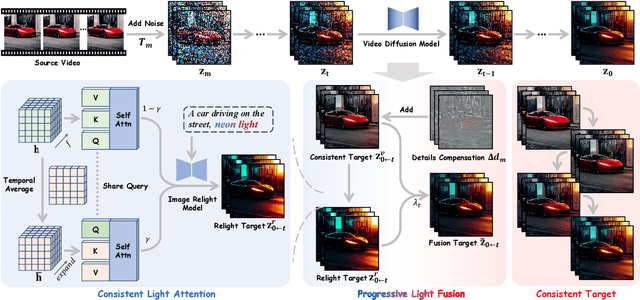
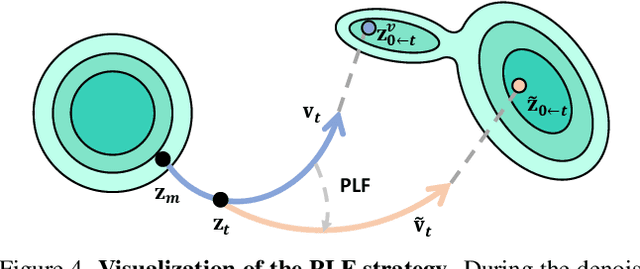
Recent advancements in image relighting models, driven by large-scale datasets and pre-trained diffusion models, have enabled the imposition of consistent lighting. However, video relighting still lags, primarily due to the excessive training costs and the scarcity of diverse, high-quality video relighting datasets. A simple application of image relighting models on a frame-by-frame basis leads to several issues: lighting source inconsistency and relighted appearance inconsistency, resulting in flickers in the generated videos. In this work, we propose Light-A-Video, a training-free approach to achieve temporally smooth video relighting. Adapted from image relighting models, Light-A-Video introduces two key techniques to enhance lighting consistency. First, we design a Consistent Light Attention (CLA) module, which enhances cross-frame interactions within the self-attention layers to stabilize the generation of the background lighting source. Second, leveraging the physical principle of light transport independence, we apply linear blending between the source video's appearance and the relighted appearance, using a Progressive Light Fusion (PLF) strategy to ensure smooth temporal transitions in illumination. Experiments show that Light-A-Video improves the temporal consistency of relighted video while maintaining the image quality, ensuring coherent lighting transitions across frames. Project page: https://bujiazi.github.io/light-a-video.github.io/.
BroadWay: Boost Your Text-to-Video Generation Model in a Training-free Way
Oct 08, 2024



The text-to-video (T2V) generation models, offering convenient visual creation, have recently garnered increasing attention. Despite their substantial potential, the generated videos may present artifacts, including structural implausibility, temporal inconsistency, and a lack of motion, often resulting in near-static video. In this work, we have identified a correlation between the disparity of temporal attention maps across different blocks and the occurrence of temporal inconsistencies. Additionally, we have observed that the energy contained within the temporal attention maps is directly related to the magnitude of motion amplitude in the generated videos. Based on these observations, we present BroadWay, a training-free method to improve the quality of text-to-video generation without introducing additional parameters, augmenting memory or sampling time. Specifically, BroadWay is composed of two principal components: 1) Temporal Self-Guidance improves the structural plausibility and temporal consistency of generated videos by reducing the disparity between the temporal attention maps across various decoder blocks. 2) Fourier-based Motion Enhancement enhances the magnitude and richness of motion by amplifying the energy of the map. Extensive experiments demonstrate that BroadWay significantly improves the quality of text-to-video generation with negligible additional cost.