 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePave-GRPO: Beyond Instantaneous Guidance through Principled Average Velocity Decomposition
Jun 01, 2026Post-training via Group Relative Policy Optimization (GRPO) has emerged as a powerful paradigm for aligning flow-based generative models with human preferences. However, the iterative denoising nature of flow models incurs substantial costs when generating group rollouts for policy-gradient updates, compelling existing methods to train with extremely few denoising steps. This temporal sparsity severely restricts preference optimization: reward feedback can only reach a handful of stages per trajectory, leaving the vast majority of intermediate denoising steps without direct supervision and thus compromising alignment granularity. To address this, we propose Pave-GRPO, which reformulates the GRPO objective through Principled average velocity decomposition. Rather than generating expensive high-step rollouts, we maintain efficient few-step group sampling but decompose each coarse transition into an equivalent ensemble of finer sub-trajectories spanning multiple intermediate timesteps. This propagates reward feedback to a denser set of temporal stages for more comprehensive preference alignment without additional generation cost. This design offers two benefits: (i) zero-cost horizon expansion: through the direct reuse of piece-wise group samples and their associated rewards, Pave-GRPO significantly broadens the effective optimization scope under fixed sampling budgets; and (ii) comprehensive temporal supervision: by equivalently decomposing an instantaneous velocity target into a multi-timestep ensemble, it distributes reward signals across more intermediate stages of the denoising process, enabling finer-grained and more thorough preference optimization. Extensive experiments validate that Pave-GRPO effectively advances preference alignment across different reward settings, offering comprehensive performance enhancement.
AsyncTool: Evaluating the Asynchronous Function Calling Capability under Multi-Task Scenarios
May 28, 2026Large language model (LLM)-based agents have shown strong capabilities in using external tools to solve complex tasks. However, existing evaluations often overlook the temporal dimension of tool use, especially the impact of tool response latency, and are usually limited to single-task settings. In real-world applications, multiple tasks often need to be executed concurrently, and overall efficiency depends on whether an agent can use idle time while waiting for tool responses. We refer to this capability as asynchronous tool calling. To evaluate it, we propose AsyncTool, a benchmark for assessing LLM-based agents in interactive multi-task tool-use environments with delayed tool feedback. AsyncTool presents multiple heterogeneous tasks simultaneously and simulates realistic tool response latency during execution. Using a hybrid data evolution strategy, we construct a diverse asynchronous multitasking dataset that covers multiple scenarios and tool-use patterns. We evaluate models at the step, sub-task, and task levels, and introduce efficiency-oriented metrics to measure task coordination and completion efficiency. Extensive experiments show that delayed tool feedback poses substantial challenges to current agents and leads to clear performance degradation. Models that better coordinate task switching, dependency tracking, and state maintenance achieve stronger performance on AsyncTool. Our analysis identifies key failure modes of current tool-using agents and provides practical insights for designing future systems with stronger temporal reasoning and coordination capabilities.
HQ-CLIP: Leveraging Large Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models
Jul 30, 2025Large-scale but noisy image-text pair data have paved the way for the success of Contrastive Language-Image Pretraining (CLIP). As the foundation vision encoder, CLIP in turn serves as the cornerstone for most large vision-language models (LVLMs). This interdependence naturally raises an interesting question: Can we reciprocally leverage LVLMs to enhance the quality of image-text pair data, thereby opening the possibility of a self-reinforcing cycle for continuous improvement? In this work, we take a significant step toward this vision by introducing an LVLM-driven data refinement pipeline. Our framework leverages LVLMs to process images and their raw alt-text, generating four complementary textual formulas: long positive descriptions, long negative descriptions, short positive tags, and short negative tags. Applying this pipeline to the curated DFN-Large dataset yields VLM-150M, a refined dataset enriched with multi-grained annotations. Based on this dataset, we further propose a training paradigm that extends conventional contrastive learning by incorporating negative descriptions and short tags as additional supervised signals. The resulting model, namely HQ-CLIP, demonstrates remarkable improvements across diverse benchmarks. Within a comparable training data scale, our approach achieves state-of-the-art performance in zero-shot classification, cross-modal retrieval, and fine-grained visual understanding tasks. In retrieval benchmarks, HQ-CLIP even surpasses standard CLIP models trained on the DFN-2B dataset, which contains 10$\times$ more training data than ours. All code, data, and models are available at https://zxwei.site/hqclip.
Integral Fast Fourier Color Constancy
Feb 05, 2025
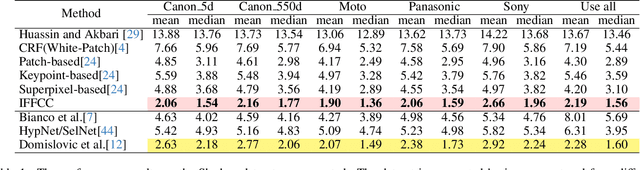
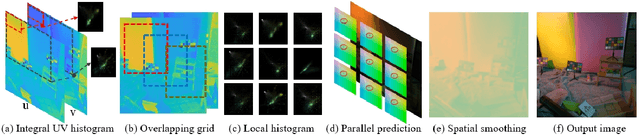

Traditional auto white balance (AWB) algorithms typically assume a single global illuminant source, which leads to color distortions in multi-illuminant scenes. While recent neural network-based methods have shown excellent accuracy in such scenarios, their high parameter count and computational demands limit their practicality for real-time video applications. The Fast Fourier Color Constancy (FFCC) algorithm was proposed for single-illuminant-source scenes, predicting a global illuminant source with high efficiency. However, it cannot be directly applied to multi-illuminant scenarios unless specifically modified. To address this, we propose Integral Fast Fourier Color Constancy (IFFCC), an extension of FFCC tailored for multi-illuminant scenes. IFFCC leverages the proposed integral UV histogram to accelerate histogram computations across all possible regions in Cartesian space and parallelizes Fourier-based convolution operations, resulting in a spatially-smooth illumination map. This approach enables high-accuracy, real-time AWB in multi-illuminant scenes. Extensive experiments show that IFFCC achieves accuracy that is on par with or surpasses that of pixel-level neural networks, while reducing the parameter count by over $400\times$ and processing speed by 20 - $100\times$ faster than network-based approaches.
Single Image Dehazing Using Scene Depth Ordering
Aug 11, 2024



Images captured in hazy weather generally suffer from quality degradation, and many dehazing methods have been developed to solve this problem. However, single image dehazing problem is still challenging due to its ill-posed nature. In this paper, we propose a depth order guided single image dehazing method, which utilizes depth order in hazy images to guide the dehazing process to achieve a similar depth perception in corresponding dehazing results. The consistency of depth perception ensures that the regions that look farther or closer in hazy images also appear farther or closer in the corresponding dehazing results, and thus effectively avoid the undesired visual effects. To achieve this goal, a simple yet effective strategy is proposed to extract the depth order in hazy images, which offers a reference for depth perception in hazy weather. Additionally, a depth order embedded transformation model is devised, which performs transmission estimation under the guidance of depth order to realize an unchanged depth order in the dehazing results. The extracted depth order provides a powerful global constraint for the dehazing process, which contributes to the efficient utilization of global information, thereby bringing an overall improvement in restoration quality. Extensive experiments demonstrate that the proposed method can better recover potential structure and vivid color with higher computational efficiency than the state-of-the-art dehazing methods.
STAR: Scale-wise Text-to-image generation via Auto-Regressive representations
Jun 16, 2024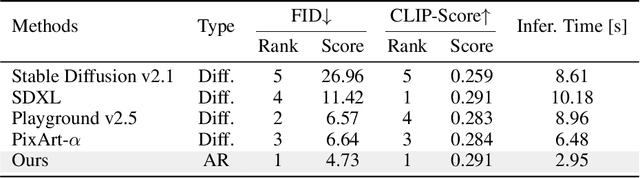
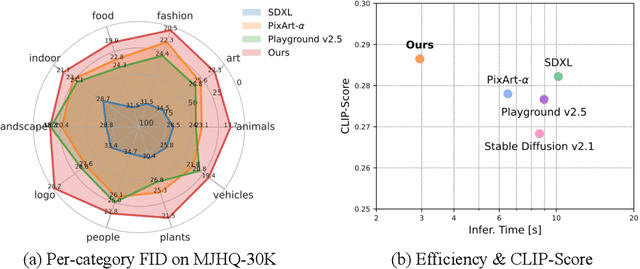
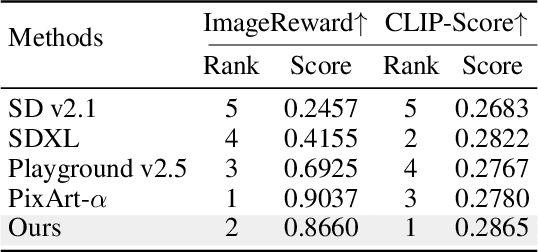
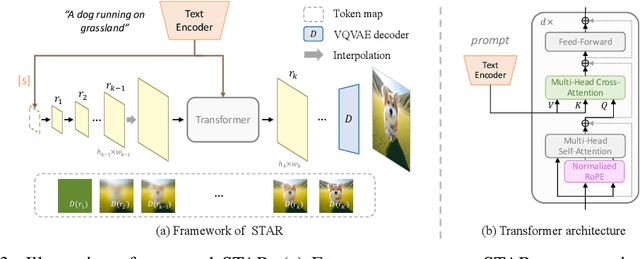
We present STAR, a text-to-image model that employs scale-wise auto-regressive paradigm. Unlike VAR, which is limited to class-conditioned synthesis within a fixed set of predetermined categories, our STAR enables text-driven open-set generation through three key designs: To boost diversity and generalizability with unseen combinations of objects and concepts, we introduce a pre-trained text encoder to extract representations for textual constraints, which we then use as guidance. To improve the interactions between generated images and fine-grained textual guidance, making results more controllable, additional cross-attention layers are incorporated at each scale. Given the natural structure correlation across different scales, we leverage 2D Rotary Positional Encoding (RoPE) and tweak it into a normalized version. This ensures consistent interpretation of relative positions across token maps at different scales and stabilizes the training process. Extensive experiments demonstrate that STAR surpasses existing benchmarks in terms of fidelity,image text consistency, and aesthetic quality. Our findings emphasize the potential of auto-regressive methods in the field of high-quality image synthesis, offering promising new directions for the T2I field currently dominated by diffusion methods.
MotionClone: Training-Free Motion Cloning for Controllable Video Generation
Jun 12, 2024



Motion-based controllable text-to-video generation involves motions to control the video generation. Previous methods typically require the training of models to encode motion cues or the fine-tuning of video diffusion models. However, these approaches often result in suboptimal motion generation when applied outside the trained domain. In this work, we propose MotionClone, a training-free framework that enables motion cloning from a reference video to control text-to-video generation. We employ temporal attention in video inversion to represent the motions in the reference video and introduce primary temporal-attention guidance to mitigate the influence of noisy or very subtle motions within the attention weights. Furthermore, to assist the generation model in synthesizing reasonable spatial relationships and enhance its prompt-following capability, we propose a location-aware semantic guidance mechanism that leverages the coarse location of the foreground from the reference video and original classifier-free guidance features to guide the video generation. Extensive experiments demonstrate that MotionClone exhibits proficiency in both global camera motion and local object motion, with notable superiority in terms of motion fidelity, textual alignment, and temporal consistency.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024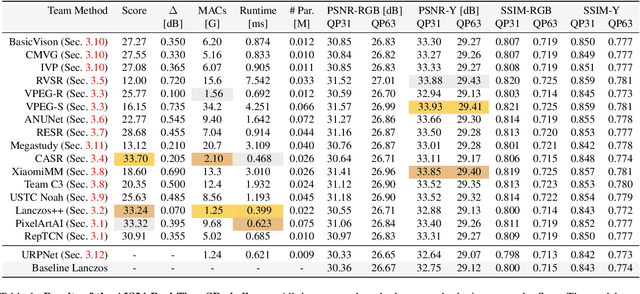
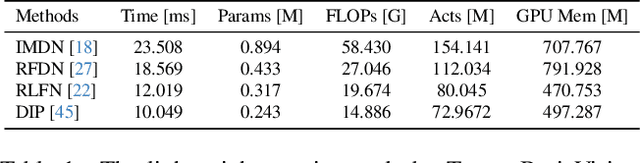
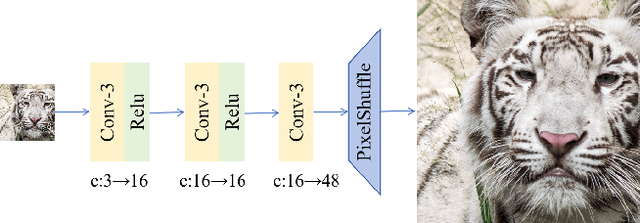
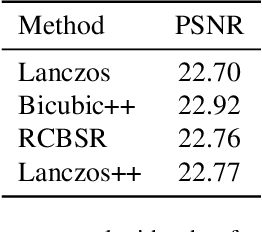
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Seed Optimization with Frozen Generator for Superior Zero-shot Low-light Enhancement
Feb 15, 2024



In this work, we observe that the generators, which are pre-trained on massive natural images, inherently hold the promising potential for superior low-light image enhancement against varying scenarios.Specifically, we embed a pre-trained generator to Retinex model to produce reflectance maps with enhanced detail and vividness, thereby recovering features degraded by low-light conditions.Taking one step further, we introduce a novel optimization strategy, which backpropagates the gradients to the input seeds rather than the parameters of the low-light enhancement model, thus intactly retaining the generative knowledge learned from natural images and achieving faster convergence speed. Benefiting from the pre-trained knowledge and seed-optimization strategy, the low-light enhancement model can significantly regularize the realness and fidelity of the enhanced result, thus rapidly generating high-quality images without training on any low-light dataset. Extensive experiments on various benchmarks demonstrate the superiority of the proposed method over numerous state-of-the-art methods qualitatively and quantitatively.
Masked Pre-trained Model Enables Universal Zero-shot Denoiser
Jan 26, 2024In this work, we observe that the model, which is trained on vast general images using masking strategy, has been naturally embedded with the distribution knowledge regarding natural images, and thus spontaneously attains the underlying potential for strong image denoising. Based on this observation, we propose a novel zero-shot denoising paradigm, i.e., Masked Pre-train then Iterative fill (MPI). MPI pre-trains a model with masking and fine-tunes it for denoising of a single image with unseen noise degradation. Concretely, the proposed MPI comprises two key procedures: 1) Masked Pre-training involves training a model on multiple natural images with random masks to gather generalizable representations, allowing for practical applications in varying noise degradation and even in distinct image types. 2) Iterative filling is devised to efficiently fuse pre-trained knowledge for denoising. Similar to but distinct from pre-training, random masking is retained to bridge the gap, but only the predicted parts covered by masks are assembled for efficiency, which enables high-quality denoising within a limited number of iterations. Comprehensive experiments across various noisy scenarios underscore the notable advances of proposed MPI over previous approaches with a marked reduction in inference time. Code is available at https://github.com/krennic999/MPI.git.