 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiao: Bridging Isolation and Customization in Mixed Criticality Robotics
May 05, 2026Consumer robotics demands consolidation of safety-critical control, perception pipelines, and user applications on shared multicore platforms. While static partitioning hypervisors provide hardware-enforced isolation, directly transplanting automotive architectures encounters an expertise asymmetry problem in which end-users modifying robot behavior lack the systems knowledge that platform developers possess. We present an architecture addressing this challenge through three integrated components. A Safe IO Cell provides hardware-level override capability. A Parameter Synchronization Service encapsulates cross-domain complexity. A Safety Communication Layer implements IEC~61508-aligned verification. Our empirical evaluation on an ARM Cortex-A55 platform demonstrates that partition isolation reduces cycle-period jitter by 84.5\% and cuts tail timing error by nearly an order of magnitude (p99 $|$jitter$|$ from 69.0\,$μ$s to 7.8\,$μ$s), eliminating all $>$50\,$μ$s~excursions.
ActFER: Agentic Facial Expression Recognition via Active Tool-Augmented Visual Reasoning
Apr 10, 2026Recent advances in Multimodal Large Language Models (MLLMs) have created new opportunities for facial expression recognition (FER), moving it beyond pure label prediction toward reasoning-based affect understanding. However, existing MLLM-based FER methods still follow a passive paradigm: they rely on externally prepared facial inputs and perform single-pass reasoning over fixed visual evidence, without the capability for active facial perception. To address this limitation, we propose ActFER, an agentic framework that reformulates FER as active visual evidence acquisition followed by multimodal reasoning. Specifically, ActFER dynamically invokes tools for face detection and alignment, selectively zooms into informative local regions, and reasons over facial Action Units (AUs) and emotions through a visual Chain-of-Thought. To realize such behavior, we further develop Utility-Calibrated GRPO (UC-GRPO), a reinforcement learning algorithm tailored to agentic FER. UC-GRPO uses AU-grounded multi-level verifiable rewards to densify supervision, query-conditional contrastive utility estimation to enable sample-aware dynamic credit assignment for local inspection, and emotion-aware EMA calibration to reduce noisy utility estimates while capturing emotion-wise inspection tendencies. This algorithm enables ActFER to learn both when local inspection is beneficial and how to reason over the acquired evidence. Comprehensive experiments show that ActFER trained with UC-GRPO consistently outperforms passive MLLM-based FER baselines and substantially improves AU prediction accuracy.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
EGSS: Entropy-guided Stepwise Scaling for Reliable Software Engineering
Feb 05, 2026Agentic Test-Time Scaling (TTS) has delivered state-of-the-art (SOTA) performance on complex software engineering tasks such as code generation and bug fixing. However, its practical adoption remains limited due to significant computational overhead, primarily driven by two key challenges: (1) the high cost associated with deploying excessively large ensembles, and (2) the lack of a reliable mechanism for selecting the optimal candidate solution, ultimately constraining the performance gains that can be realized. To address these challenges, we propose Entropy-Guided Stepwise Scaling (EGSS), a novel TTS framework that dynamically balances efficiency and effectiveness through entropy-guided adaptive search and robust test-suite augmentation. Extensive experiments on SWE-Bench-Verified demonstrate that EGSS consistently boosts performance by 5-10% across all evaluated models. Specifically, it increases the resolved ratio of Kimi-K2-Intruct from 63.2% to 72.2%, and GLM-4.6 from 65.8% to 74.6%. Furthermore, when paired with GLM-4.6, EGSS achieves a new state-of-the-art among open-source large language models. In addition to these accuracy improvements, EGSS reduces inference-time token usage by over 28% compared to existing TTS methods, achieving simultaneous gains in both effectiveness and computational efficiency.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
BuddyMoE: Exploiting Expert Redundancy to Accelerate Memory-Constrained Mixture-of-Experts Inference
Nov 13, 2025



Mixture-of-Experts (MoE) architectures scale language models by activating only a subset of specialized expert networks for each input token, thereby reducing the number of floating-point operations. However, the growing size of modern MoE models causes their full parameter sets to exceed GPU memory capacity; for example, Mixtral-8x7B has 45 billion parameters and requires 87 GB of memory even though only 14 billion parameters are used per token. Existing systems alleviate this limitation by offloading inactive experts to CPU memory, but transferring experts across the PCIe interconnect incurs significant latency (about 10 ms). Prefetching heuristics aim to hide this latency by predicting which experts are needed, but prefetch failures introduce significant stalls and amplify inference latency. In the event of a prefetch failure, prior work offers two primary solutions: either fetch the expert on demand, which incurs a long stall due to the PCIe bottleneck, or drop the expert from the computation, which significantly degrades model accuracy. The critical challenge, therefore, is to maintain both high inference speed and model accuracy when prefetching fails.
HQ-CLIP: Leveraging Large Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models
Jul 30, 2025Large-scale but noisy image-text pair data have paved the way for the success of Contrastive Language-Image Pretraining (CLIP). As the foundation vision encoder, CLIP in turn serves as the cornerstone for most large vision-language models (LVLMs). This interdependence naturally raises an interesting question: Can we reciprocally leverage LVLMs to enhance the quality of image-text pair data, thereby opening the possibility of a self-reinforcing cycle for continuous improvement? In this work, we take a significant step toward this vision by introducing an LVLM-driven data refinement pipeline. Our framework leverages LVLMs to process images and their raw alt-text, generating four complementary textual formulas: long positive descriptions, long negative descriptions, short positive tags, and short negative tags. Applying this pipeline to the curated DFN-Large dataset yields VLM-150M, a refined dataset enriched with multi-grained annotations. Based on this dataset, we further propose a training paradigm that extends conventional contrastive learning by incorporating negative descriptions and short tags as additional supervised signals. The resulting model, namely HQ-CLIP, demonstrates remarkable improvements across diverse benchmarks. Within a comparable training data scale, our approach achieves state-of-the-art performance in zero-shot classification, cross-modal retrieval, and fine-grained visual understanding tasks. In retrieval benchmarks, HQ-CLIP even surpasses standard CLIP models trained on the DFN-2B dataset, which contains 10$\times$ more training data than ours. All code, data, and models are available at https://zxwei.site/hqclip.
Phantom: Constraining Generative Artificial Intelligence Models for Practical Domain Specific Peripherals Trace Synthesizing
Nov 10, 2024

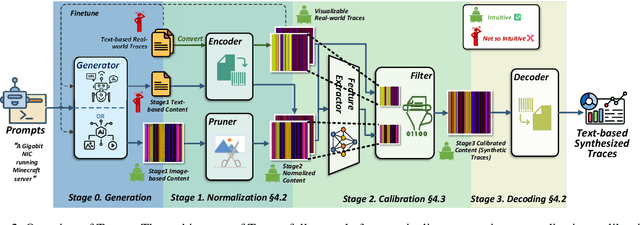

Peripheral Component Interconnect Express (PCIe) is the de facto interconnect standard for high-speed peripherals and CPUs. Prototyping and optimizing PCIe devices for emerging scenarios is an ongoing challenge. Since Transaction Layer Packets (TLPs) capture device-CPU interactions, it is crucial to analyze and generate realistic TLP traces for effective device design and optimization. Generative AI offers a promising approach for creating intricate, custom TLP traces necessary for PCIe hardware and software development. However, existing models often generate impractical traces due to the absence of PCIe-specific constraints, such as TLP ordering and causality. This paper presents Phantom, the first framework that treats TLP trace generation as a generative AI problem while incorporating PCIe-specific constraints. We validate Phantom's effectiveness by generating TLP traces for an actual PCIe network interface card. Experimental results show that Phantom produces practical, large-scale TLP traces, significantly outperforming existing models, with improvements of up to 1000$\times$ in task-specific metrics and up to 2.19$\times$ in Frechet Inception Distance (FID) compared to backbone-only methods.
CrossEarth: Geospatial Vision Foundation Model for Domain Generalizable Remote Sensing Semantic Segmentation
Oct 31, 2024


The field of Remote Sensing Domain Generalization (RSDG) has emerged as a critical and valuable research frontier, focusing on developing models that generalize effectively across diverse scenarios. Despite the substantial domain gaps in RS images that are characterized by variabilities such as location, wavelength, and sensor type, research in this area remains underexplored: (1) Current cross-domain methods primarily focus on Domain Adaptation (DA), which adapts models to predefined domains rather than to unseen ones; (2) Few studies targeting the RSDG issue, especially for semantic segmentation tasks, where existing models are developed for specific unknown domains, struggling with issues of underfitting on other unknown scenarios; (3) Existing RS foundation models tend to prioritize in-domain performance over cross-domain generalization. To this end, we introduce the first vision foundation model for RSDG semantic segmentation, CrossEarth. CrossEarth demonstrates strong cross-domain generalization through a specially designed data-level Earth-Style Injection pipeline and a model-level Multi-Task Training pipeline. In addition, for the semantic segmentation task, we have curated an RSDG benchmark comprising 28 cross-domain settings across various regions, spectral bands, platforms, and climates, providing a comprehensive framework for testing the generalizability of future RSDG models. Extensive experiments on this benchmark demonstrate the superiority of CrossEarth over existing state-of-the-art methods.
Seed Optimization with Frozen Generator for Superior Zero-shot Low-light Enhancement
Feb 15, 2024



In this work, we observe that the generators, which are pre-trained on massive natural images, inherently hold the promising potential for superior low-light image enhancement against varying scenarios.Specifically, we embed a pre-trained generator to Retinex model to produce reflectance maps with enhanced detail and vividness, thereby recovering features degraded by low-light conditions.Taking one step further, we introduce a novel optimization strategy, which backpropagates the gradients to the input seeds rather than the parameters of the low-light enhancement model, thus intactly retaining the generative knowledge learned from natural images and achieving faster convergence speed. Benefiting from the pre-trained knowledge and seed-optimization strategy, the low-light enhancement model can significantly regularize the realness and fidelity of the enhanced result, thus rapidly generating high-quality images without training on any low-light dataset. Extensive experiments on various benchmarks demonstrate the superiority of the proposed method over numerous state-of-the-art methods qualitatively and quantitatively.