 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-View Object Correspondence via Cycle-Consistent Mask Prediction
Feb 22, 2026We study the task of establishing object-level visual correspondence across different viewpoints in videos, focusing on the challenging egocentric-to-exocentric and exocentric-to-egocentric scenarios. We propose a simple yet effective framework based on conditional binary segmentation, where an object query mask is encoded into a latent representation to guide the localization of the corresponding object in a target video. To encourage robust, view-invariant representations, we introduce a cycle-consistency training objective: the predicted mask in the target view is projected back to the source view to reconstruct the original query mask. This bidirectional constraint provides a strong self-supervisory signal without requiring ground-truth annotations and enables test-time training (TTT) at inference. Experiments on the Ego-Exo4D and HANDAL-X benchmarks demonstrate the effectiveness of our optimization objective and TTT strategy, achieving state-of-the-art performance. The code is available at https://github.com/shannany0606/CCMP.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


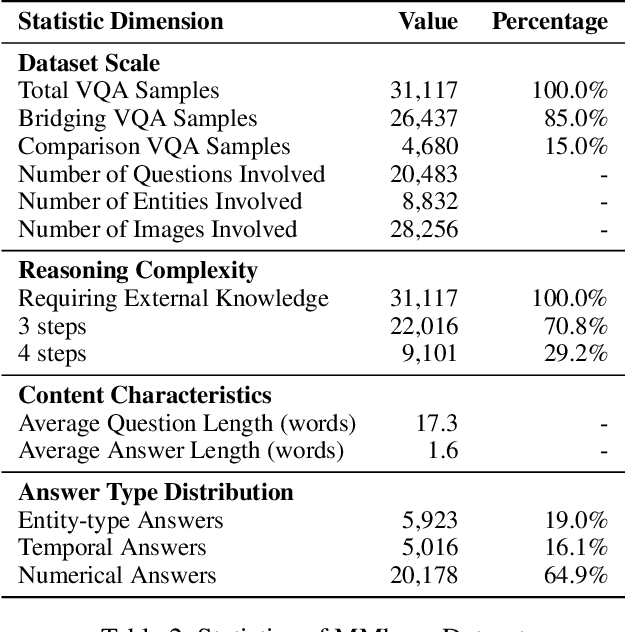
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
HQ-CLIP: Leveraging Large Vision-Language Models to Create High-Quality Image-Text Datasets and CLIP Models
Jul 30, 2025Large-scale but noisy image-text pair data have paved the way for the success of Contrastive Language-Image Pretraining (CLIP). As the foundation vision encoder, CLIP in turn serves as the cornerstone for most large vision-language models (LVLMs). This interdependence naturally raises an interesting question: Can we reciprocally leverage LVLMs to enhance the quality of image-text pair data, thereby opening the possibility of a self-reinforcing cycle for continuous improvement? In this work, we take a significant step toward this vision by introducing an LVLM-driven data refinement pipeline. Our framework leverages LVLMs to process images and their raw alt-text, generating four complementary textual formulas: long positive descriptions, long negative descriptions, short positive tags, and short negative tags. Applying this pipeline to the curated DFN-Large dataset yields VLM-150M, a refined dataset enriched with multi-grained annotations. Based on this dataset, we further propose a training paradigm that extends conventional contrastive learning by incorporating negative descriptions and short tags as additional supervised signals. The resulting model, namely HQ-CLIP, demonstrates remarkable improvements across diverse benchmarks. Within a comparable training data scale, our approach achieves state-of-the-art performance in zero-shot classification, cross-modal retrieval, and fine-grained visual understanding tasks. In retrieval benchmarks, HQ-CLIP even surpasses standard CLIP models trained on the DFN-2B dataset, which contains 10$\times$ more training data than ours. All code, data, and models are available at https://zxwei.site/hqclip.
Visual Perception by Large Language Model's Weights
May 30, 2024



Existing Multimodal Large Language Models (MLLMs) follow the paradigm that perceives visual information by aligning visual features with the input space of Large Language Models (LLMs), and concatenating visual tokens with text tokens to form a unified sequence input for LLMs. These methods demonstrate promising results on various vision-language tasks but are limited by the high computational effort due to the extended input sequence resulting from the involvement of visual tokens. In this paper, instead of input space alignment, we propose a novel parameter space alignment paradigm that represents visual information as model weights. For each input image, we use a vision encoder to extract visual features, convert features into perceptual weights, and merge the perceptual weights with LLM's weights. In this way, the input of LLM does not require visual tokens, which reduces the length of the input sequence and greatly improves efficiency. Following this paradigm, we propose VLoRA with the perceptual weights generator. The perceptual weights generator is designed to convert visual features to perceptual weights with low-rank property, exhibiting a form similar to LoRA. The experimental results show that our VLoRA achieves comparable performance on various benchmarks for MLLMs, while significantly reducing the computational costs for both training and inference. The code and models will be made open-source.
Multi-Modal Generative Embedding Model
May 29, 2024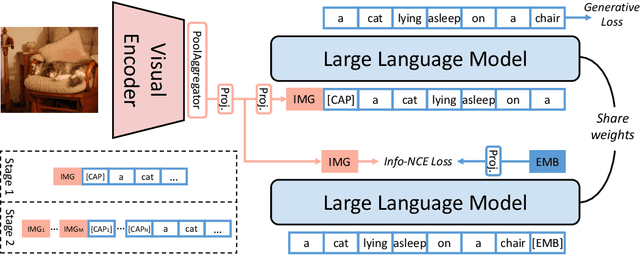



Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To explore the minimalism of multi-modal paradigms, we attempt to achieve only one model per modality in this work. We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. We also propose a PoolAggregator to boost efficiency and enable the ability of fine-grained embedding and generation. A surprising finding is that these two objectives do not significantly conflict with each other. For example, MM-GEM instantiated from ViT-Large and TinyLlama shows competitive performance on benchmarks for multimodal embedding models such as cross-modal retrieval and zero-shot classification, while has good ability of image captioning. Additionally, MM-GEM can seamlessly execute region-level image caption generation and retrieval tasks. Besides, the advanced text model in MM-GEM brings over 5% improvement in Recall@1 for long text and image retrieval.
Correlation-Aware Deep Tracking
Mar 03, 2022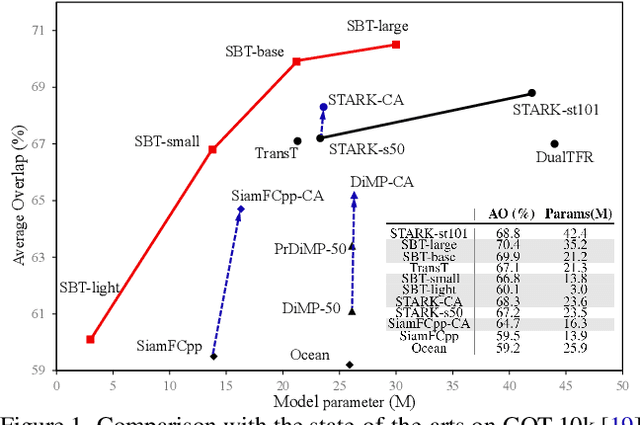

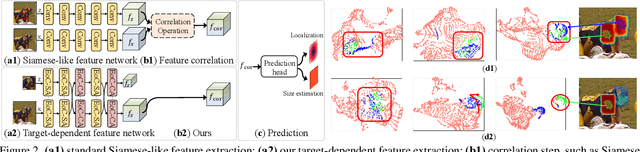
Robustness and discrimination power are two fundamental requirements in visual object tracking. In most tracking paradigms, we find that the features extracted by the popular Siamese-like networks cannot fully discriminatively model the tracked targets and distractor objects, hindering them from simultaneously meeting these two requirements. While most methods focus on designing robust correlation operations, we propose a novel target-dependent feature network inspired by the self-/cross-attention scheme. In contrast to the Siamese-like feature extraction, our network deeply embeds cross-image feature correlation in multiple layers of the feature network. By extensively matching the features of the two images through multiple layers, it is able to suppress non-target features, resulting in instance-varying feature extraction. The output features of the search image can be directly used for predicting target locations without extra correlation step. Moreover, our model can be flexibly pre-trained on abundant unpaired images, leading to notably faster convergence than the existing methods. Extensive experiments show our method achieves the state-of-the-art results while running at real-time. Our feature networks also can be applied to existing tracking pipelines seamlessly to raise the tracking performance. Code will be available.
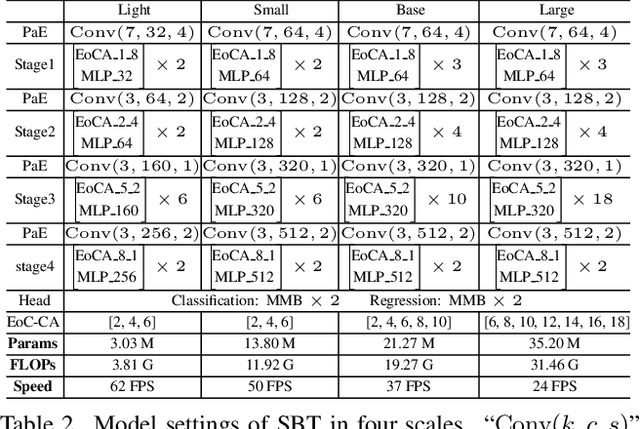
When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism
Jan 26, 2022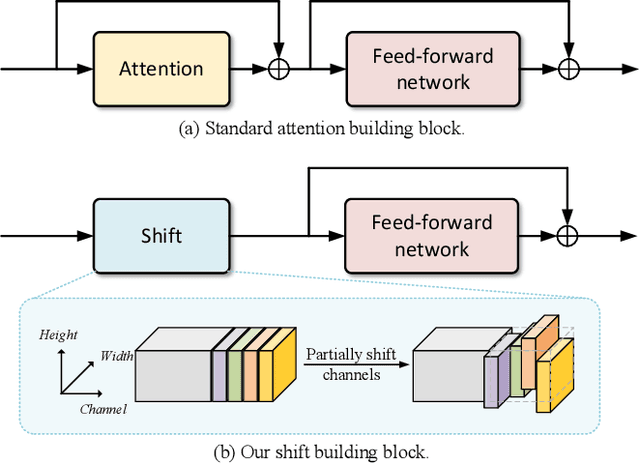
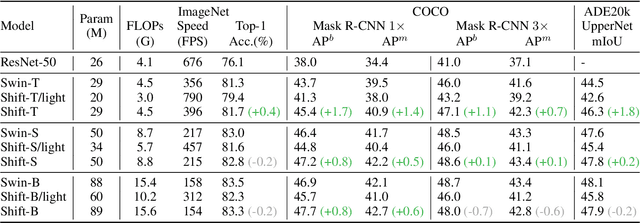
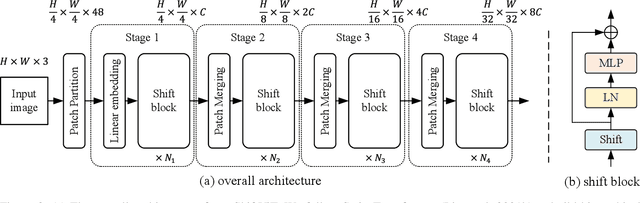
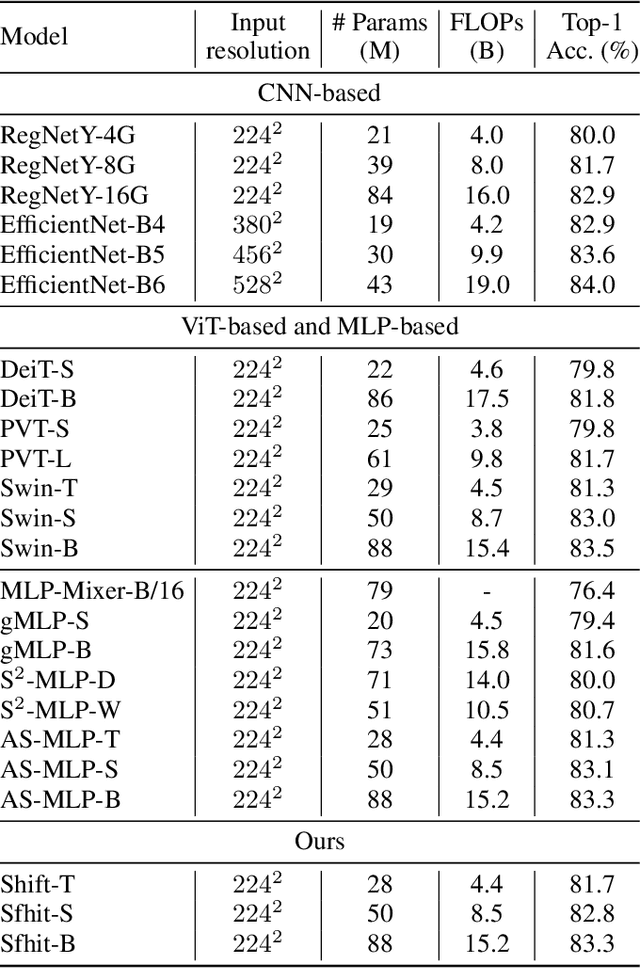
Attention mechanism has been widely believed as the key to success of vision transformers (ViTs), since it provides a flexible and powerful way to model spatial relationships. However, is the attention mechanism truly an indispensable part of ViT? Can it be replaced by some other alternatives? To demystify the role of attention mechanism, we simplify it into an extremely simple case: ZERO FLOP and ZERO parameter. Concretely, we revisit the shift operation. It does not contain any parameter or arithmetic calculation. The only operation is to exchange a small portion of the channels between neighboring features. Based on this simple operation, we construct a new backbone network, namely ShiftViT, where the attention layers in ViT are substituted by shift operations. Surprisingly, ShiftViT works quite well in several mainstream tasks, e.g., classification, detection, and segmentation. The performance is on par with or even better than the strong baseline Swin Transformer. These results suggest that the attention mechanism might not be the vital factor that makes ViT successful. It can be even replaced by a zero-parameter operation. We should pay more attentions to the remaining parts of ViT in the future work. Code is available at github.com/microsoft/SPACH.
Learning Tracking Representations via Dual-Branch Fully Transformer Networks
Dec 05, 2021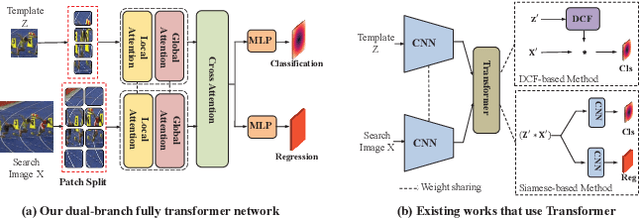

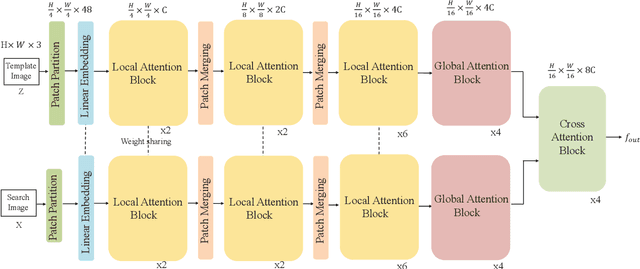
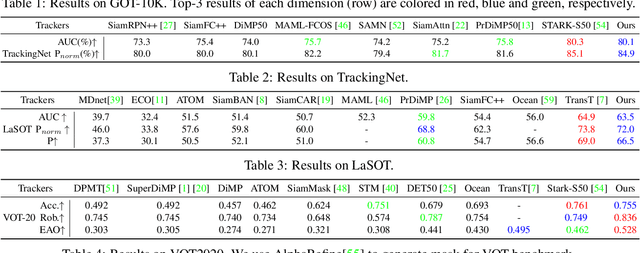
We present a Siamese-like Dual-branch network based on solely Transformers for tracking. Given a template and a search image, we divide them into non-overlapping patches and extract a feature vector for each patch based on its matching results with others within an attention window. For each token, we estimate whether it contains the target object and the corresponding size. The advantage of the approach is that the features are learned from matching, and ultimately, for matching. So the features are aligned with the object tracking task. The method achieves better or comparable results as the best-performing methods which first use CNN to extract features and then use Transformer to fuse them. It outperforms the state-of-the-art methods on the GOT-10k and VOT2020 benchmarks. In addition, the method achieves real-time inference speed (about $40$ fps) on one GPU. The code and models will be released.
Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?
Sep 12, 2021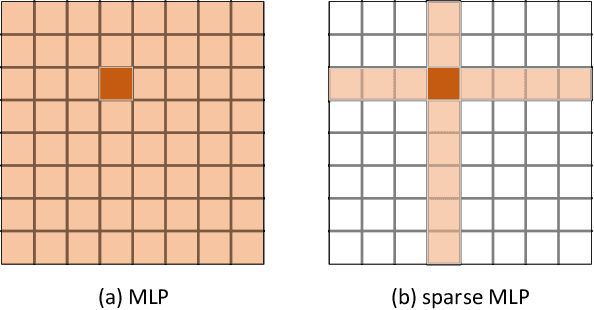

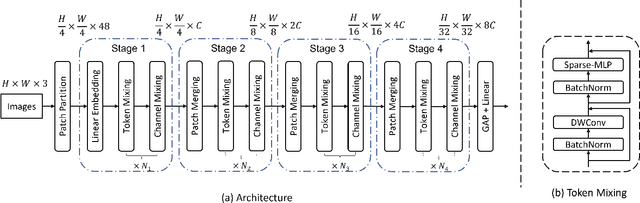
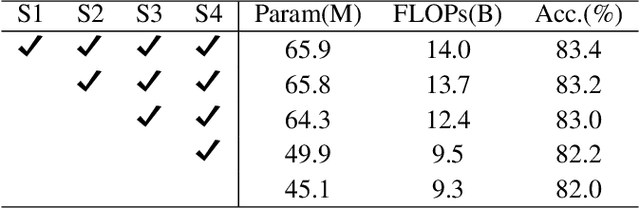
Transformers have sprung up in the field of computer vision. In this work, we explore whether the core self-attention module in Transformer is the key to achieving excellent performance in image recognition. To this end, we build an attention-free network called sMLPNet based on the existing MLP-based vision models. Specifically, we replace the MLP module in the token-mixing step with a novel sparse MLP (sMLP) module. For 2D image tokens, sMLP applies 1D MLP along the axial directions and the parameters are shared among rows or columns. By sparse connection and weight sharing, sMLP module significantly reduces the number of model parameters and computational complexity, avoiding the common over-fitting problem that plagues the performance of MLP-like models. When only trained on the ImageNet-1K dataset, the proposed sMLPNet achieves 81.9% top-1 accuracy with only 24M parameters, which is much better than most CNNs and vision Transformers under the same model size constraint. When scaling up to 66M parameters, sMLPNet achieves 83.4% top-1 accuracy, which is on par with the state-of-the-art Swin Transformer. The success of sMLPNet suggests that the self-attention mechanism is not necessarily a silver bullet in computer vision. Code will be made publicly available.
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
Aug 30, 2021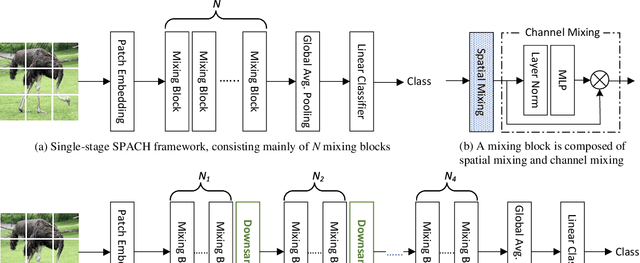
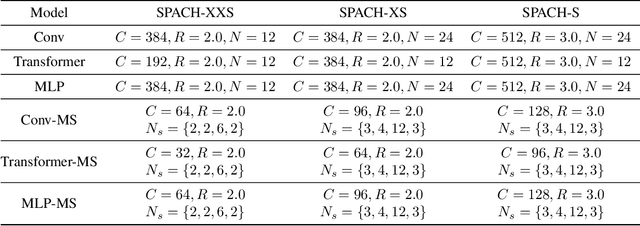
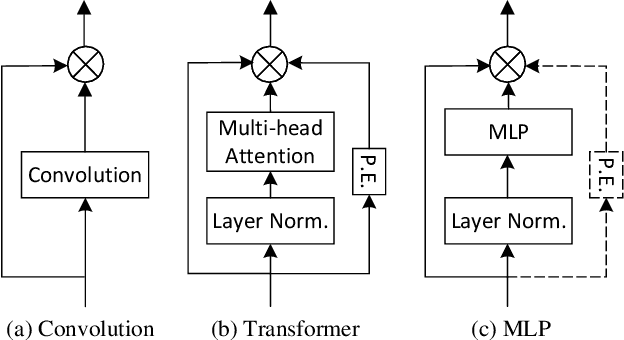

Convolutional neural networks (CNN) are the dominant deep neural network (DNN) architecture for computer vision. Recently, Transformer and multi-layer perceptron (MLP)-based models, such as Vision Transformer and MLP-Mixer, started to lead new trends as they showed promising results in the ImageNet classification task. In this paper, we conduct empirical studies on these DNN structures and try to understand their respective pros and cons. To ensure a fair comparison, we first develop a unified framework called SPACH which adopts separate modules for spatial and channel processing. Our experiments under the SPACH framework reveal that all structures can achieve competitive performance at a moderate scale. However, they demonstrate distinctive behaviors when the network size scales up. Based on our findings, we propose two hybrid models using convolution and Transformer modules. The resulting Hybrid-MS-S+ model achieves 83.9% top-1 accuracy with 63M parameters and 12.3G FLOPS. It is already on par with the SOTA models with sophisticated designs. The code and models will be made publicly available.