 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreate Anything Anywhere: Layout-Controllable Personalized Diffusion Model for Multiple Subjects
May 27, 2025Diffusion models have significantly advanced text-to-image generation, laying the foundation for the development of personalized generative frameworks. However, existing methods lack precise layout controllability and overlook the potential of dynamic features of reference subjects in improving fidelity. In this work, we propose Layout-Controllable Personalized Diffusion (LCP-Diffusion) model, a novel framework that integrates subject identity preservation with flexible layout guidance in a tuning-free approach. Our model employs a Dynamic-Static Complementary Visual Refining module to comprehensively capture the intricate details of reference subjects, and introduces a Dual Layout Control mechanism to enforce robust spatial control across both training and inference stages. Extensive experiments validate that LCP-Diffusion excels in both identity preservation and layout controllability. To the best of our knowledge, this is a pioneering work enabling users to "create anything anywhere".
EE-MLLM: A Data-Efficient and Compute-Efficient Multimodal Large Language Model
Aug 21, 2024



In the realm of multimodal research, numerous studies leverage substantial image-text pairs to conduct modal alignment learning, transforming Large Language Models (LLMs) into Multimodal LLMs and excelling in a variety of visual-language tasks. The prevailing methodologies primarily fall into two categories: self-attention-based and cross-attention-based methods. While self-attention-based methods offer superior data efficiency due to their simple MLP architecture, they often suffer from lower computational efficiency due to concatenating visual and textual tokens as input for LLM. Conversely, cross-attention-based methods, although less data-efficient due to additional learnable parameters, exhibit higher computational efficiency by avoiding long sequence input for LLM. To address these trade-offs, we introduce the Data-Efficient and Compute-Efficient Multimodal Large Language Model (EE-MLLM). Without introducing additional modules or learnable parameters, EE-MLLM achieves both data and compute efficiency. Specifically, we modify the original self-attention mechanism in MLLM to a composite attention mechanism. This mechanism has two key characteristics: 1) Eliminating the computational overhead of self-attention within visual tokens to achieve compute efficiency, and 2) Reusing the weights on each layer of LLM to facilitate effective modality alignment between vision and language for data efficiency. Experimental results demonstrate the effectiveness of EE-MLLM across a range of benchmarks, including general-purpose datasets like MMBench and SeedBench, as well as fine-grained tasks such as TextVQA and DocVQA.
Visual Perception by Large Language Model's Weights
May 30, 2024



Existing Multimodal Large Language Models (MLLMs) follow the paradigm that perceives visual information by aligning visual features with the input space of Large Language Models (LLMs), and concatenating visual tokens with text tokens to form a unified sequence input for LLMs. These methods demonstrate promising results on various vision-language tasks but are limited by the high computational effort due to the extended input sequence resulting from the involvement of visual tokens. In this paper, instead of input space alignment, we propose a novel parameter space alignment paradigm that represents visual information as model weights. For each input image, we use a vision encoder to extract visual features, convert features into perceptual weights, and merge the perceptual weights with LLM's weights. In this way, the input of LLM does not require visual tokens, which reduces the length of the input sequence and greatly improves efficiency. Following this paradigm, we propose VLoRA with the perceptual weights generator. The perceptual weights generator is designed to convert visual features to perceptual weights with low-rank property, exhibiting a form similar to LoRA. The experimental results show that our VLoRA achieves comparable performance on various benchmarks for MLLMs, while significantly reducing the computational costs for both training and inference. The code and models will be made open-source.
Multi-Modal Generative Embedding Model
May 29, 2024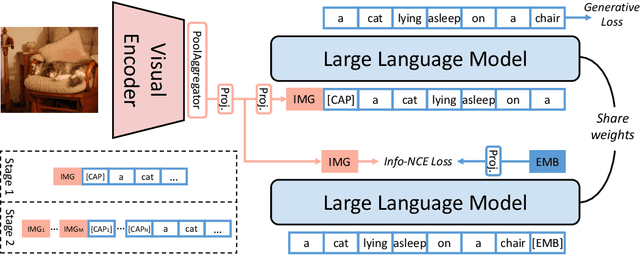



Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To explore the minimalism of multi-modal paradigms, we attempt to achieve only one model per modality in this work. We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. We also propose a PoolAggregator to boost efficiency and enable the ability of fine-grained embedding and generation. A surprising finding is that these two objectives do not significantly conflict with each other. For example, MM-GEM instantiated from ViT-Large and TinyLlama shows competitive performance on benchmarks for multimodal embedding models such as cross-modal retrieval and zero-shot classification, while has good ability of image captioning. Additionally, MM-GEM can seamlessly execute region-level image caption generation and retrieval tasks. Besides, the advanced text model in MM-GEM brings over 5% improvement in Recall@1 for long text and image retrieval.