 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiO-DETR: DETR for Real-time Oriented Object Detection
Mar 10, 2026We present RiO-DETR: DETR for Real-time Oriented Object Detection, the first real-time oriented detection transformer to the best of our knowledge. Adapting DETR to oriented bounding boxes (OBBs) poses three challenges: semantics-dependent orientation, angle periodicity that breaks standard Euclidean refinement, and an enlarged search space that slows convergence. RiO-DETR resolves these issues with task-native designs while preserving real-time efficiency. First, we propose Content-Driven Angle Estimation by decoupling angle from positional queries, together with Rotation-Rectified Orthogonal Attention to capture complementary cues for reliable orientation. Second, Decoupled Periodic Refinement combines bounded coarse-to-fine updates with a Shortest-Path Periodic Loss for stable learning across angular seams. Third, Oriented Dense O2O injects angular diversity into dense supervision to speed up angle convergence at no extra cost. Extensive experiments on DOTA-1.0, DIOR-R, and FAIR-1M-2.0 demonstrate RiO-DETR establishes a new speed--accuracy trade-off for real-time oriented detection. Code will be made publicly available.
AliTok: Towards Sequence Modeling Alignment between Tokenizer and Autoregressive Model
Jun 05, 2025Autoregressive image generation aims to predict the next token based on previous ones. However, existing image tokenizers encode tokens with bidirectional dependencies during the compression process, which hinders the effective modeling by autoregressive models. In this paper, we propose a novel Aligned Tokenizer (AliTok), which utilizes a causal decoder to establish unidirectional dependencies among encoded tokens, thereby aligning the token modeling approach between the tokenizer and autoregressive model. Furthermore, by incorporating prefix tokens and employing two-stage tokenizer training to enhance reconstruction consistency, AliTok achieves great reconstruction performance while being generation-friendly. On ImageNet-256 benchmark, using a standard decoder-only autoregressive model as the generator with only 177M parameters, AliTok achieves a gFID score of 1.50 and an IS of 305.9. When the parameter count is increased to 662M, AliTok achieves a gFID score of 1.35, surpassing the state-of-the-art diffusion method with 10x faster sampling speed. The code and weights are available at https://github.com/ali-vilab/alitok.
Create Anything Anywhere: Layout-Controllable Personalized Diffusion Model for Multiple Subjects
May 27, 2025Diffusion models have significantly advanced text-to-image generation, laying the foundation for the development of personalized generative frameworks. However, existing methods lack precise layout controllability and overlook the potential of dynamic features of reference subjects in improving fidelity. In this work, we propose Layout-Controllable Personalized Diffusion (LCP-Diffusion) model, a novel framework that integrates subject identity preservation with flexible layout guidance in a tuning-free approach. Our model employs a Dynamic-Static Complementary Visual Refining module to comprehensively capture the intricate details of reference subjects, and introduces a Dual Layout Control mechanism to enforce robust spatial control across both training and inference stages. Extensive experiments validate that LCP-Diffusion excels in both identity preservation and layout controllability. To the best of our knowledge, this is a pioneering work enabling users to "create anything anywhere".
Dome-DETR: DETR with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection
May 09, 2025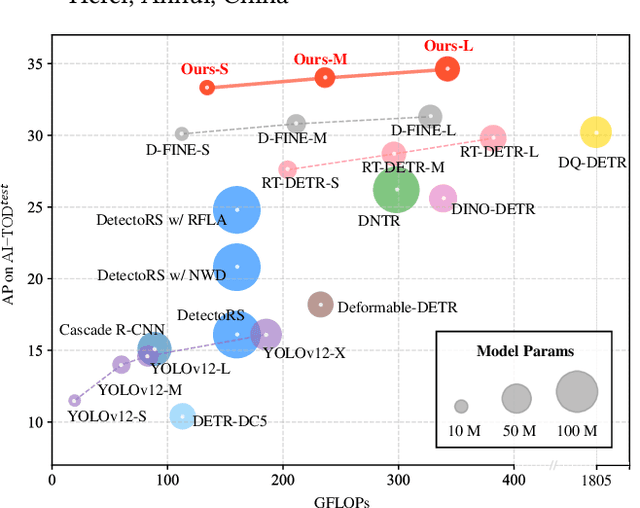
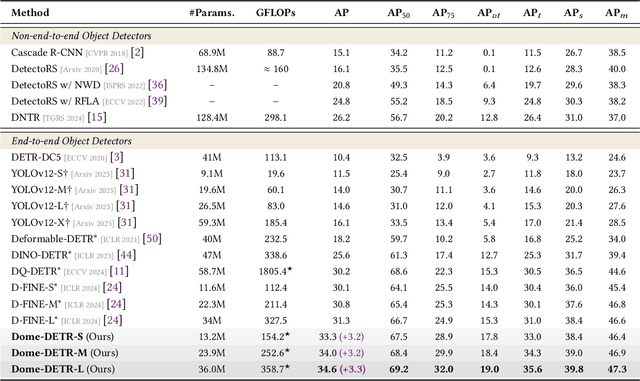
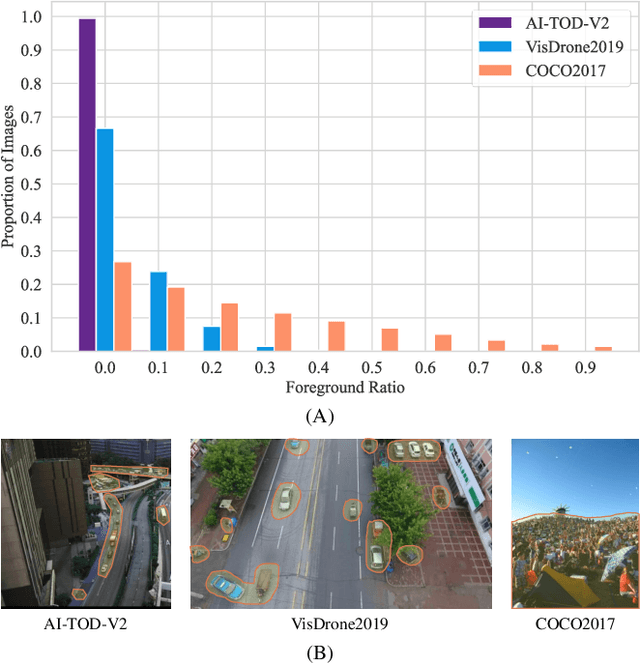
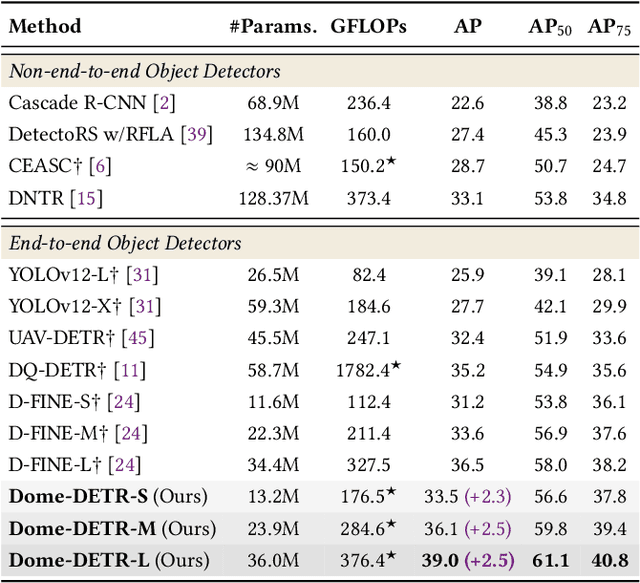
Tiny object detection plays a vital role in drone surveillance, remote sensing, and autonomous systems, enabling the identification of small targets across vast landscapes. However, existing methods suffer from inefficient feature leverage and high computational costs due to redundant feature processing and rigid query allocation. To address these challenges, we propose Dome-DETR, a novel framework with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection. To reduce feature redundancies, we introduce a lightweight Density-Focal Extractor (DeFE) to produce clustered compact foreground masks. Leveraging these masks, we incorporate Masked Window Attention Sparsification (MWAS) to focus computational resources on the most informative regions via sparse attention. Besides, we propose Progressive Adaptive Query Initialization (PAQI), which adaptively modulates query density across spatial areas for better query allocation. Extensive experiments demonstrate that Dome-DETR achieves state-of-the-art performance (+3.3 AP on AI-TOD-V2 and +2.5 AP on VisDrone) while maintaining low computational complexity and a compact model size. Code will be released upon acceptance.
Spiking Point Transformer for Point Cloud Classification
Feb 19, 2025Spiking Neural Networks (SNNs) offer an attractive and energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their sparse binary activation. When SNN meets Transformer, it shows great potential in 2D image processing. However, their application for 3D point cloud remains underexplored. To this end, we present Spiking Point Transformer (SPT), the first transformer-based SNN framework for point cloud classification. Specifically, we first design Queue-Driven Sampling Direct Encoding for point cloud to reduce computational costs while retaining the most effective support points at each time step. We introduce the Hybrid Dynamics Integrate-and-Fire Neuron (HD-IF), designed to simulate selective neuron activation and reduce over-reliance on specific artificial neurons. SPT attains state-of-the-art results on three benchmark datasets that span both real-world and synthetic datasets in the SNN domain. Meanwhile, the theoretical energy consumption of SPT is at least 6.4$\times$ less than its ANN counterpart.
D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
Oct 17, 2024



We introduce D-FINE, a powerful real-time object detector that achieves outstanding localization precision by redefining the bounding box regression task in DETR models. D-FINE comprises two key components: Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD). FDR transforms the regression process from predicting fixed coordinates to iteratively refining probability distributions, providing a fine-grained intermediate representation that significantly enhances localization accuracy. GO-LSD is a bidirectional optimization strategy that transfers localization knowledge from refined distributions to shallower layers through self-distillation, while also simplifying the residual prediction tasks for deeper layers. Additionally, D-FINE incorporates lightweight optimizations in computationally intensive modules and operations, achieving a better balance between speed and accuracy. Specifically, D-FINE-L / X achieves 54.0% / 55.8% AP on the COCO dataset at 124 / 78 FPS on an NVIDIA T4 GPU. When pretrained on Objects365, D-FINE-L / X attains 57.1% / 59.3% AP, surpassing all existing real-time detectors. Furthermore, our method significantly enhances the performance of a wide range of DETR models by up to 5.3% AP with negligible extra parameters and training costs. Our code and pretrained models: https://github.com/Peterande/D-FINE.
Scene Adaptive Sparse Transformer for Event-based Object Detection
Apr 02, 2024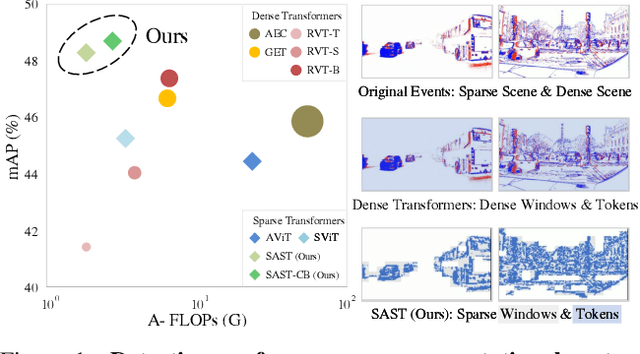
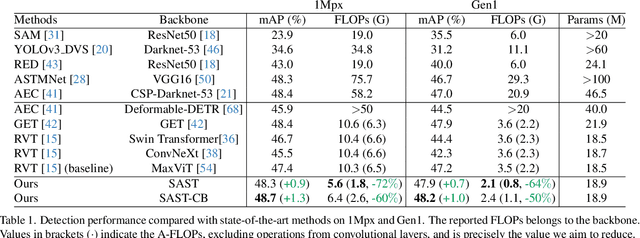
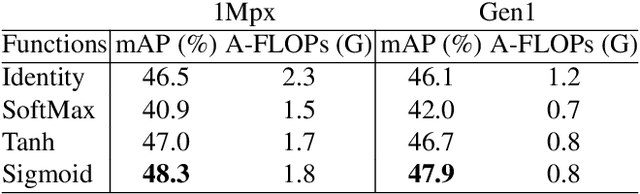
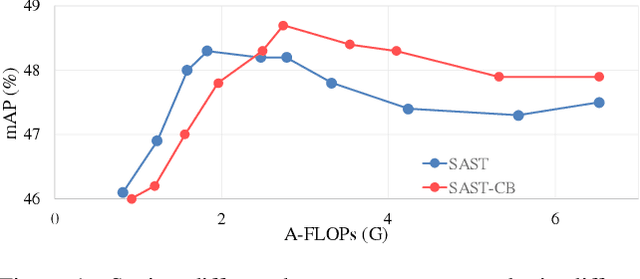
While recent Transformer-based approaches have shown impressive performances on event-based object detection tasks, their high computational costs still diminish the low power consumption advantage of event cameras. Image-based works attempt to reduce these costs by introducing sparse Transformers. However, they display inadequate sparsity and adaptability when applied to event-based object detection, since these approaches cannot balance the fine granularity of token-level sparsification and the efficiency of window-based Transformers, leading to reduced performance and efficiency. Furthermore, they lack scene-specific sparsity optimization, resulting in information loss and a lower recall rate. To overcome these limitations, we propose the Scene Adaptive Sparse Transformer (SAST). SAST enables window-token co-sparsification, significantly enhancing fault tolerance and reducing computational overhead. Leveraging the innovative scoring and selection modules, along with the Masked Sparse Window Self-Attention, SAST showcases remarkable scene-aware adaptability: It focuses only on important objects and dynamically optimizes sparsity level according to scene complexity, maintaining a remarkable balance between performance and computational cost. The evaluation results show that SAST outperforms all other dense and sparse networks in both performance and efficiency on two large-scale event-based object detection datasets (1Mpx and Gen1). Code: https://github.com/Peterande/SAST
Event-assisted Low-Light Video Object Segmentation
Apr 02, 2024In the realm of video object segmentation (VOS), the challenge of operating under low-light conditions persists, resulting in notably degraded image quality and compromised accuracy when comparing query and memory frames for similarity computation. Event cameras, characterized by their high dynamic range and ability to capture motion information of objects, offer promise in enhancing object visibility and aiding VOS methods under such low-light conditions. This paper introduces a pioneering framework tailored for low-light VOS, leveraging event camera data to elevate segmentation accuracy. Our approach hinges on two pivotal components: the Adaptive Cross-Modal Fusion (ACMF) module, aimed at extracting pertinent features while fusing image and event modalities to mitigate noise interference, and the Event-Guided Memory Matching (EGMM) module, designed to rectify the issue of inaccurate matching prevalent in low-light settings. Additionally, we present the creation of a synthetic LLE-DAVIS dataset and the curation of a real-world LLE-VOS dataset, encompassing frames and events. Experimental evaluations corroborate the efficacy of our method across both datasets, affirming its effectiveness in low-light scenarios.
GET: Group Event Transformer for Event-Based Vision
Oct 04, 2023



Event cameras are a type of novel neuromorphic sen-sor that has been gaining increasing attention. Existing event-based backbones mainly rely on image-based designs to extract spatial information within the image transformed from events, overlooking important event properties like time and polarity. To address this issue, we propose a novel Group-based vision Transformer backbone for Event-based vision, called Group Event Transformer (GET), which de-couples temporal-polarity information from spatial infor-mation throughout the feature extraction process. Specifi-cally, we first propose a new event representation for GET, named Group Token, which groups asynchronous events based on their timestamps and polarities. Then, GET ap-plies the Event Dual Self-Attention block, and Group Token Aggregation module to facilitate effective feature commu-nication and integration in both the spatial and temporal-polarity domains. After that, GET can be integrated with different downstream tasks by connecting it with vari-ous heads. We evaluate our method on four event-based classification datasets (Cifar10-DVS, N-MNIST, N-CARS, and DVS128Gesture) and two event-based object detection datasets (1Mpx and Gen1), and the results demonstrate that GET outperforms other state-of-the-art methods. The code is available at https://github.com/Peterande/GET-Group-Event-Transformer.