 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
Mar 17, 2026Large language model (LLM) agents increasingly rely on external memory to support long-horizon interaction, personalized assistance, and multi-step reasoning. However, existing memory systems still face three core challenges: they often rely too heavily on semantic similarity, which can miss evidence crucial for user-centric understanding; they frequently store related experiences as isolated fragments, weakening temporal and causal coherence; and they typically use static memory granularities that do not adapt well to the requirements of different questions. We propose AdaMem, an adaptive user-centric memory framework for long-horizon dialogue agents. AdaMem organizes dialogue history into working, episodic, persona, and graph memories, enabling the system to preserve recent context, structured long-term experiences, stable user traits, and relation-aware connections within a unified framework. At inference time, AdaMem first resolves the target participant, then builds a question-conditioned retrieval route that combines semantic retrieval with relation-aware graph expansion only when needed, and finally produces the answer through a role-specialized pipeline for evidence synthesis and response generation. We evaluate AdaMem on the LoCoMo and PERSONAMEM benchmarks for long-horizon reasoning and user modeling. Experimental results show that AdaMem achieves state-of-the-art performance on both benchmarks. The code will be released upon acceptance.
RiO-DETR: DETR for Real-time Oriented Object Detection
Mar 10, 2026We present RiO-DETR: DETR for Real-time Oriented Object Detection, the first real-time oriented detection transformer to the best of our knowledge. Adapting DETR to oriented bounding boxes (OBBs) poses three challenges: semantics-dependent orientation, angle periodicity that breaks standard Euclidean refinement, and an enlarged search space that slows convergence. RiO-DETR resolves these issues with task-native designs while preserving real-time efficiency. First, we propose Content-Driven Angle Estimation by decoupling angle from positional queries, together with Rotation-Rectified Orthogonal Attention to capture complementary cues for reliable orientation. Second, Decoupled Periodic Refinement combines bounded coarse-to-fine updates with a Shortest-Path Periodic Loss for stable learning across angular seams. Third, Oriented Dense O2O injects angular diversity into dense supervision to speed up angle convergence at no extra cost. Extensive experiments on DOTA-1.0, DIOR-R, and FAIR-1M-2.0 demonstrate RiO-DETR establishes a new speed--accuracy trade-off for real-time oriented detection. Code will be made publicly available.
SVL: Spike-based Vision-language Pretraining for Efficient 3D Open-world Understanding
May 23, 2025Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. However, existing SNNs still exhibit a significant performance gap compared to Artificial Neural Networks (ANNs) due to inadequate pre-training strategies. These limitations manifest as restricted generalization ability, task specificity, and a lack of multimodal understanding, particularly in challenging tasks such as multimodal question answering and zero-shot 3D classification. To overcome these challenges, we propose a Spike-based Vision-Language (SVL) pretraining framework that empowers SNNs with open-world 3D understanding while maintaining spike-driven efficiency. SVL introduces two key components: (i) Multi-scale Triple Alignment (MTA) for label-free triplet-based contrastive learning across 3D, image, and text modalities, and (ii) Re-parameterizable Vision-Language Integration (Rep-VLI) to enable lightweight inference without relying on large text encoders. Extensive experiments show that SVL achieves a top-1 accuracy of 85.4% in zero-shot 3D classification, surpassing advanced ANN models, and consistently outperforms prior SNNs on downstream tasks, including 3D classification (+6.1%), DVS action recognition (+2.1%), 3D detection (+1.1%), and 3D segmentation (+2.1%) with remarkable efficiency. Moreover, SVL enables SNNs to perform open-world 3D question answering, sometimes outperforming ANNs. To the best of our knowledge, SVL represents the first scalable, generalizable, and hardware-friendly paradigm for 3D open-world understanding, effectively bridging the gap between SNNs and ANNs in complex open-world understanding tasks. Code is available https://github.com/bollossom/SVL.
Dome-DETR: DETR with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection
May 09, 2025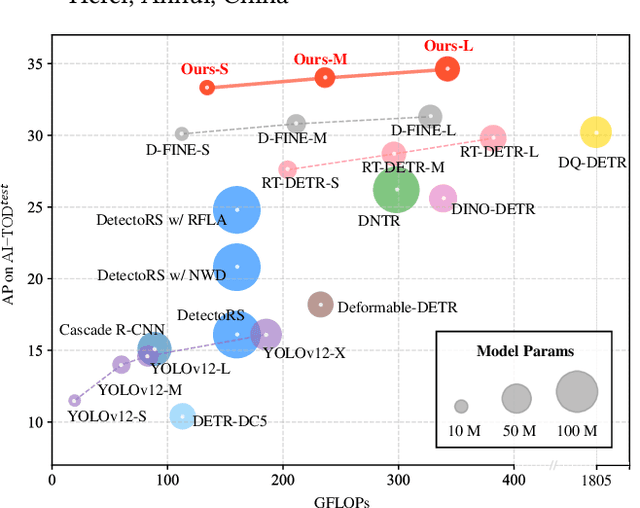
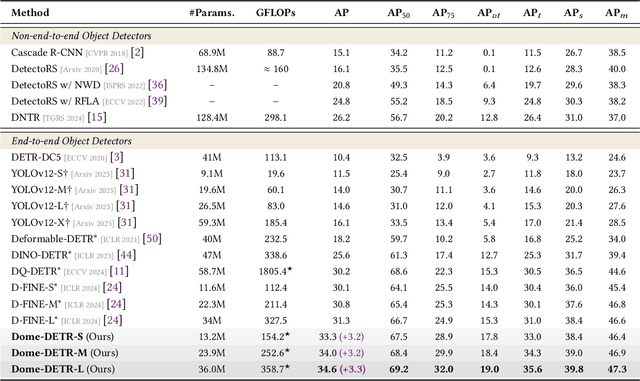
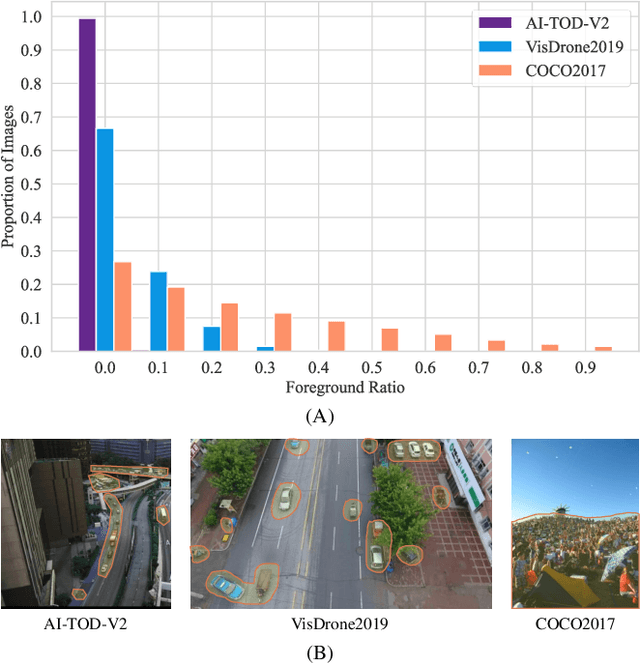
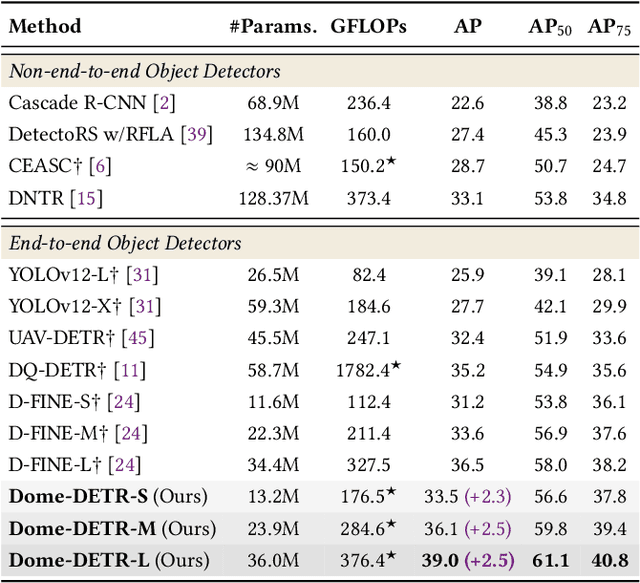
Tiny object detection plays a vital role in drone surveillance, remote sensing, and autonomous systems, enabling the identification of small targets across vast landscapes. However, existing methods suffer from inefficient feature leverage and high computational costs due to redundant feature processing and rigid query allocation. To address these challenges, we propose Dome-DETR, a novel framework with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection. To reduce feature redundancies, we introduce a lightweight Density-Focal Extractor (DeFE) to produce clustered compact foreground masks. Leveraging these masks, we incorporate Masked Window Attention Sparsification (MWAS) to focus computational resources on the most informative regions via sparse attention. Besides, we propose Progressive Adaptive Query Initialization (PAQI), which adaptively modulates query density across spatial areas for better query allocation. Extensive experiments demonstrate that Dome-DETR achieves state-of-the-art performance (+3.3 AP on AI-TOD-V2 and +2.5 AP on VisDrone) while maintaining low computational complexity and a compact model size. Code will be released upon acceptance.
Efficient Spiking Point Mamba for Point Cloud Analysis
Apr 19, 2025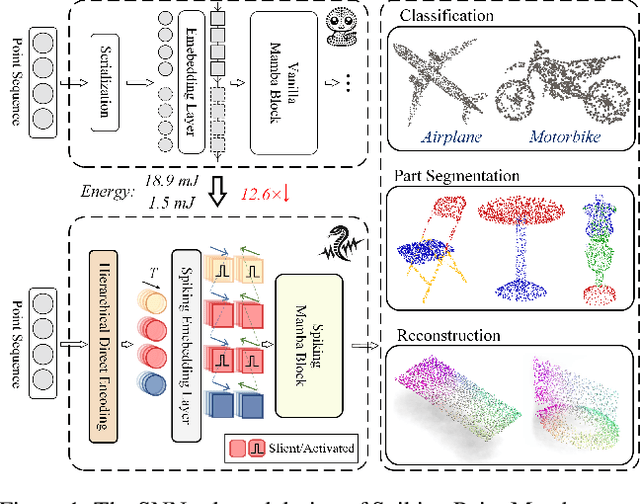



Bio-inspired Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. However, existing 3D SNNs have struggled with long-range dependencies until the recent emergence of Mamba, which offers superior computational efficiency and sequence modeling capability. In this work, we propose Spiking Point Mamba (SPM), the first Mamba-based SNN in the 3D domain. Due to the poor performance of simply transferring Mamba to 3D SNNs, SPM is designed to utilize both the sequence modeling capabilities of Mamba and the temporal feature extraction of SNNs. Specifically, we first introduce Hierarchical Dynamic Encoding (HDE), an improved direct encoding method that effectively introduces dynamic temporal mechanism, thereby facilitating temporal interactions. Then, we propose a Spiking Mamba Block (SMB), which builds upon Mamba while learning inter-time-step features and minimizing information loss caused by spikes. Finally, to further enhance model performance, we adopt an asymmetric SNN-ANN architecture for spike-based pre-training and finetune. Compared with the previous state-of-the-art SNN models, SPM improves OA by +6.2%, +6.1%, and +7.4% on three variants of ScanObjectNN, and boosts instance mIOU by +1.9% on ShapeNetPart. Meanwhile, its energy consumption is at least 3.5x lower than that of its ANN counterpart. The code will be made publicly available.
Spiking Point Transformer for Point Cloud Classification
Feb 19, 2025Spiking Neural Networks (SNNs) offer an attractive and energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their sparse binary activation. When SNN meets Transformer, it shows great potential in 2D image processing. However, their application for 3D point cloud remains underexplored. To this end, we present Spiking Point Transformer (SPT), the first transformer-based SNN framework for point cloud classification. Specifically, we first design Queue-Driven Sampling Direct Encoding for point cloud to reduce computational costs while retaining the most effective support points at each time step. We introduce the Hybrid Dynamics Integrate-and-Fire Neuron (HD-IF), designed to simulate selective neuron activation and reduce over-reliance on specific artificial neurons. SPT attains state-of-the-art results on three benchmark datasets that span both real-world and synthetic datasets in the SNN domain. Meanwhile, the theoretical energy consumption of SPT is at least 6.4$\times$ less than its ANN counterpart.
D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
Oct 17, 2024



We introduce D-FINE, a powerful real-time object detector that achieves outstanding localization precision by redefining the bounding box regression task in DETR models. D-FINE comprises two key components: Fine-grained Distribution Refinement (FDR) and Global Optimal Localization Self-Distillation (GO-LSD). FDR transforms the regression process from predicting fixed coordinates to iteratively refining probability distributions, providing a fine-grained intermediate representation that significantly enhances localization accuracy. GO-LSD is a bidirectional optimization strategy that transfers localization knowledge from refined distributions to shallower layers through self-distillation, while also simplifying the residual prediction tasks for deeper layers. Additionally, D-FINE incorporates lightweight optimizations in computationally intensive modules and operations, achieving a better balance between speed and accuracy. Specifically, D-FINE-L / X achieves 54.0% / 55.8% AP on the COCO dataset at 124 / 78 FPS on an NVIDIA T4 GPU. When pretrained on Objects365, D-FINE-L / X attains 57.1% / 59.3% AP, surpassing all existing real-time detectors. Furthermore, our method significantly enhances the performance of a wide range of DETR models by up to 5.3% AP with negligible extra parameters and training costs. Our code and pretrained models: https://github.com/Peterande/D-FINE.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
Enhanced Object Detection: A Study on Vast Vocabulary Object Detection Track for V3Det Challenge 2024
Jun 13, 2024
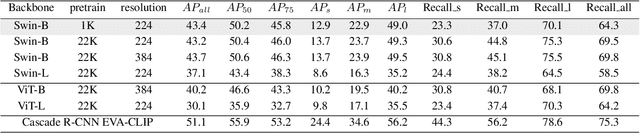

In this technical report, we present our findings from the research conducted on the Vast Vocabulary Visual Detection (V3Det) dataset for Supervised Vast Vocabulary Visual Detection task. How to deal with complex categories and detection boxes has become a difficulty in this track. The original supervised detector is not suitable for this task. We have designed a series of improvements, including adjustments to the network structure, changes to the loss function, and design of training strategies. Our model has shown improvement over the baseline and achieved excellent rankings on the Leaderboard for both the Vast Vocabulary Object Detection (Supervised) track and the Open Vocabulary Object Detection (OVD) track of the V3Det Challenge 2024.
LIO-PPF: Fast LiDAR-Inertial Odometry via Incremental Plane Pre-Fitting and Skeleton Tracking
Mar 02, 2023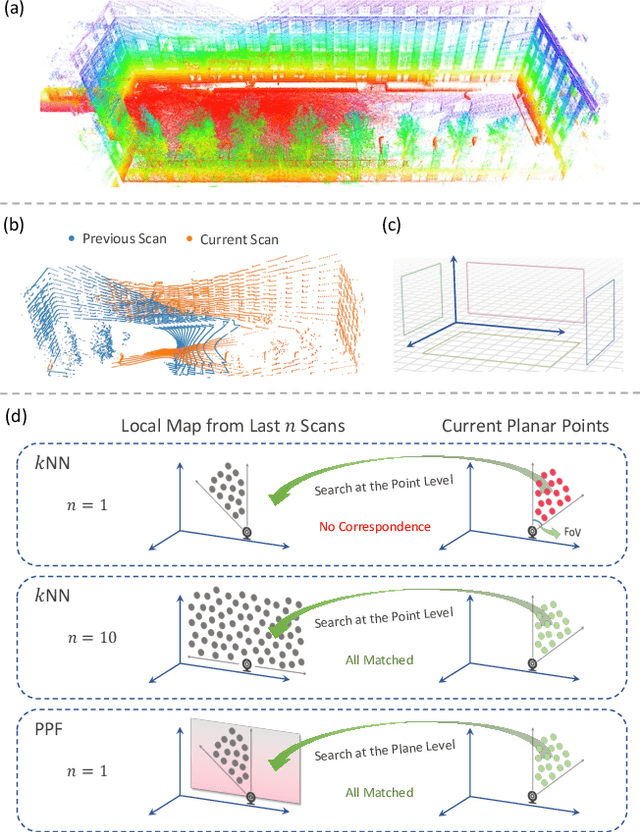
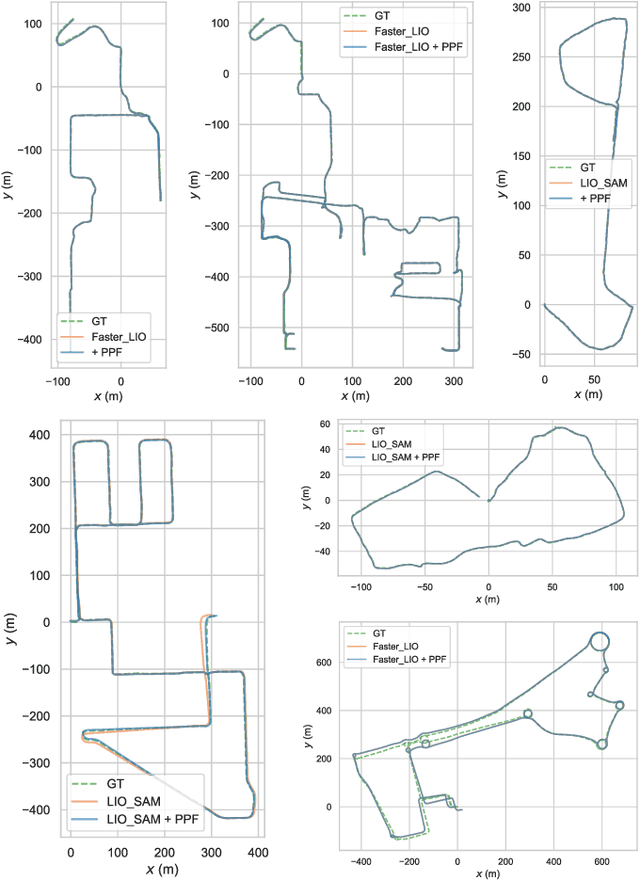

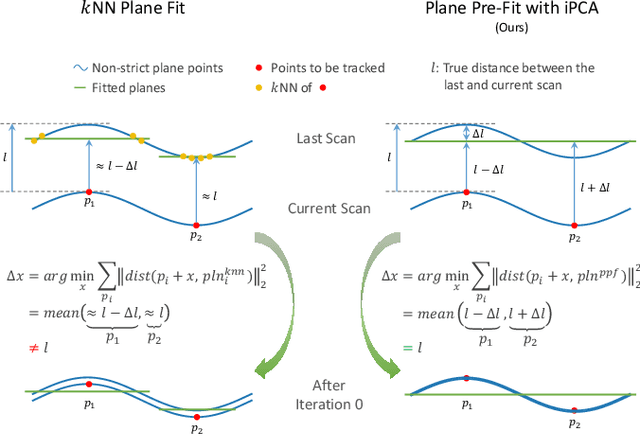
As a crucial infrastructure of intelligent mobile robots, LiDAR-Inertial odometry (LIO) provides the basic capability of state estimation by tracking LiDAR scans. The high-accuracy tracking generally involves the kNN search, which is used with minimizing the point-to-plane distance. The cost for this, however, is maintaining a large local map and performing kNN plane fit for each point. In this work, we reduce both time and space complexity of LIO by saving these unnecessary costs. Technically, we design a plane pre-fitting (PPF) pipeline to track the basic skeleton of the 3D scene. In PPF, planes are not fitted individually for each scan, let alone for each point, but are updated incrementally as the scene 'flows'. Unlike kNN, the PPF is more robust to noisy and non-strict planes with our iterative Principal Component Analyse (iPCA) refinement. Moreover, a simple yet effective sandwich layer is introduced to eliminate false point-to-plane matches. Our method was extensively tested on a total number of 22 sequences across 5 open datasets, and evaluated in 3 existing state-of-the-art LIO systems. By contrast, LIO-PPF can consume only 36% of the original local map size to achieve up to 4x faster residual computing and 1.92x overall FPS, while maintaining the same level of accuracy. We fully open source our implementation at https://github.com/xingyuuchen/LIO-PPF.