 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
Enhanced Object Detection: A Study on Vast Vocabulary Object Detection Track for V3Det Challenge 2024
Jun 13, 2024
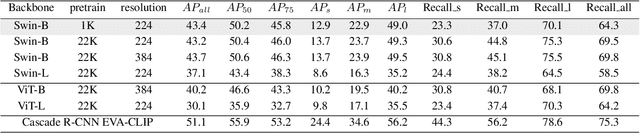
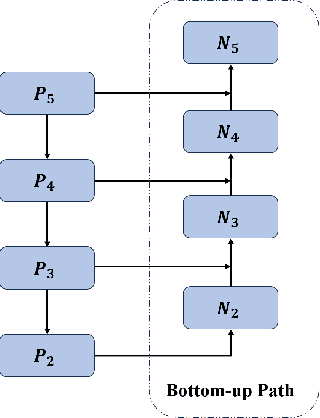

In this technical report, we present our findings from the research conducted on the Vast Vocabulary Visual Detection (V3Det) dataset for Supervised Vast Vocabulary Visual Detection task. How to deal with complex categories and detection boxes has become a difficulty in this track. The original supervised detector is not suitable for this task. We have designed a series of improvements, including adjustments to the network structure, changes to the loss function, and design of training strategies. Our model has shown improvement over the baseline and achieved excellent rankings on the Leaderboard for both the Vast Vocabulary Object Detection (Supervised) track and the Open Vocabulary Object Detection (OVD) track of the V3Det Challenge 2024.
P-MSDiff: Parallel Multi-Scale Diffusion for Remote Sensing Image Segmentation
May 30, 2024



Diffusion models and multi-scale features are essential components in semantic segmentation tasks that deal with remote-sensing images. They contribute to improved segmentation boundaries and offer significant contextual information. U-net-like architectures are frequently employed in diffusion models for segmentation tasks. These architectural designs include dense skip connections that may pose challenges for interpreting intermediate features. Consequently, they might not efficiently convey semantic information throughout various layers of the encoder-decoder architecture. To address these challenges, we propose a new model for semantic segmentation known as the diffusion model with parallel multi-scale branches. This model consists of Parallel Multiscale Diffusion modules (P-MSDiff) and a Cross-Bridge Linear Attention mechanism (CBLA). P-MSDiff enhances the understanding of semantic information across multiple levels of granularity and detects repetitive distribution data through the integration of recursive denoising branches. It further facilitates the amalgamation of data by connecting relevant branches to the primary framework to enable concurrent denoising. Furthermore, within the interconnected transformer architecture, the LA module has been substituted with the CBLA module. This module integrates a semidefinite matrix linked to the query into the dot product computation of keys and values. This integration enables the adaptation of queries within the LA framework. This adjustment enhances the structure for multi-head attention computation, leading to enhanced network performance and CBLA is a plug-and-play module. Our model demonstrates superior performance based on the J1 metric on both the UAVid and Vaihingen Building datasets, showing improvements of 1.60% and 1.40% over strong baseline models, respectively.