 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spiking Point Mamba for Point Cloud Analysis
Apr 19, 2025Bio-inspired Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. However, existing 3D SNNs have struggled with long-range dependencies until the recent emergence of Mamba, which offers superior computational efficiency and sequence modeling capability. In this work, we propose Spiking Point Mamba (SPM), the first Mamba-based SNN in the 3D domain. Due to the poor performance of simply transferring Mamba to 3D SNNs, SPM is designed to utilize both the sequence modeling capabilities of Mamba and the temporal feature extraction of SNNs. Specifically, we first introduce Hierarchical Dynamic Encoding (HDE), an improved direct encoding method that effectively introduces dynamic temporal mechanism, thereby facilitating temporal interactions. Then, we propose a Spiking Mamba Block (SMB), which builds upon Mamba while learning inter-time-step features and minimizing information loss caused by spikes. Finally, to further enhance model performance, we adopt an asymmetric SNN-ANN architecture for spike-based pre-training and finetune. Compared with the previous state-of-the-art SNN models, SPM improves OA by +6.2%, +6.1%, and +7.4% on three variants of ScanObjectNN, and boosts instance mIOU by +1.9% on ShapeNetPart. Meanwhile, its energy consumption is at least 3.5x lower than that of its ANN counterpart. The code will be made publicly available.
Spiking Point Transformer for Point Cloud Classification
Feb 19, 2025Spiking Neural Networks (SNNs) offer an attractive and energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their sparse binary activation. When SNN meets Transformer, it shows great potential in 2D image processing. However, their application for 3D point cloud remains underexplored. To this end, we present Spiking Point Transformer (SPT), the first transformer-based SNN framework for point cloud classification. Specifically, we first design Queue-Driven Sampling Direct Encoding for point cloud to reduce computational costs while retaining the most effective support points at each time step. We introduce the Hybrid Dynamics Integrate-and-Fire Neuron (HD-IF), designed to simulate selective neuron activation and reduce over-reliance on specific artificial neurons. SPT attains state-of-the-art results on three benchmark datasets that span both real-world and synthetic datasets in the SNN domain. Meanwhile, the theoretical energy consumption of SPT is at least 6.4$\times$ less than its ANN counterpart.
DiffX: Guide Your Layout to Cross-Modal Generative Modeling
Jul 28, 2024


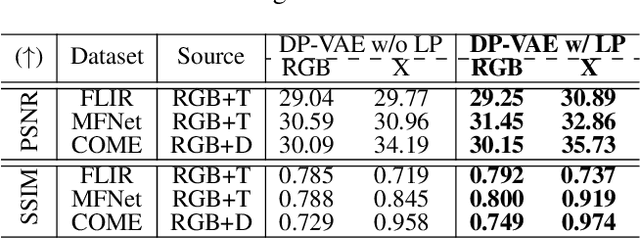
Diffusion models have made significant strides in language-driven and layout-driven image generation. However, most diffusion models are limited to visible RGB image generation. In fact, human perception of the world is enriched by diverse viewpoints, including chromatic contrast, thermal illumination, and depth information. In this paper, we introduce a novel diffusion model for general layout-guided cross-modal ``RGB+X'' generation, called DiffX. Firstly, we construct the cross-modal image datasets with text description by using LLaVA for image captioning, supplemented by manual corrections. Notably, DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space, facilitated by our Dual Path Variational AutoEncoder (DP-VAE). Moreover, we introduce the joint-modality embedder, which incorporates a gated cross-attention mechanism to link layout and text conditions. Meanwhile, the advanced Long-CLIP is employed for long caption embedding to improve user guidance. Through extensive experiments, DiffX demonstrates robustness and flexibility in cross-modal generation across three RGB+X datasets: FLIR, MFNet, and COME15K, guided by various layout types. It also shows the potential for adaptive generation of ``RGB+X+Y'' or more diverse modalities. Our code and constructed cross-modal image datasets are available at https://github.com/zeyuwang-zju/DiffX.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
Enhanced Object Detection: A Study on Vast Vocabulary Object Detection Track for V3Det Challenge 2024
Jun 13, 2024
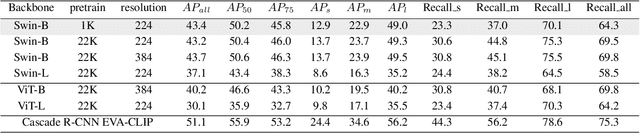
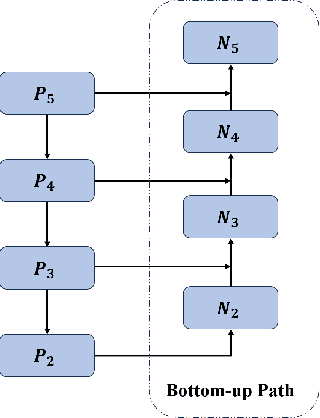

In this technical report, we present our findings from the research conducted on the Vast Vocabulary Visual Detection (V3Det) dataset for Supervised Vast Vocabulary Visual Detection task. How to deal with complex categories and detection boxes has become a difficulty in this track. The original supervised detector is not suitable for this task. We have designed a series of improvements, including adjustments to the network structure, changes to the loss function, and design of training strategies. Our model has shown improvement over the baseline and achieved excellent rankings on the Leaderboard for both the Vast Vocabulary Object Detection (Supervised) track and the Open Vocabulary Object Detection (OVD) track of the V3Det Challenge 2024.