 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffX: Guide Your Layout to Cross-Modal Generative Modeling
Paper and Code



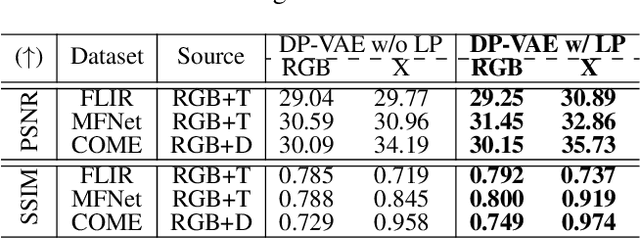
Diffusion models have made significant strides in language-driven and layout-driven image generation. However, most diffusion models are limited to visible RGB image generation. In fact, human perception of the world is enriched by diverse viewpoints, including chromatic contrast, thermal illumination, and depth information. In this paper, we introduce a novel diffusion model for general layout-guided cross-modal ``RGB+X'' generation, called DiffX. Firstly, we construct the cross-modal image datasets with text description by using LLaVA for image captioning, supplemented by manual corrections. Notably, DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space, facilitated by our Dual Path Variational AutoEncoder (DP-VAE). Moreover, we introduce the joint-modality embedder, which incorporates a gated cross-attention mechanism to link layout and text conditions. Meanwhile, the advanced Long-CLIP is employed for long caption embedding to improve user guidance. Through extensive experiments, DiffX demonstrates robustness and flexibility in cross-modal generation across three RGB+X datasets: FLIR, MFNet, and COME15K, guided by various layout types. It also shows the potential for adaptive generation of ``RGB+X+Y'' or more diverse modalities. Our code and constructed cross-modal image datasets are available at https://github.com/zeyuwang-zju/DiffX.