 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Residual Errors in Compensation-based LLM Quantization
Apr 09, 2026Methods based on weight compensation, which iteratively apply quantization and weight compensation to minimize the output error, have recently demonstrated remarkable success in quantizing Large Language Models (LLMs). The representative work, GPTQ, introduces several key techniques that make such iterative methods practical for LLMs with billions of parameters. GPTAQ extends this approach by introducing an asymmetric calibration process that aligns the output of each quantized layer with its full-precision counterpart, incorporating a residual error into the weight compensation framework. In this work, we revisit the formulation of the residual error. We identify a sub-optimal calibration objective in existing methods: during the intra-layer calibration process, they align the quantized output with the output from compensated weights, rather than the true output from the original full-precision model. Therefore, we redefine the objective to precisely align the quantized model's output with the original output of the full-precision model at each step. We then reveal that the residual error originates not only from the output difference of the preceding layer but also from the discrepancy between the compensated and original weights within each layer, which we name the 'compensation-aware error'. By inheriting the neuron decomposition technique from GPTAQ, we can efficiently incorporate this compensation-aware error into the weight update process. Extensive experiments on various LLMs and quantization settings demonstrate that our proposed enhancements integrate seamlessly with both GPTQ and GPTAQ, significantly improving their quantization performance. Our code is publicly available at https://github.com/list0830/ResComp.
ViM-VQ: Efficient Post-Training Vector Quantization for Visual Mamba
Mar 12, 2025Visual Mamba networks (ViMs) extend the selective space state model (Mamba) to various vision tasks and demonstrate significant potential. Vector quantization (VQ), on the other hand, decomposes network weights into codebooks and assignments, significantly reducing memory usage and computational latency to enable ViMs deployment on edge devices. Although existing VQ methods have achieved extremely low-bit quantization (e.g., 3-bit, 2-bit, and 1-bit) in convolutional neural networks and Transformer-based networks, directly applying these methods to ViMs results in unsatisfactory accuracy. We identify several key challenges: 1) The weights of Mamba-based blocks in ViMs contain numerous outliers, significantly amplifying quantization errors. 2) When applied to ViMs, the latest VQ methods suffer from excessive memory consumption, lengthy calibration procedures, and suboptimal performance in the search for optimal codewords. In this paper, we propose ViM-VQ, an efficient post-training vector quantization method tailored for ViMs. ViM-VQ consists of two innovative components: 1) a fast convex combination optimization algorithm that efficiently updates both the convex combinations and the convex hulls to search for optimal codewords, and 2) an incremental vector quantization strategy that incrementally confirms optimal codewords to mitigate truncation errors. Experimental results demonstrate that ViM-VQ achieves state-of-the-art performance in low-bit quantization across various visual tasks.
SSVQ: Unleashing the Potential of Vector Quantization with Sign-Splitting
Mar 11, 2025



Vector Quantization (VQ) has emerged as a prominent weight compression technique, showcasing substantially lower quantization errors than uniform quantization across diverse models, particularly in extreme compression scenarios. However, its efficacy during fine-tuning is limited by the constraint of the compression format, where weight vectors assigned to the same codeword are restricted to updates in the same direction. Consequently, many quantized weights are compelled to move in directions contrary to their local gradient information. To mitigate this issue, we introduce a novel VQ paradigm, Sign-Splitting VQ (SSVQ), which decouples the sign bit of weights from the codebook. Our approach involves extracting the sign bits of uncompressed weights and performing clustering and compression on all-positive weights. We then introduce latent variables for the sign bit and jointly optimize both the signs and the codebook. Additionally, we implement a progressive freezing strategy for the learnable sign to ensure training stability. Extensive experiments on various modern models and tasks demonstrate that SSVQ achieves a significantly superior compression-accuracy trade-off compared to conventional VQ. Furthermore, we validate our algorithm on a hardware accelerator, showing that SSVQ achieves a 3$\times$ speedup over the 8-bit compressed model by reducing memory access.
MVQ:Towards Efficient DNN Compression and Acceleration with Masked Vector Quantization
Dec 13, 2024



Vector quantization(VQ) is a hardware-friendly DNN compression method that can reduce the storage cost and weight-loading datawidth of hardware accelerators. However, conventional VQ techniques lead to significant accuracy loss because the important weights are not well preserved. To tackle this problem, a novel approach called MVQ is proposed, which aims at better approximating important weights with a limited number of codewords. At the algorithm level, our approach removes the less important weights through N:M pruning and then minimizes the vector clustering error between the remaining weights and codewords by the masked k-means algorithm. Only distances between the unpruned weights and the codewords are computed, which are then used to update the codewords. At the architecture level, our accelerator implements vector quantization on an EWS (Enhanced weight stationary) CNN accelerator and proposes a sparse systolic array design to maximize the benefits brought by masked vector quantization.\\ Our algorithm is validated on various models for image classification, object detection, and segmentation tasks. Experimental results demonstrate that MVQ not only outperforms conventional vector quantization methods at comparable compression ratios but also reduces FLOPs. Under ASIC evaluation, our MVQ accelerator boosts energy efficiency by 2.3$\times$ and reduces the size of the systolic array by 55\% when compared with the base EWS accelerator. Compared to the previous sparse accelerators, MVQ achieves 1.73$\times$ higher energy efficiency.
Efficiency Meets Fidelity: A Novel Quantization Framework for Stable Diffusion
Dec 09, 2024



Text-to-image generation of Stable Diffusion models has achieved notable success due to its remarkable generation ability. However, the repetitive denoising process is computationally intensive during inference, which renders Diffusion models less suitable for real-world applications that require low latency and scalability. Recent studies have employed post-training quantization (PTQ) and quantization-aware training (QAT) methods to compress Diffusion models. Nevertheless, prior research has often neglected to examine the consistency between results generated by quantized models and those from floating-point models. This consistency is crucial in fields such as content creation, design, and edge deployment, as it can significantly enhance both efficiency and system stability for practitioners. To ensure that quantized models generate high-quality and consistent images, we propose an efficient quantization framework for Stable Diffusion models. Our approach features a Serial-to-Parallel calibration pipeline that addresses the consistency of both the calibration and inference processes, as well as ensuring training stability. Based on this pipeline, we further introduce a mix-precision quantization strategy, multi-timestep activation quantization, and time information precalculation techniques to ensure high-fidelity generation in comparison to floating-point models. Through extensive experiments with Stable Diffusion v1-4, v2-1, and XL 1.0, we have demonstrated that our method outperforms the current state-of-the-art techniques when tested on prompts from the COCO validation dataset and the Stable-Diffusion-Prompts dataset. Under W4A8 quantization settings, our approach enhances both distribution similarity and visual similarity by 45%-60%.
VQ4ALL: Efficient Neural Network Representation via a Universal Codebook
Dec 09, 2024
The rapid growth of the big neural network models puts forward new requirements for lightweight network representation methods. The traditional methods based on model compression have achieved great success, especially VQ technology which realizes the high compression ratio of models by sharing code words. However, because each layer of the network needs to build a code table, the traditional top-down compression technology lacks attention to the underlying commonalities, resulting in limited compression rate and frequent memory access. In this paper, we propose a bottom-up method to share the universal codebook among multiple neural networks, which not only effectively reduces the number of codebooks but also further reduces the memory access and chip area by storing static code tables in the built-in ROM. Specifically, we introduce VQ4ALL, a VQ-based method that utilizes codewords to enable the construction of various neural networks and achieve efficient representations. The core idea of our method is to adopt a kernel density estimation approach to extract a universal codebook and then progressively construct different low-bit networks by updating differentiable assignments. Experimental results demonstrate that VQ4ALL achieves compression rates exceeding 16 $\times$ while preserving high accuracy across multiple network architectures, highlighting its effectiveness and versatility.
VQ4DiT: Efficient Post-Training Vector Quantization for Diffusion Transformers
Aug 30, 2024



The Diffusion Transformers Models (DiTs) have transitioned the network architecture from traditional UNets to transformers, demonstrating exceptional capabilities in image generation. Although DiTs have been widely applied to high-definition video generation tasks, their large parameter size hinders inference on edge devices. Vector quantization (VQ) can decompose model weight into a codebook and assignments, allowing extreme weight quantization and significantly reducing memory usage. In this paper, we propose VQ4DiT, a fast post-training vector quantization method for DiTs. We found that traditional VQ methods calibrate only the codebook without calibrating the assignments. This leads to weight sub-vectors being incorrectly assigned to the same assignment, providing inconsistent gradients to the codebook and resulting in a suboptimal result. To address this challenge, VQ4DiT calculates the candidate assignment set for each weight sub-vector based on Euclidean distance and reconstructs the sub-vector based on the weighted average. Then, using the zero-data and block-wise calibration method, the optimal assignment from the set is efficiently selected while calibrating the codebook. VQ4DiT quantizes a DiT XL/2 model on a single NVIDIA A100 GPU within 20 minutes to 5 hours depending on the different quantization settings. Experiments show that VQ4DiT establishes a new state-of-the-art in model size and performance trade-offs, quantizing weights to 2-bit precision while retaining acceptable image generation quality.
DiffX: Guide Your Layout to Cross-Modal Generative Modeling
Jul 28, 2024


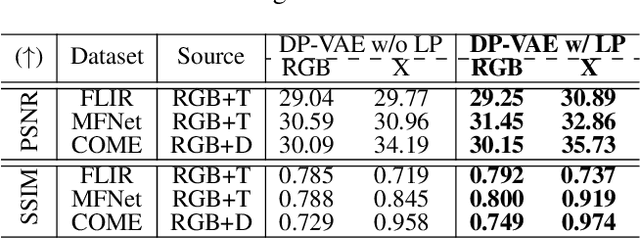
Diffusion models have made significant strides in language-driven and layout-driven image generation. However, most diffusion models are limited to visible RGB image generation. In fact, human perception of the world is enriched by diverse viewpoints, including chromatic contrast, thermal illumination, and depth information. In this paper, we introduce a novel diffusion model for general layout-guided cross-modal ``RGB+X'' generation, called DiffX. Firstly, we construct the cross-modal image datasets with text description by using LLaVA for image captioning, supplemented by manual corrections. Notably, DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space, facilitated by our Dual Path Variational AutoEncoder (DP-VAE). Moreover, we introduce the joint-modality embedder, which incorporates a gated cross-attention mechanism to link layout and text conditions. Meanwhile, the advanced Long-CLIP is employed for long caption embedding to improve user guidance. Through extensive experiments, DiffX demonstrates robustness and flexibility in cross-modal generation across three RGB+X datasets: FLIR, MFNet, and COME15K, guided by various layout types. It also shows the potential for adaptive generation of ``RGB+X+Y'' or more diverse modalities. Our code and constructed cross-modal image datasets are available at https://github.com/zeyuwang-zju/DiffX.
Robust Edge-Direct Visual Odometry based on CNN edge detection and Shi-Tomasi corner optimization
Oct 21, 2021

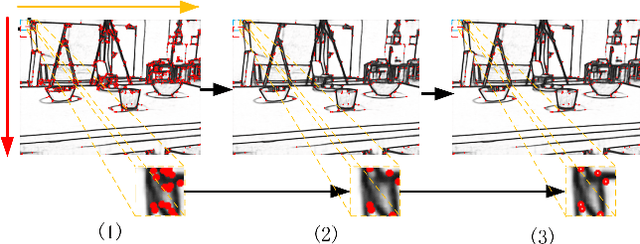
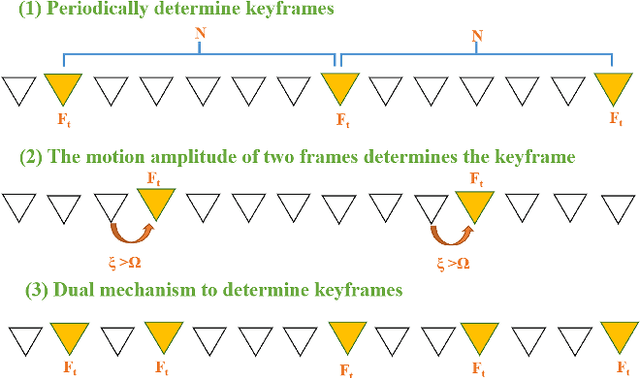
In this paper, we propose a robust edge-direct visual odometry (VO) based on CNN edge detection and Shi-Tomasi corner optimization. Four layers of pyramids were extracted from the image in the proposed method to reduce the motion error between frames. This solution used CNN edge detection and Shi-Tomasi corner optimization to extract information from the image. Then, the pose estimation is performed using the Levenberg-Marquardt (LM) algorithm and updating the keyframes. Our method was compared with the dense direct method, the improved direct method of Canny edge detection, and ORB-SLAM2 system on the RGB-D TUM benchmark. The experimental results indicate that our method achieves better robustness and accuracy.