 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting
Feb 28, 2025



Zero-shot object counting aims to count instances of arbitrary object categories specified by text descriptions. Existing methods typically rely on vision-language models like CLIP, but often exhibit limited sensitivity to text prompts. We present T2ICount, a diffusion-based framework that leverages rich prior knowledge and fine-grained visual understanding from pretrained diffusion models. While one-step denoising ensures efficiency, it leads to weakened text sensitivity. To address this challenge, we propose a Hierarchical Semantic Correction Module that progressively refines text-image feature alignment, and a Representational Regional Coherence Loss that provides reliable supervision signals by leveraging the cross-attention maps extracted from the denosing U-Net. Furthermore, we observe that current benchmarks mainly focus on majority objects in images, potentially masking models' text sensitivity. To address this, we contribute a challenging re-annotated subset of FSC147 for better evaluation of text-guided counting ability. Extensive experiments demonstrate that our method achieves superior performance across different benchmarks. Code is available at https://github.com/cha15yq/T2ICount.
A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse
Aug 20, 2024
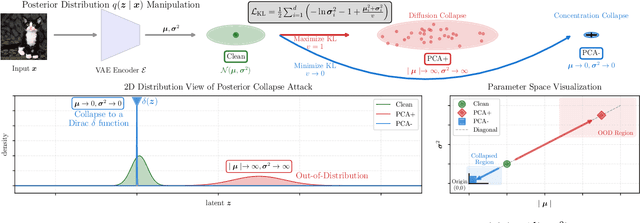


Recent advancements in generative AI, particularly Latent Diffusion Models (LDMs), have revolutionized image synthesis and manipulation. However, these generative techniques raises concerns about data misappropriation and intellectual property infringement. Adversarial attacks on machine learning models have been extensively studied, and a well-established body of research has extended these techniques as a benign metric to prevent the underlying misuse of generative AI. Current approaches to safeguarding images from manipulation by LDMs are limited by their reliance on model-specific knowledge and their inability to significantly degrade semantic quality of generated images. In response to these shortcomings, we propose the Posterior Collapse Attack (PCA) based on the observation that VAEs suffer from posterior collapse during training. Our method minimizes dependence on the white-box information of target models to get rid of the implicit reliance on model-specific knowledge. By accessing merely a small amount of LDM parameters, in specific merely the VAE encoder of LDMs, our method causes a substantial semantic collapse in generation quality, particularly in perceptual consistency, and demonstrates strong transferability across various model architectures. Experimental results show that PCA achieves superior perturbation effects on image generation of LDMs with lower runtime and VRAM. Our method outperforms existing techniques, offering a more robust and generalizable solution that is helpful in alleviating the socio-technical challenges posed by the rapidly evolving landscape of generative AI.
DiffX: Guide Your Layout to Cross-Modal Generative Modeling
Jul 28, 2024


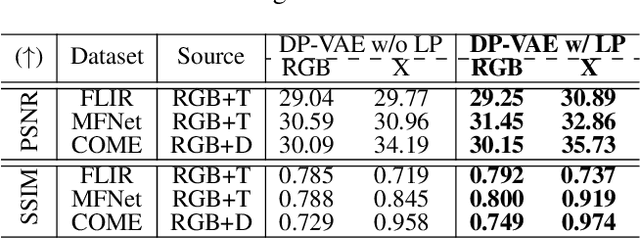
Diffusion models have made significant strides in language-driven and layout-driven image generation. However, most diffusion models are limited to visible RGB image generation. In fact, human perception of the world is enriched by diverse viewpoints, including chromatic contrast, thermal illumination, and depth information. In this paper, we introduce a novel diffusion model for general layout-guided cross-modal ``RGB+X'' generation, called DiffX. Firstly, we construct the cross-modal image datasets with text description by using LLaVA for image captioning, supplemented by manual corrections. Notably, DiffX presents a simple yet effective cross-modal generative modeling pipeline, which conducts diffusion and denoising processes in the modality-shared latent space, facilitated by our Dual Path Variational AutoEncoder (DP-VAE). Moreover, we introduce the joint-modality embedder, which incorporates a gated cross-attention mechanism to link layout and text conditions. Meanwhile, the advanced Long-CLIP is employed for long caption embedding to improve user guidance. Through extensive experiments, DiffX demonstrates robustness and flexibility in cross-modal generation across three RGB+X datasets: FLIR, MFNet, and COME15K, guided by various layout types. It also shows the potential for adaptive generation of ``RGB+X+Y'' or more diverse modalities. Our code and constructed cross-modal image datasets are available at https://github.com/zeyuwang-zju/DiffX.
Artwork Protection Against Neural Style Transfer Using Locally Adaptive Adversarial Color Attack
Jan 18, 2024



Neural style transfer (NST) is widely adopted in computer vision to generate new images with arbitrary styles. This process leverages neural networks to merge aesthetic elements of a style image with the structural aspects of a content image into a harmoniously integrated visual result. However, unauthorized NST can exploit artwork. Such misuse raises socio-technical concerns regarding artists' rights and motivates the development of technical approaches for the proactive protection of original creations. Adversarial attack is a concept primarily explored in machine learning security. Our work introduces this technique to protect artists' intellectual property. In this paper Locally Adaptive Adversarial Color Attack (LAACA), a method for altering images in a manner imperceptible to the human eyes but disruptive to NST. Specifically, we design perturbations targeting image areas rich in high-frequency content, generated by disrupting intermediate features. Our experiments and user study confirm that by attacking NST using the proposed method results in visually worse neural style transfer, thus making it an effective solution for visual artwork protection.
Semi-Supervised Crowd Counting with Contextual Modeling: Facilitating Holistic Understanding of Crowd Scenes
Oct 23, 2023To alleviate the heavy annotation burden for training a reliable crowd counting model and thus make the model more practicable and accurate by being able to benefit from more data, this paper presents a new semi-supervised method based on the mean teacher framework. When there is a scarcity of labeled data available, the model is prone to overfit local patches. Within such contexts, the conventional approach of solely improving the accuracy of local patch predictions through unlabeled data proves inadequate. Consequently, we propose a more nuanced approach: fostering the model's intrinsic 'subitizing' capability. This ability allows the model to accurately estimate the count in regions by leveraging its understanding of the crowd scenes, mirroring the human cognitive process. To achieve this goal, we apply masking on unlabeled data, guiding the model to make predictions for these masked patches based on the holistic cues. Furthermore, to help with feature learning, herein we incorporate a fine-grained density classification task. Our method is general and applicable to most existing crowd counting methods as it doesn't have strict structural or loss constraints. In addition, we observe that the model trained with our framework exhibits a 'subitizing'-like behavior. It accurately predicts low-density regions with only a 'glance', while incorporating local details to predict high-density regions. Our method achieves the state-of-the-art performance, surpassing previous approaches by a large margin on challenging benchmarks such as ShanghaiTech A and UCF-QNRF. The code is available at: https://github.com/cha15yq/MRC-Crowd.
Multimodal Latent Emotion Recognition from Micro-expression and Physiological Signals
Aug 23, 2023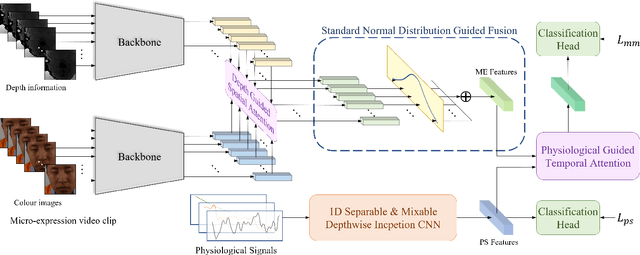

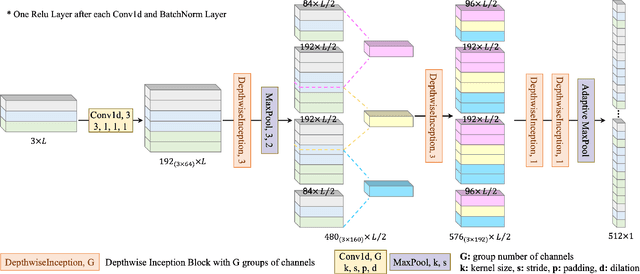
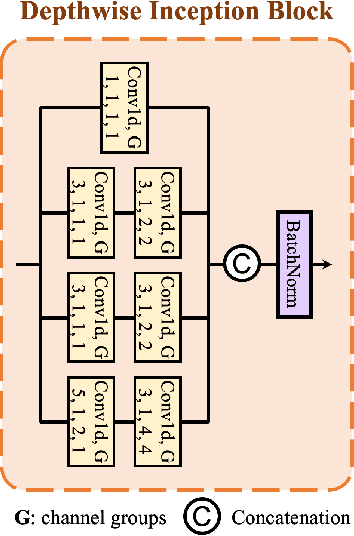
This paper discusses the benefits of incorporating multimodal data for improving latent emotion recognition accuracy, focusing on micro-expression (ME) and physiological signals (PS). The proposed approach presents a novel multimodal learning framework that combines ME and PS, including a 1D separable and mixable depthwise inception network, a standardised normal distribution weighted feature fusion method, and depth/physiology guided attention modules for multimodal learning. Experimental results show that the proposed approach outperforms the benchmark method, with the weighted fusion method and guided attention modules both contributing to enhanced performance.
A White-Box False Positive Adversarial Attack Method on Contrastive Loss-Based Offline Handwritten Signature Verification Models
Aug 17, 2023In this paper, we tackle the challenge of white-box false positive adversarial attacks on contrastive loss-based offline handwritten signature verification models. We propose a novel attack method that treats the attack as a style transfer between closely related but distinct writing styles. To guide the generation of deceptive images, we introduce two new loss functions that enhance the attack success rate by perturbing the Euclidean distance between the embedding vectors of the original and synthesized samples, while ensuring minimal perturbations by reducing the difference between the generated image and the original image. Our method demonstrates state-of-the-art performance in white-box attacks on contrastive loss-based offline handwritten signature verification models, as evidenced by our experiments. The key contributions of this paper include a novel false positive attack method, two new loss functions, effective style transfer in handwriting styles, and superior performance in white-box false positive attacks compared to other white-box attack methods.