 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformers Understand Ancient Roman Coin Motifs Better than CNNs?
Jan 14, 2026Automated analysis of ancient coins has the potential to help researchers extract more historical insights from large collections of coins and to help collectors understand what they are buying or selling. Recent research in this area has shown promise in focusing on identification of semantic elements as they are commonly depicted on ancient coins, by using convolutional neural networks (CNNs). This paper is the first to apply the recently proposed Vision Transformer (ViT) deep learning architecture to the task of identification of semantic elements on coins, using fully automatic learning from multi-modal data (images and unstructured text). This article summarises previous research in the area, discusses the training and implementation of ViT and CNN models for ancient coins analysis and provides an evaluation of their performance. The ViT models were found to outperform the newly trained CNN models in accuracy.
Would I Lie To You? Inference Time Alignment of Language Models using Direct Preference Heads
May 30, 2024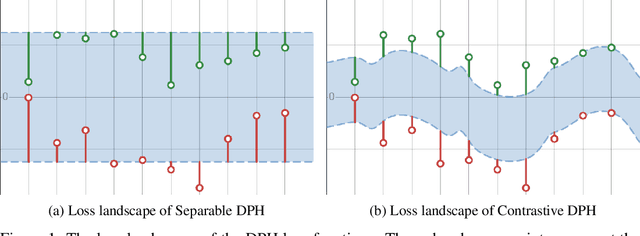
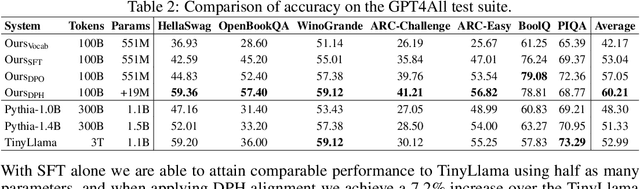
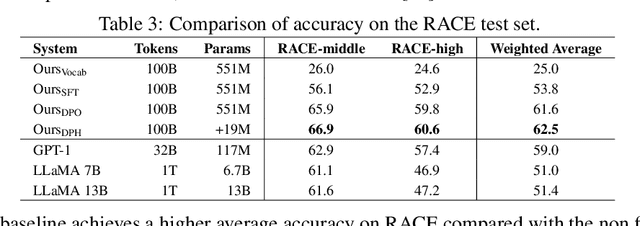
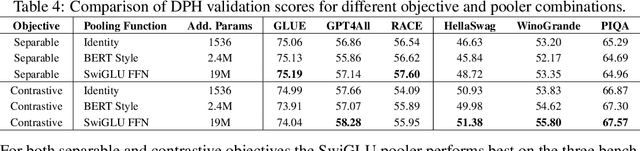
Pre-trained Language Models (LMs) exhibit strong zero-shot and in-context learning capabilities; however, their behaviors are often difficult to control. By utilizing Reinforcement Learning from Human Feedback (RLHF), it is possible to fine-tune unsupervised LMs to follow instructions and produce outputs that reflect human preferences. Despite its benefits, RLHF has been shown to potentially harm a language model's reasoning capabilities and introduce artifacts such as hallucinations where the model may fabricate facts. To address this issue we introduce Direct Preference Heads (DPH), a fine-tuning framework that enables LMs to learn human preference signals through an auxiliary reward head without directly affecting the output distribution of the language modeling head. We perform a theoretical analysis of our objective function and find strong ties to Conservative Direct Preference Optimization (cDPO). Finally we evaluate our models on GLUE, RACE, and the GPT4All evaluation suite and demonstrate that our method produces models which achieve higher scores than those fine-tuned with Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO) alone.
Context-PEFT: Efficient Multi-Modal, Multi-Task Fine-Tuning
Dec 14, 2023



This paper introduces a novel Parameter-Efficient Fine-Tuning (PEFT) framework for multi-modal, multi-task transfer learning with pre-trained language models. PEFT techniques such as LoRA, BitFit and IA3 have demonstrated comparable performance to full fine-tuning of pre-trained models for specific downstream tasks, all while demanding significantly fewer trainable parameters and reduced GPU memory consumption. However, in the context of multi-modal fine-tuning, the need for architectural modifications or full fine-tuning often becomes apparent. To address this we propose Context-PEFT, which learns different groups of adaptor parameters based on the token's domain. This approach enables LoRA-like weight injection without requiring additional architectural changes. Our method is evaluated on the COCO captioning task, where it outperforms full fine-tuning under similar data constraints while simultaneously offering a substantially more parameter-efficient and computationally economical solution.
Multimodal Latent Emotion Recognition from Micro-expression and Physiological Signals
Aug 23, 2023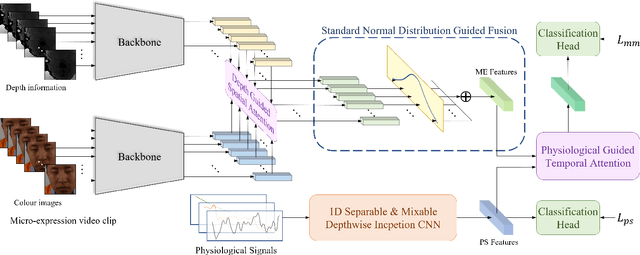

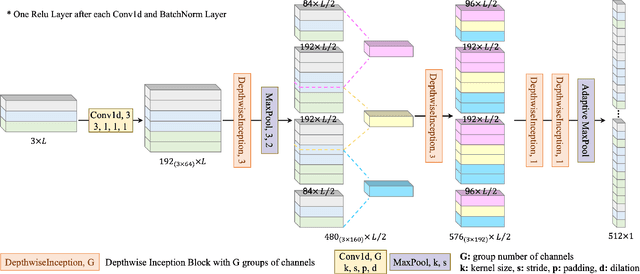
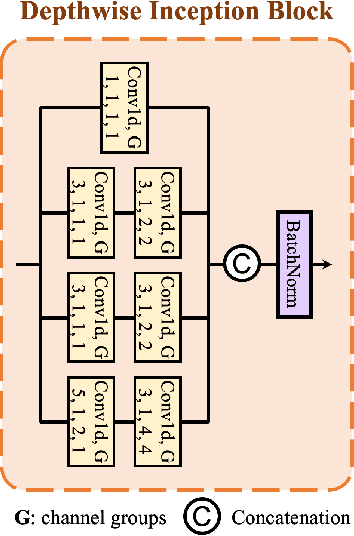
This paper discusses the benefits of incorporating multimodal data for improving latent emotion recognition accuracy, focusing on micro-expression (ME) and physiological signals (PS). The proposed approach presents a novel multimodal learning framework that combines ME and PS, including a 1D separable and mixable depthwise inception network, a standardised normal distribution weighted feature fusion method, and depth/physiology guided attention modules for multimodal learning. Experimental results show that the proposed approach outperforms the benchmark method, with the weighted fusion method and guided attention modules both contributing to enhanced performance.
Short and Long Range Relation Based Spatio-Temporal Transformer for Micro-Expression Recognition
Dec 14, 2021
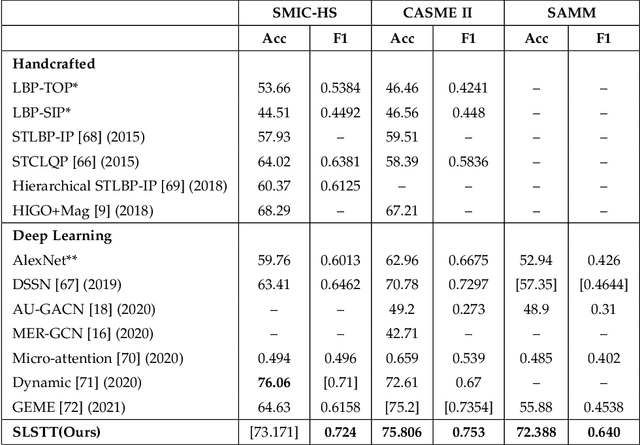
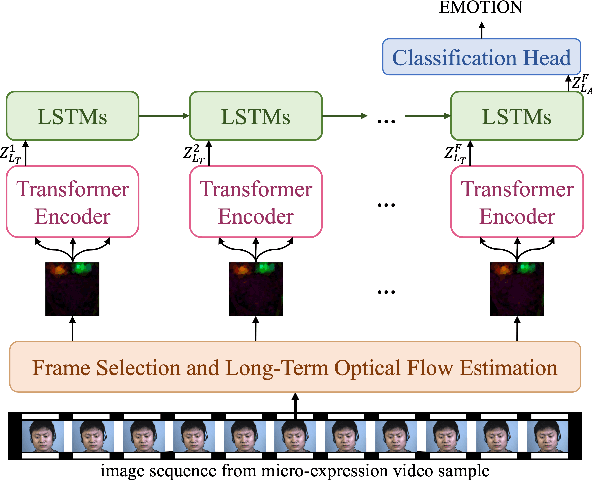
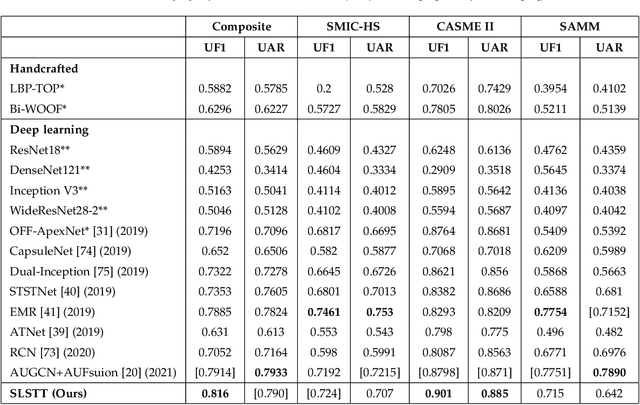
Being spontaneous, micro-expressions are useful in the inference of a person's true emotions even if an attempt is made to conceal them. Due to their short duration and low intensity, the recognition of micro-expressions is a difficult task in affective computing. The early work based on handcrafted spatio-temporal features which showed some promise, has recently been superseded by different deep learning approaches which now compete for the state of the art performance. Nevertheless, the problem of capturing both local and global spatio-temporal patterns remains challenging. To this end, herein we propose a novel spatio-temporal transformer architecture -- to the best of our knowledge, the first purely transformer based approach (i.e. void of any convolutional network use) for micro-expression recognition. The architecture comprises a spatial encoder which learns spatial patterns, a temporal aggregator for temporal dimension analysis, and a classification head. A comprehensive evaluation on three widely used spontaneous micro-expression data sets, namely SMIC-HS, CASME II and SAMM, shows that the proposed approach consistently outperforms the state of the art, and is the first framework in the published literature on micro-expression recognition to achieve the unweighted F1-score greater than 0.9 on any of the aforementioned data sets.
Magnifying Networks for Images with Billions of Pixels
Dec 12, 2021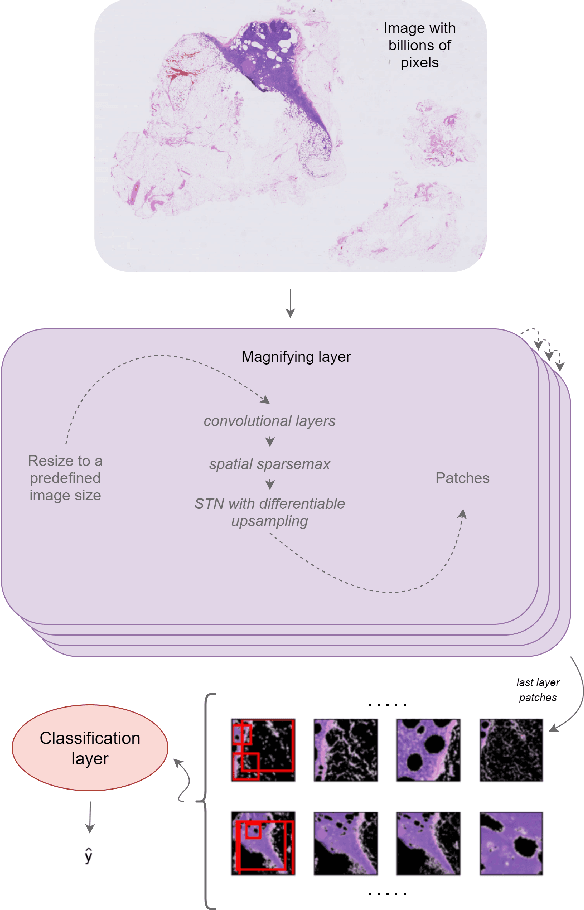
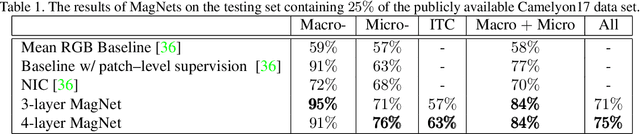
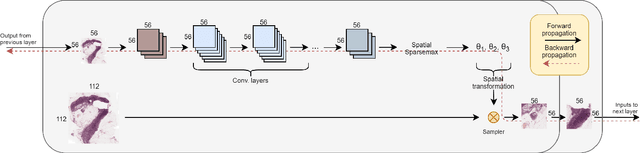

The shift towards end-to-end deep learning has brought unprecedented advances in many areas of computer vision. However, there are cases where the input images are excessively large, deeming end-to-end approaches impossible. In this paper, we introduce a new network, the Magnifying Network (MagNet), which can be trained end-to-end independently of the input image size. MagNets combine convolutional neural networks with differentiable spatial transformers, in a new way, to navigate and successfully learn from images with billions of pixels. Drawing inspiration from the magnifying nature of an ordinary brightfield microscope, a MagNet processes a downsampled version of an image, and without supervision learns how to identify areas that may carry value to the task at hand, upsamples them, and recursively repeats this process on each of the extracted patches. Our results on the publicly available Camelyon16 and Camelyon17 datasets first corroborate to the effectiveness of MagNets and the proposed optimization framework and second, demonstrate the advantage of Magnets' built-in transparency, an attribute of utmost importance for critical processes such as medical diagnosis.
A New Look at Ghost Normalization
Jul 16, 2020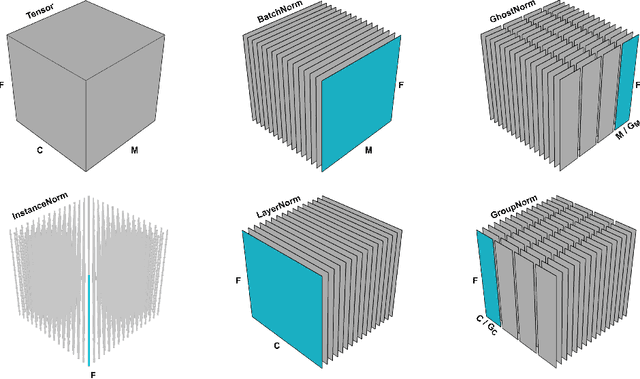
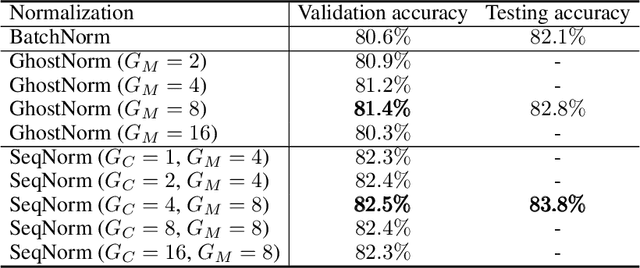

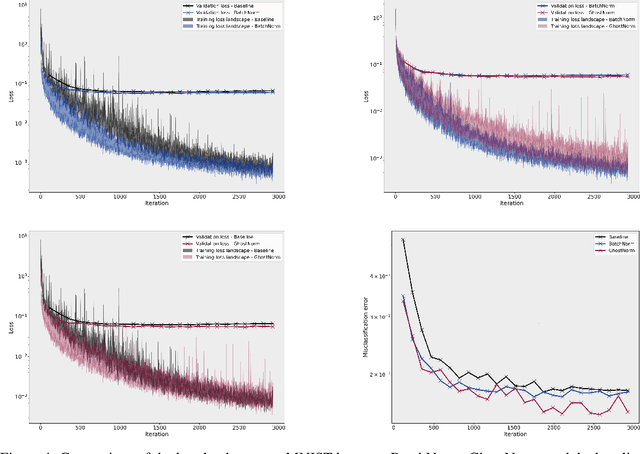
Batch normalization (BatchNorm) is an effective yet poorly understood technique for neural network optimization. It is often assumed that the degradation in BatchNorm performance to smaller batch sizes stems from it having to estimate layer statistics using smaller sample sizes. However, recently, Ghost normalization (GhostNorm), a variant of BatchNorm that explicitly uses smaller sample sizes for normalization, has been shown to improve upon BatchNorm in some datasets. Our contributions are: (i) we uncover a source of regularization that is unique to GhostNorm, and not simply an extension from BatchNorm, (ii) three types of GhostNorm implementations are described, two of which employ BatchNorm as the underlying normalization technique, (iii) by visualising the loss landscape of GhostNorm, we observe that GhostNorm consistently decreases the smoothness when compared to BatchNorm, (iv) we introduce Sequential Normalization (SeqNorm), and report superior performance over state-of-the-art methodologies on both CIFAR--10 and CIFAR--100 datasets.
Understanding Ancient Coin Images
Mar 13, 2019
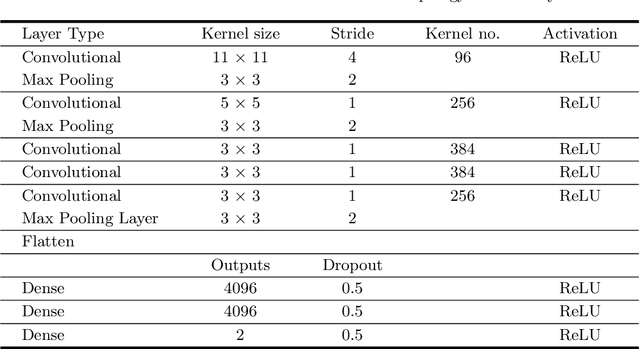

In recent years, a range of problems within the broad umbrella of automatic, computer vision based analysis of ancient coins has been attracting an increasing amount of attention. Notwithstanding this research effort, the results achieved by the state of the art in the published literature remain poor and far from sufficiently well performing for any practical purpose. In the present paper we present a series of contributions which we believe will benefit the interested community. Firstly, we explain that the approach of visual matching of coins, universally adopted in all existing published papers on the topic, is not of practical interest because the number of ancient coin types exceeds by far the number of those types which have been imaged, be it in digital form (e.g. online) or otherwise (traditional film, in print, etc.). Rather, we argue that the focus should be on the understanding of the semantic content of coins. Hence, we describe a novel method which uses real-world multimodal input to extract and associate semantic concepts with the correct coin images and then using a novel convolutional neural network learn the appearance of these concepts. Empirical evidence on a real-world and by far the largest data set of ancient coins, we demonstrate highly promising results.
Colorectal Cancer Outcome Prediction from H&E Whole Slide Images using Machine Learning and Automatically Inferred Phenotype Profiles
Mar 09, 2019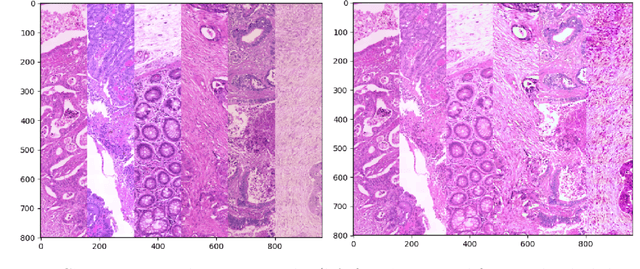

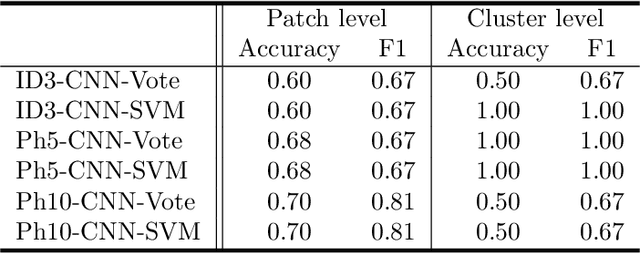
Digital pathology (DP) is a new research area which falls under the broad umbrella of health informatics. Owing to its potential for major public health impact, in recent years DP has been attracting much research attention. Nevertheless, a wide breadth of significant conceptual and technical challenges remain, few of them greater than those encountered in the field of oncology. The automatic analysis of digital pathology slides of cancerous tissues is particularly problematic due to the inherent heterogeneity of the disease, extremely large images, amongst numerous others. In this paper we introduce a novel machine learning based framework for the prediction of colorectal cancer outcome from whole digitized haematoxylin & eosin (H&E) stained histopathology slides. Using a real-world data set we demonstrate the effectiveness of the method and present a detailed analysis of its different elements which corroborate its ability to extract and learn salient, discriminative, and clinically meaningful content.
Synthesising Wider Field Images from Narrow-Field Retinal Video Acquired Using a Low-Cost Direct Ophthalmoscope (Arclight) Attached to a Smartphone
Aug 26, 2017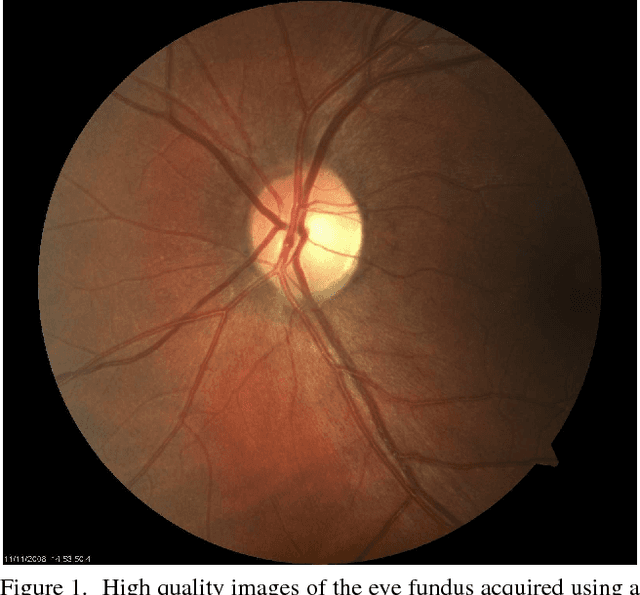
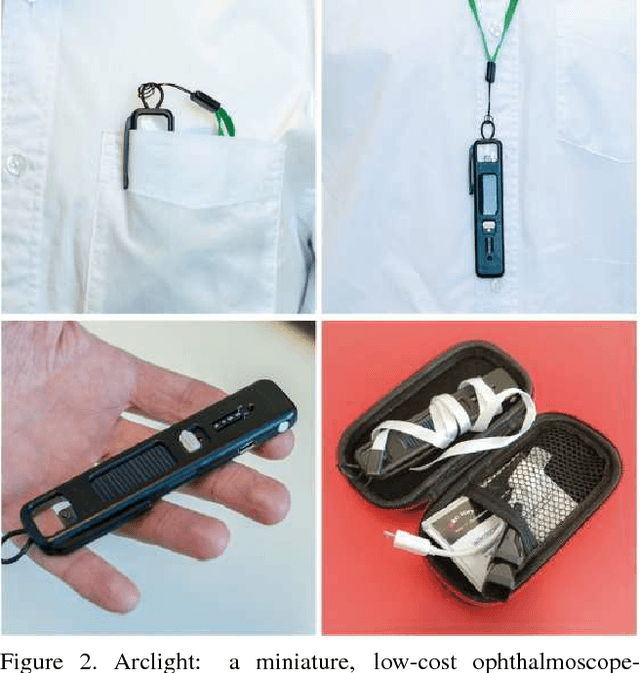
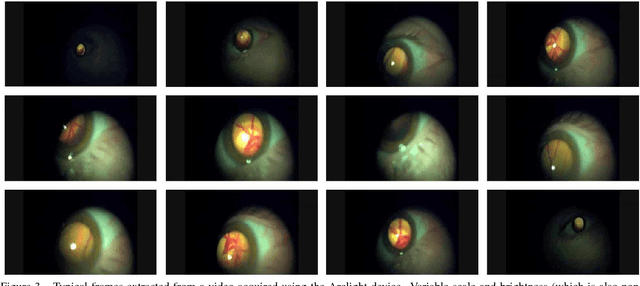

Access to low cost retinal imaging devices in low and middle income countries is limited, compromising progress in preventing needless blindness. The Arclight is a recently developed low-cost solar powered direct ophthalmoscope which can be attached to the camera of a smartphone to acquire retinal images and video. However, the acquired data is inherently limited by the optics of direct ophthalmoscopy, resulting in a narrow field of view with associated corneal reflections, limiting its usefulness. In this work we describe the first fully automatic method utilizing videos acquired using the Arclight attached to a mobile phone camera to create wider view, higher quality still images comparable with images obtained using much more expensive and bulky dedicated traditional retinal cameras.