 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Look at Ghost Normalization
Paper and Code
Jul 16, 2020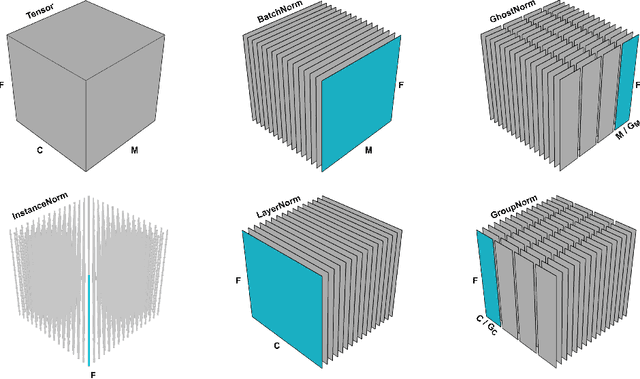
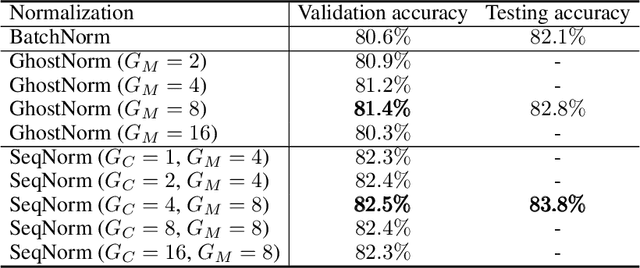

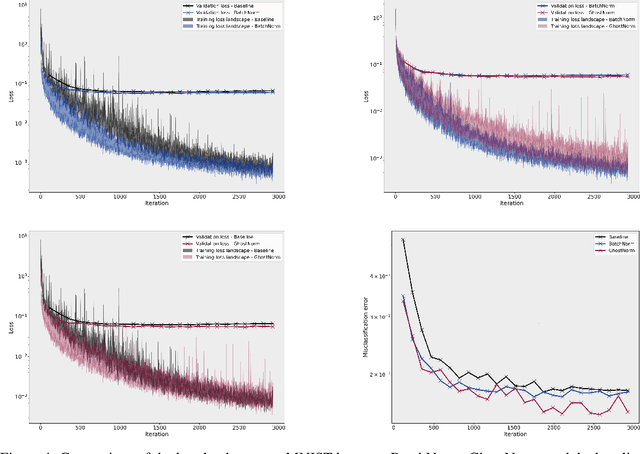
Batch normalization (BatchNorm) is an effective yet poorly understood technique for neural network optimization. It is often assumed that the degradation in BatchNorm performance to smaller batch sizes stems from it having to estimate layer statistics using smaller sample sizes. However, recently, Ghost normalization (GhostNorm), a variant of BatchNorm that explicitly uses smaller sample sizes for normalization, has been shown to improve upon BatchNorm in some datasets. Our contributions are: (i) we uncover a source of regularization that is unique to GhostNorm, and not simply an extension from BatchNorm, (ii) three types of GhostNorm implementations are described, two of which employ BatchNorm as the underlying normalization technique, (iii) by visualising the loss landscape of GhostNorm, we observe that GhostNorm consistently decreases the smoothness when compared to BatchNorm, (iv) we introduce Sequential Normalization (SeqNorm), and report superior performance over state-of-the-art methodologies on both CIFAR--10 and CIFAR--100 datasets.