 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Port Berth Identification from Automatic Identification System Data
May 17, 2025Port berthing sites are regions of high interest for monitoring and optimizing port operations. Data sourced from the Automatic Identification System (AIS) can be superimposed on berths enabling their real-time monitoring and revealing long-term utilization patterns. Ultimately, insights from multiple berths can uncover bottlenecks, and lead to the optimization of the underlying supply chain of the port and beyond. However, publicly available documentation of port berths, even when available, is frequently incomplete - e.g. there may be missing berths or inaccuracies such as incorrect boundary boxes - necessitating a more robust, data-driven approach to port berth localization. In this context, we propose an unsupervised spatial modeling method that leverages AIS data clustering and hyperparameter optimization to identify berthing sites. Trained on one month of freely available AIS data and evaluated across ports of varying sizes, our models significantly outperform competing methods, achieving a mean Bhattacharyya distance of 0.85 when comparing Gaussian Mixture Models (GMMs) trained on separate data splits, compared to 13.56 for the best existing method. Qualitative comparison with satellite images and existing berth labels further supports the superiority of our method, revealing more precise berth boundaries and improved spatial resolution across diverse port environments.
Magnifying Networks for Images with Billions of Pixels
Dec 12, 2021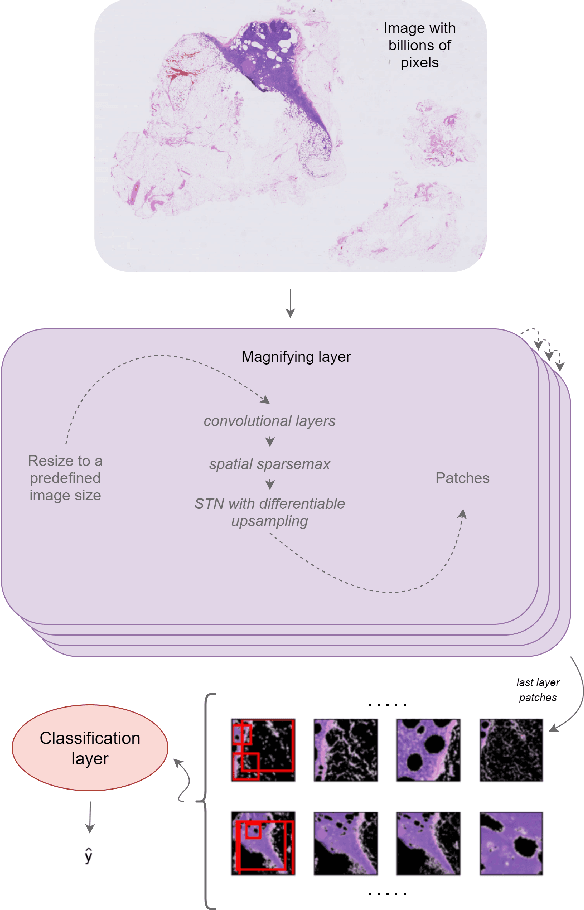
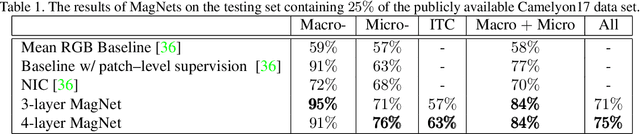
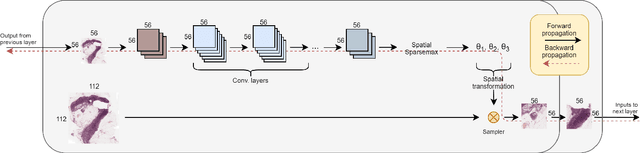

The shift towards end-to-end deep learning has brought unprecedented advances in many areas of computer vision. However, there are cases where the input images are excessively large, deeming end-to-end approaches impossible. In this paper, we introduce a new network, the Magnifying Network (MagNet), which can be trained end-to-end independently of the input image size. MagNets combine convolutional neural networks with differentiable spatial transformers, in a new way, to navigate and successfully learn from images with billions of pixels. Drawing inspiration from the magnifying nature of an ordinary brightfield microscope, a MagNet processes a downsampled version of an image, and without supervision learns how to identify areas that may carry value to the task at hand, upsamples them, and recursively repeats this process on each of the extracted patches. Our results on the publicly available Camelyon16 and Camelyon17 datasets first corroborate to the effectiveness of MagNets and the proposed optimization framework and second, demonstrate the advantage of Magnets' built-in transparency, an attribute of utmost importance for critical processes such as medical diagnosis.
A New Look at Ghost Normalization
Jul 16, 2020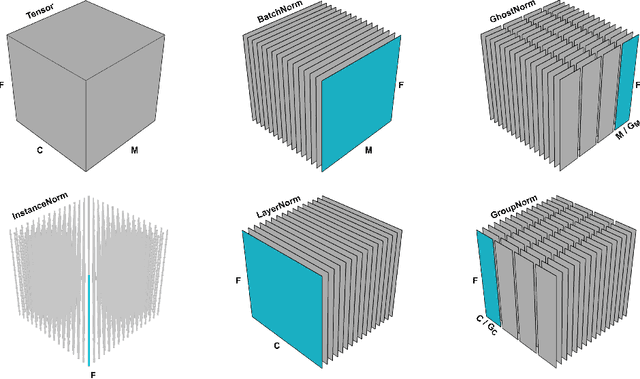
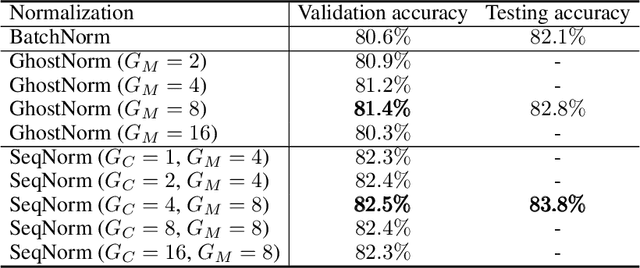

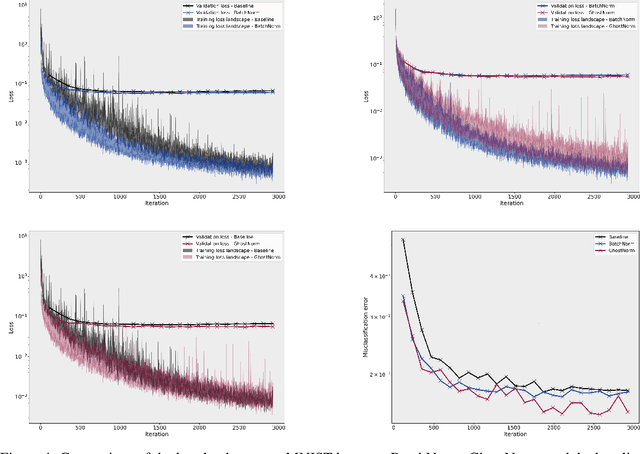
Batch normalization (BatchNorm) is an effective yet poorly understood technique for neural network optimization. It is often assumed that the degradation in BatchNorm performance to smaller batch sizes stems from it having to estimate layer statistics using smaller sample sizes. However, recently, Ghost normalization (GhostNorm), a variant of BatchNorm that explicitly uses smaller sample sizes for normalization, has been shown to improve upon BatchNorm in some datasets. Our contributions are: (i) we uncover a source of regularization that is unique to GhostNorm, and not simply an extension from BatchNorm, (ii) three types of GhostNorm implementations are described, two of which employ BatchNorm as the underlying normalization technique, (iii) by visualising the loss landscape of GhostNorm, we observe that GhostNorm consistently decreases the smoothness when compared to BatchNorm, (iv) we introduce Sequential Normalization (SeqNorm), and report superior performance over state-of-the-art methodologies on both CIFAR--10 and CIFAR--100 datasets.
Deep Learning for Whole Slide Image Analysis: An Overview
Oct 18, 2019
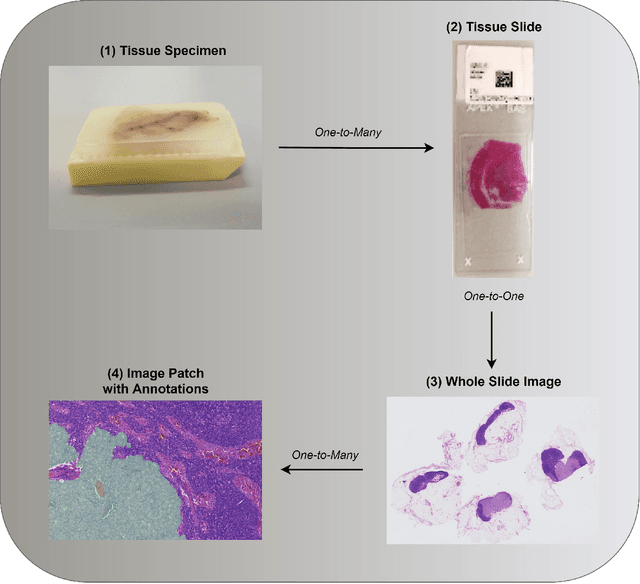
The widespread adoption of whole slide imaging has increased the demand for effective and efficient gigapixel image analysis. Deep learning is at the forefront of computer vision, showcasing significant improvements over previous methodologies on visual understanding. However, whole slide images have billions of pixels and suffer from high morphological heterogeneity as well as from different types of artefacts. Collectively, these impede the conventional use of deep learning. For the clinical translation of deep learning solutions to become a reality, these challenges need to be addressed. In this paper, we review work on the interdisciplinary attempt of training deep neural networks using whole slide images, and highlight the different ideas underlying these methodologies.
Colorectal Cancer Outcome Prediction from H&E Whole Slide Images using Machine Learning and Automatically Inferred Phenotype Profiles
Mar 09, 2019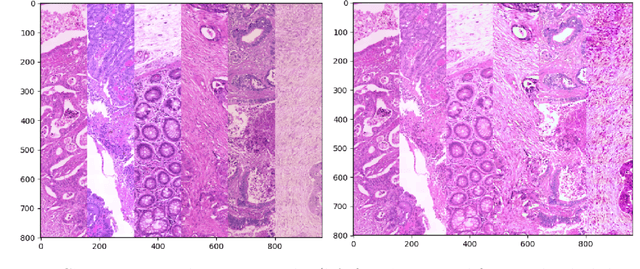

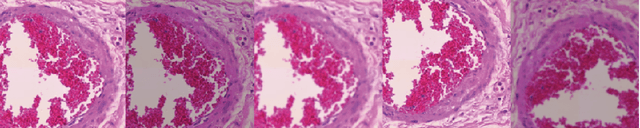
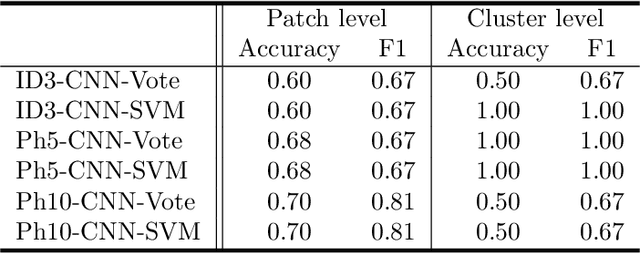
Digital pathology (DP) is a new research area which falls under the broad umbrella of health informatics. Owing to its potential for major public health impact, in recent years DP has been attracting much research attention. Nevertheless, a wide breadth of significant conceptual and technical challenges remain, few of them greater than those encountered in the field of oncology. The automatic analysis of digital pathology slides of cancerous tissues is particularly problematic due to the inherent heterogeneity of the disease, extremely large images, amongst numerous others. In this paper we introduce a novel machine learning based framework for the prediction of colorectal cancer outcome from whole digitized haematoxylin & eosin (H&E) stained histopathology slides. Using a real-world data set we demonstrate the effectiveness of the method and present a detailed analysis of its different elements which corroborate its ability to extract and learn salient, discriminative, and clinically meaningful content.