 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnifying Networks for Images with Billions of Pixels
Paper and Code
Dec 12, 2021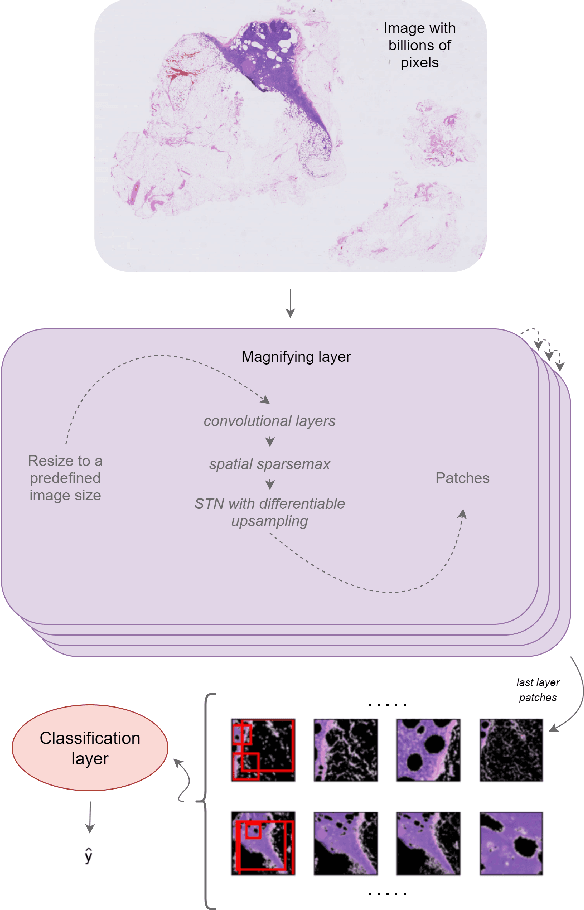
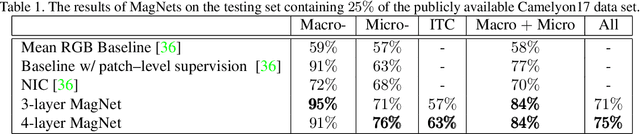
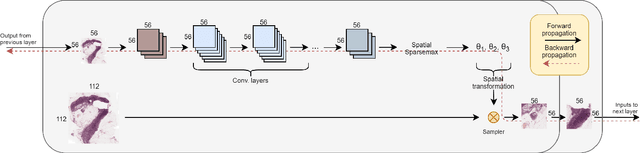

The shift towards end-to-end deep learning has brought unprecedented advances in many areas of computer vision. However, there are cases where the input images are excessively large, deeming end-to-end approaches impossible. In this paper, we introduce a new network, the Magnifying Network (MagNet), which can be trained end-to-end independently of the input image size. MagNets combine convolutional neural networks with differentiable spatial transformers, in a new way, to navigate and successfully learn from images with billions of pixels. Drawing inspiration from the magnifying nature of an ordinary brightfield microscope, a MagNet processes a downsampled version of an image, and without supervision learns how to identify areas that may carry value to the task at hand, upsamples them, and recursively repeats this process on each of the extracted patches. Our results on the publicly available Camelyon16 and Camelyon17 datasets first corroborate to the effectiveness of MagNets and the proposed optimization framework and second, demonstrate the advantage of Magnets' built-in transparency, an attribute of utmost importance for critical processes such as medical diagnosis.