 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWould I Lie To You? Inference Time Alignment of Language Models using Direct Preference Heads
May 30, 2024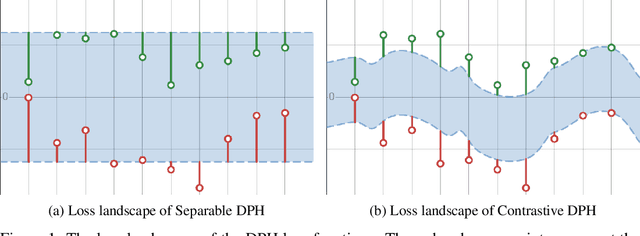
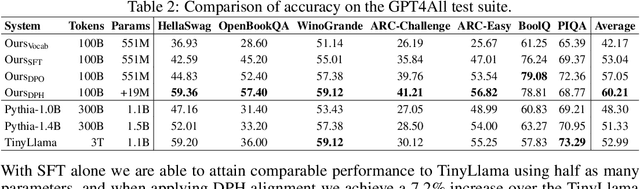
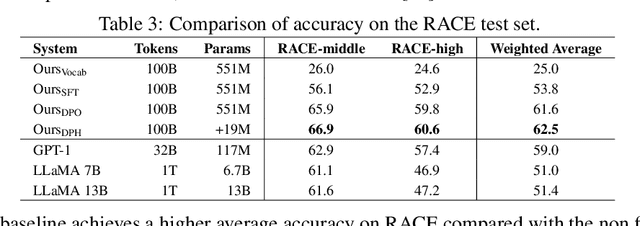
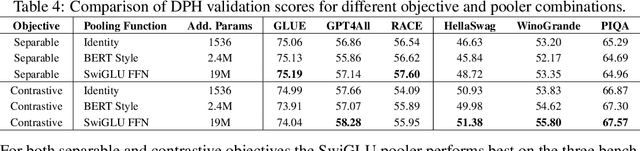
Pre-trained Language Models (LMs) exhibit strong zero-shot and in-context learning capabilities; however, their behaviors are often difficult to control. By utilizing Reinforcement Learning from Human Feedback (RLHF), it is possible to fine-tune unsupervised LMs to follow instructions and produce outputs that reflect human preferences. Despite its benefits, RLHF has been shown to potentially harm a language model's reasoning capabilities and introduce artifacts such as hallucinations where the model may fabricate facts. To address this issue we introduce Direct Preference Heads (DPH), a fine-tuning framework that enables LMs to learn human preference signals through an auxiliary reward head without directly affecting the output distribution of the language modeling head. We perform a theoretical analysis of our objective function and find strong ties to Conservative Direct Preference Optimization (cDPO). Finally we evaluate our models on GLUE, RACE, and the GPT4All evaluation suite and demonstrate that our method produces models which achieve higher scores than those fine-tuned with Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO) alone.
Context-PEFT: Efficient Multi-Modal, Multi-Task Fine-Tuning
Dec 14, 2023



This paper introduces a novel Parameter-Efficient Fine-Tuning (PEFT) framework for multi-modal, multi-task transfer learning with pre-trained language models. PEFT techniques such as LoRA, BitFit and IA3 have demonstrated comparable performance to full fine-tuning of pre-trained models for specific downstream tasks, all while demanding significantly fewer trainable parameters and reduced GPU memory consumption. However, in the context of multi-modal fine-tuning, the need for architectural modifications or full fine-tuning often becomes apparent. To address this we propose Context-PEFT, which learns different groups of adaptor parameters based on the token's domain. This approach enables LoRA-like weight injection without requiring additional architectural changes. Our method is evaluated on the COCO captioning task, where it outperforms full fine-tuning under similar data constraints while simultaneously offering a substantially more parameter-efficient and computationally economical solution.