 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving stable subspace clustering by post-processing generic clustering results
Paper and Code
May 27, 2016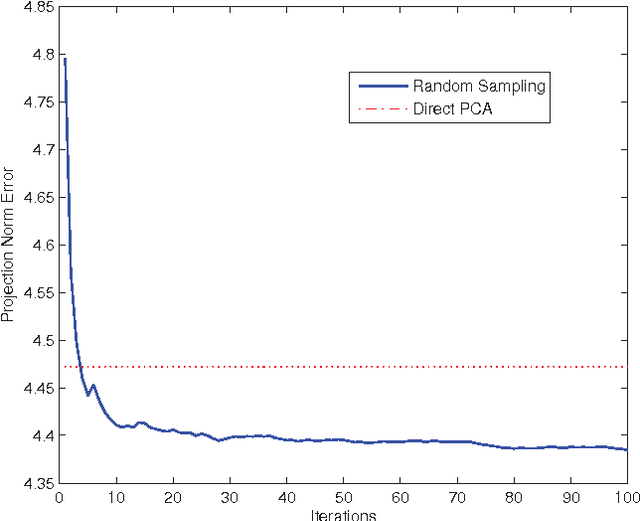
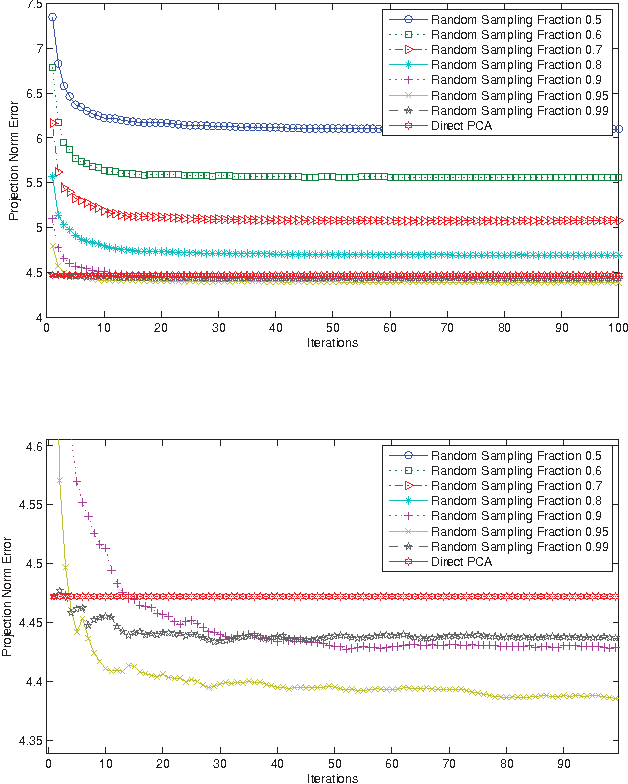
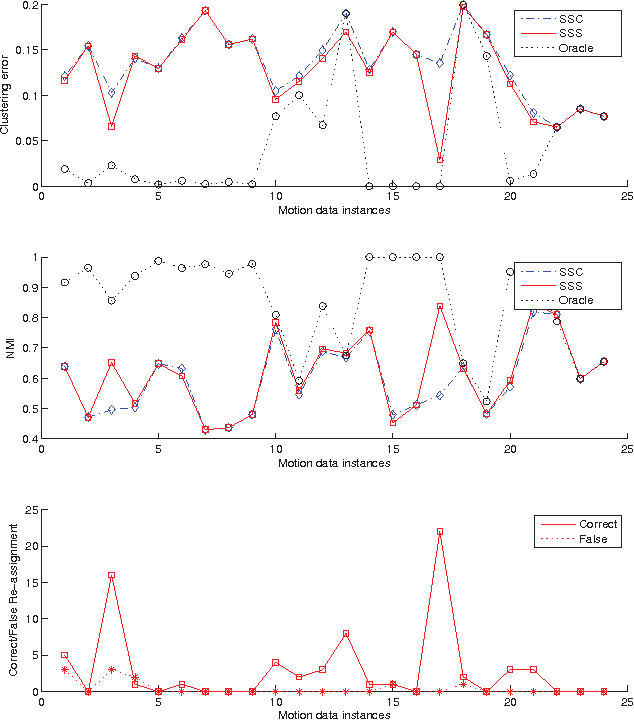
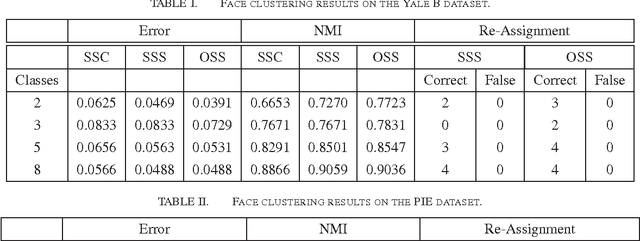
We propose an effective subspace selection scheme as a post-processing step to improve results obtained by sparse subspace clustering (SSC). Our method starts by the computation of stable subspaces using a novel random sampling scheme. Thus constructed preliminary subspaces are used to identify the initially incorrectly clustered data points and then to reassign them to more suitable clusters based on their goodness-of-fit to the preliminary model. To improve the robustness of the algorithm, we use a dominant nearest subspace classification scheme that controls the level of sensitivity against reassignment. We demonstrate that our algorithm is convergent and superior to the direct application of a generic alternative such as principal component analysis. On several popular datasets for motion segmentation and face clustering pervasively used in the sparse subspace clustering literature the proposed method is shown to reduce greatly the incidence of clustering errors while introducing negligible disturbance to the data points already correctly clustered.