 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus, Align, and Sustain: Counteracting Gradient Dilution in Incremental Object Detection
Jun 13, 2026Adapting Detection Transformers to Incremental Object Detection (IOD) poses a systemic challenge, as set-based optimization is inherently destabilized by sequential learning. In this work, we identify Gradient Dilution as the root cause of performance degradation, wherein optimization signals required to preserve old knowledge are progressively weakened. This phenomenon manifests as a cascading erosion of preservation gradients in magnitude, direction, and support coverage, driven by three tightly coupled factors: Signal Dispersion, where foreground gradients are overwhelmed by background noise; Assignment Drift, where stochastic query-target matching induces inconsistent gradient trajectories; and Support Attrition, where gradients from retained samples insufficiently cover the old-class feature space, weakening decision boundaries under interference from new classes. To counteract this, we propose FAS, a unified framework that Focuses, Aligns, and Sustains gradient flow throughout incremental learning. Specifically, we introduce prior-injected queries to focus discriminative signals by filtering background interference at the source. We further propose deterministic anchor distillation to align query-target assignments and enforce semantic consistency across stages under unstable matching. Finally, we devise manifold-support replay to sustain distributional support of old classes, counteracting representational erosion induced by continual updates. Extensive experiments show that FAS restores robust optimization dynamics and outperforms state-of-the-art methods, achieving over 5.0 AP improvement in the challenging 40+10x4 incremental setting.
A Benchmark for Semi-supervised Multi-modal Crowd Counting
Jun 02, 2026This paper constructs the first benchmark on semi-supervised multi-modal crowd counting. To lay the foundation for this unexplored task, we first formulate the semi-supervised multi-modal setting and a standardized protocol that specifies the labeled-unlabeled data partition across different labeled ratios. Next, to establish solid reference points, we carefully tailor a diverse set of representative baselines, including existing fully supervised multi-modal methods and semi-supervised single-modal methods. Then, we carefully evaluate their performance under our proposed benchmark. Codes and the data partition will be released on https://github.com/HenryCilence/Semi-supervised-Multimodal-Crowd-Counting.
Dance Across Shifts: Forward-Facilitation Continual Test-Time Adaptation through Dynamic Style Bridging
May 18, 2026Continual Test-Time Adaptation (CTTA) aims to empower perception systems to handle dynamic distribution shifts encountered after deployment. Existing methods predominantly follow a backward-alignment paradigm, which rigidly aligns incoming data with supervisory surrogates derived from the source domain. Consequently, they struggle with unreliable supervision and evolving distribution shifts. To overcome these limitations, we introduce a novel forward-facilitation paradigm through a method termed Dynamic Style Bridging. Prior to deployment, we construct a compact knowledge base of generated class exemplars. During test time, to mitigate inherent generative bias and adapt these proxies to incoming data, we propose a multi-level bridging mechanism. This mechanism dynamically injects the proxies with incoming data styles at the input, statistical, and representation levels, while preserving the original semantics of the proxies. These high-fidelity proxies are then used to provide reliable, on-demand supervisory signals, enabling stable adaptation under continual shifts. Extensive experiments across standard CTTA benchmarks demonstrate that our method achieves consistent and substantial improvements over recent state-of-the-art approaches. Code is available at \href{https://github.com/z1358/DAS}.
Robust Deepfake Detection, NTIRE 2026 Challenge: Report
Apr 27, 2026Robustness is a long-overlooked problem in deepfake detection. However, detection performance is nearly worthless in the real world if it suffers under exposure to even slight image degradation. In addition to weaker degradations that can accidentally occur in the image processing pipeline, there is another risk of malicious deepfakes that specifically introduce degradations, purposefully exploiting the detector's weaknesses in that regard. Here, we present an overview of the NTIRE 2026 Robust Deepfake Detection Challenge, which specifically addresses that problem. Participants were tasked with building a detector that would later be tested on an unknown test-set, which included both common and uncommon degradations of various strengths. With a total number of 337 participants and 57 submissions to the final leaderboard, the first edition of the challenge was well received. To ensure the reliability of the results, participants were given only 24h to complete the test run with no labels provided, limiting the possibility of training on the test data. Furthermore, the top solutions were scored on a private test-set to detect any such overfitting. This report presents the competition setting, dataset preparation, as well as details and performance of methods. Top methods rely on large foundation models, ensembles, and degradation training to combine generality and robustness.
Leave No Stone Unturned: Uncovering Holistic Audio-Visual Intrinsic Coherence for Deepfake Detection
Mar 25, 2026The rapid progress of generative AI has enabled hyper-realistic audio-visual deepfakes, intensifying threats to personal security and social trust. Most existing deepfake detectors rely either on uni-modal artifacts or audio-visual discrepancies, failing to jointly leverage both sources of information. Moreover, detectors that rely on generator-specific artifacts tend to exhibit degraded generalization when confronted with unseen forgeries. We argue that robust and generalizable detection should be grounded in intrinsic audio-visual coherence within and across modalities. Accordingly, we propose HAVIC, a Holistic Audio-Visual Intrinsic Coherence-based deepfake detector. HAVIC first learns priors of modality-specific structural coherence, inter-modal micro- and macro-coherence by pre-training on authentic videos. Based on the learned priors, HAVIC further performs holistic adaptive aggregation to dynamically fuse audio-visual features for deepfake detection. Additionally, we introduce HiFi-AVDF, a high-fidelity audio-visual deepfake dataset featuring both text-to-video and image-to-video forgeries from state-of-the-art commercial generators. Extensive experiments across several benchmarks demonstrate that HAVIC significantly outperforms existing state-of-the-art methods, achieving improvements of 9.39% AP and 9.37% AUC on the most challenging cross-dataset scenario. Our code and dataset are available at https://github.com/tuffy-studio/HAVIC.
Cluster-Wise Spatio-Temporal Masking for Efficient Video-Language Pretraining
Mar 24, 2026Large-scale video-language pretraining enables strong generalization across multimodal tasks but often incurs prohibitive computational costs. Although recent advances in masked visual modeling help mitigate this issue, they still suffer from two fundamental limitations: severe visual information loss under high masking ratios and temporal information leakage caused by inter-frame correlations. To address these challenges, we propose ClusterSTM, a Cluster-Wise Spatio-Temporal Masking strategy for efficient video-language pretraining. ClusterSTM first performs intra-frame clustering to partition visual tokens into multiple semantically independent clusters, then conducts cluster-wise masking by retaining the token with the highest temporal density within each cluster. Our masking strategy ensure that the retained tokens capture holistic video content while exhibit strong temporal correlation. Additionally, we introduce a video-text relevance reconstruction objective that aligns high-level multimodal semantics beyond conventional visual reconstruction. Extensive experiments across multiple benchmarks demonstrate that ClusterSTM achieves superior performance on video-text retrieval, video question answering, and video captioning tasks, establishing a new state-of-the-art among efficient video-language models.
2D Gaussians Spatial Transport for Point-supervised Density Regression
Nov 18, 2025



This paper introduces Gaussian Spatial Transport (GST), a novel framework that leverages Gaussian splatting to facilitate transport from the probability measure in the image coordinate space to the annotation map. We propose a Gaussian splatting-based method to estimate pixel-annotation correspondence, which is then used to compute a transport plan derived from Bayesian probability. To integrate the resulting transport plan into standard network optimization in typical computer vision tasks, we derive a loss function that measures discrepancy after transport. Extensive experiments on representative computer vision tasks, including crowd counting and landmark detection, validate the effectiveness of our approach. Compared to conventional optimal transport schemes, GST eliminates iterative transport plan computation during training, significantly improving efficiency. Code is available at https://github.com/infinite0522/GST.
MEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
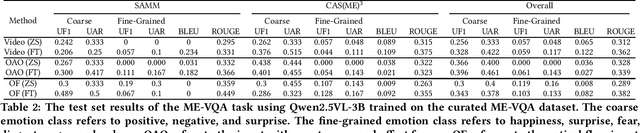
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
Grounding-MD: Grounded Video-language Pre-training for Open-World Moment Detection
Apr 20, 2025Temporal Action Detection and Moment Retrieval constitute two pivotal tasks in video understanding, focusing on precisely localizing temporal segments corresponding to specific actions or events. Recent advancements introduced Moment Detection to unify these two tasks, yet existing approaches remain confined to closed-set scenarios, limiting their applicability in open-world contexts. To bridge this gap, we present Grounding-MD, an innovative, grounded video-language pre-training framework tailored for open-world moment detection. Our framework incorporates an arbitrary number of open-ended natural language queries through a structured prompt mechanism, enabling flexible and scalable moment detection. Grounding-MD leverages a Cross-Modality Fusion Encoder and a Text-Guided Fusion Decoder to facilitate comprehensive video-text alignment and enable effective cross-task collaboration. Through large-scale pre-training on temporal action detection and moment retrieval datasets, Grounding-MD demonstrates exceptional semantic representation learning capabilities, effectively handling diverse and complex query conditions. Comprehensive evaluations across four benchmark datasets including ActivityNet, THUMOS14, ActivityNet-Captions, and Charades-STA demonstrate that Grounding-MD establishes new state-of-the-art performance in zero-shot and supervised settings in open-world moment detection scenarios. All source code and trained models will be released.
OpenSDI: Spotting Diffusion-Generated Images in the Open World
Mar 25, 2025This paper identifies OpenSDI, a challenge for spotting diffusion-generated images in open-world settings. In response to this challenge, we define a new benchmark, the OpenSDI dataset (OpenSDID), which stands out from existing datasets due to its diverse use of large vision-language models that simulate open-world diffusion-based manipulations. Another outstanding feature of OpenSDID is its inclusion of both detection and localization tasks for images manipulated globally and locally by diffusion models. To address the OpenSDI challenge, we propose a Synergizing Pretrained Models (SPM) scheme to build up a mixture of foundation models. This approach exploits a collaboration mechanism with multiple pretrained foundation models to enhance generalization in the OpenSDI context, moving beyond traditional training by synergizing multiple pretrained models through prompting and attending strategies. Building on this scheme, we introduce MaskCLIP, an SPM-based model that aligns Contrastive Language-Image Pre-Training (CLIP) with Masked Autoencoder (MAE). Extensive evaluations on OpenSDID show that MaskCLIP significantly outperforms current state-of-the-art methods for the OpenSDI challenge, achieving remarkable relative improvements of 14.23% in IoU (14.11% in F1) and 2.05% in accuracy (2.38% in F1) compared to the second-best model in localization and detection tasks, respectively. Our dataset and code are available at https://github.com/iamwangyabin/OpenSDI.