 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSACA: Selective Attention-Based Clustering Algorithm
Aug 23, 2025Clustering algorithms are widely used in various applications, with density-based methods such as Density-Based Spatial Clustering of Applications with Noise (DBSCAN) being particularly prominent. These algorithms identify clusters in high-density regions while treating sparser areas as noise. However, reliance on user-defined parameters often poses optimization challenges that require domain expertise. This paper presents a novel density-based clustering method inspired by the concept of selective attention, which minimizes the need for user-defined parameters under standard conditions. Initially, the algorithm operates without requiring user-defined parameters. If parameter adjustment is needed, the method simplifies the process by introducing a single integer parameter that is straightforward to tune. The approach computes a threshold to filter out the most sparsely distributed points and outliers, forms a preliminary cluster structure, and then reintegrates the excluded points to finalize the results. Experimental evaluations on diverse data sets highlight the accessibility and robust performance of the method, providing an effective alternative for density-based clustering tasks.
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025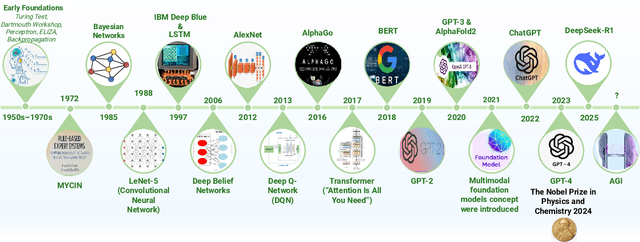
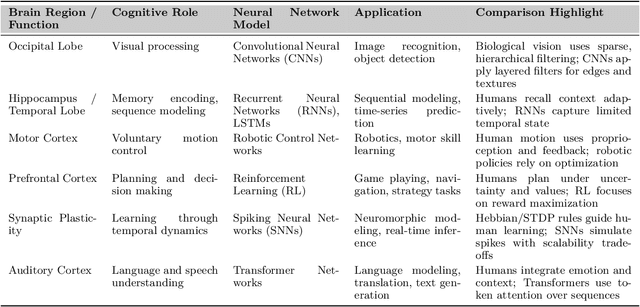
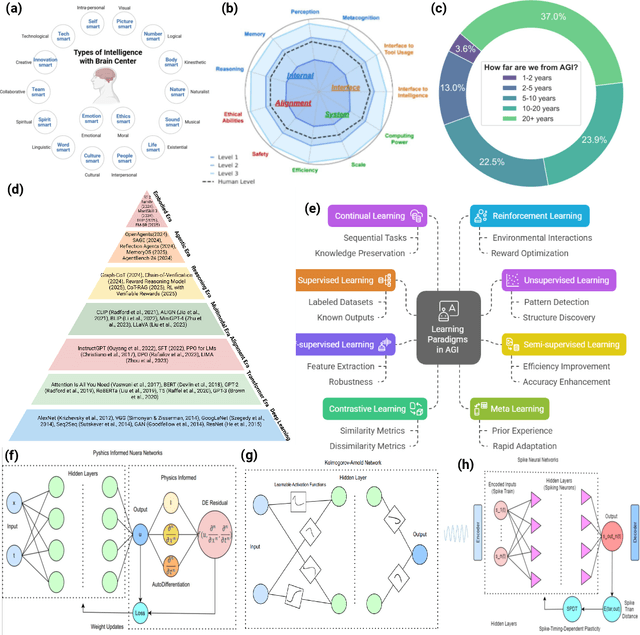
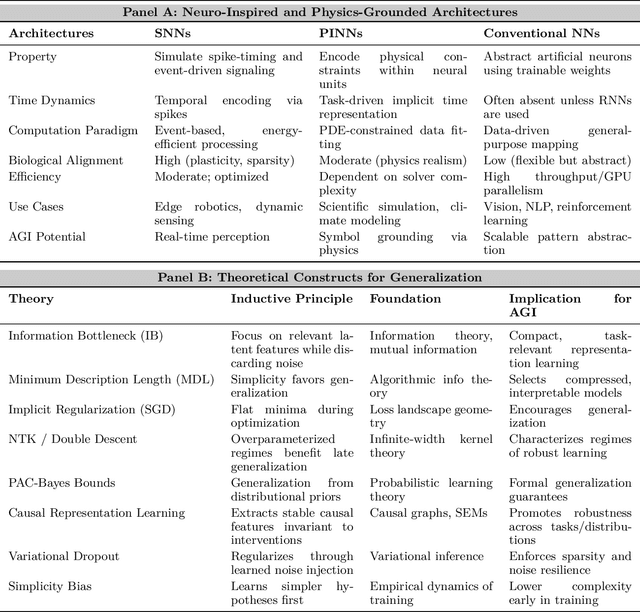
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
MEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
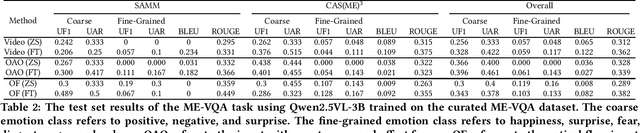
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
ViTime: A Visual Intelligence-Based Foundation Model for Time Series Forecasting
Jul 10, 2024



The success of large pretrained models in natural language processing (NLP) and computer vision (CV) has opened new avenues for constructing foundation models for time series forecasting (TSF). Traditional TSF foundation models rely heavily on numerical data fitting. In contrast, the human brain is inherently skilled at processing visual information, prefer predicting future trends by observing visualized sequences. From a biomimetic perspective, utilizing models to directly process numerical sequences might not be the most effective route to achieving Artificial General Intelligence (AGI). This paper proposes ViTime, a novel Visual Intelligence-based foundation model for TSF. ViTime overcomes the limitations of numerical time series data fitting by utilizing visual data processing paradigms and employs a innovative data synthesis method during training, called Real Time Series (RealTS). Experiments on a diverse set of previously unseen forecasting datasets demonstrate that ViTime achieves state-of-the-art zero-shot performance, even surpassing the best individually trained supervised models in some situations. These findings suggest that visual intelligence can significantly enhance time series analysis and forecasting, paving the way for more advanced and versatile models in the field. The code for our framework is accessible at https://github.com/IkeYang/ViTime.
Your time series is worth a binary image: machine vision assisted deep framework for time series forecasting
Feb 28, 2023

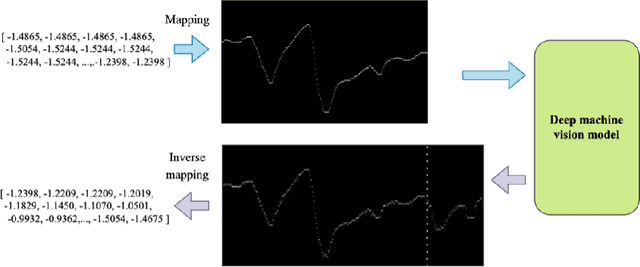

Time series forecasting (TSF) has been a challenging research area, and various models have been developed to address this task. However, almost all these models are trained with numerical time series data, which is not as effectively processed by the neural system as visual information. To address this challenge, this paper proposes a novel machine vision assisted deep time series analysis (MV-DTSA) framework. The MV-DTSA framework operates by analyzing time series data in a novel binary machine vision time series metric space, which includes a mapping and an inverse mapping function from the numerical time series space to the binary machine vision space, and a deep machine vision model designed to address the TSF task in the binary space. A comprehensive computational analysis demonstrates that the proposed MV-DTSA framework outperforms state-of-the-art deep TSF models, without requiring sophisticated data decomposition or model customization. The code for our framework is accessible at https://github.com/IkeYang/ machine-vision-assisted-deep-time-series-analysis-MV-DTSA-.
Spatial and Temporal Networks for Facial Expression Recognition in the Wild Videos
Jul 12, 2021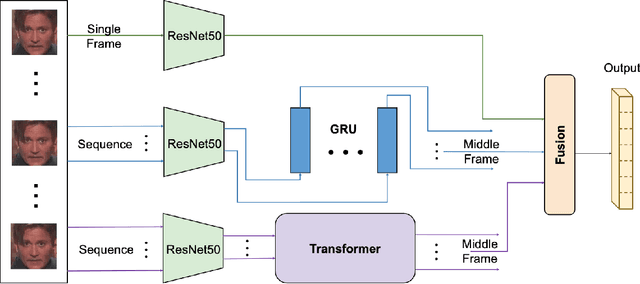
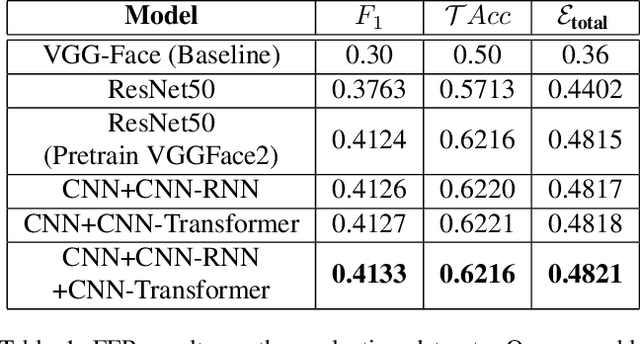
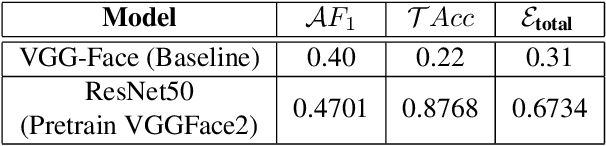
The paper describes our proposed methodology for the seven basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2021. In this task, facial expression recognition (FER) methods aim to classify the correct expression category from a diverse background, but there are several challenges. First, to adapt the model to in-the-wild scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose an ensemble model with a convolution neural network (CNN), a CNN-recurrent neural network (CNN-RNN), and a CNN-Transformer (CNN-Transformer), to incorporate both spatial and temporal information. Our ensemble model achieved F1 as 0.4133, accuracy as 0.6216 and final metric as 0.4821 on the validation set.
RetinaMask: A Face Mask detector
Jun 08, 2020
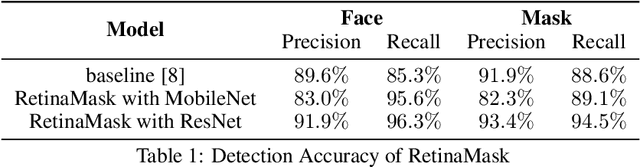
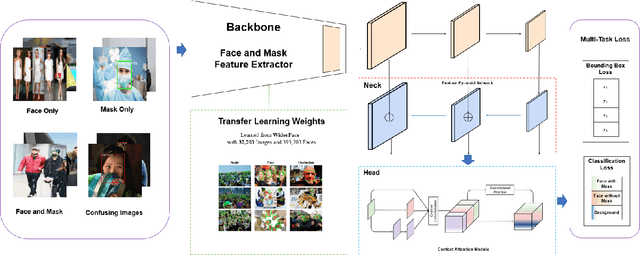
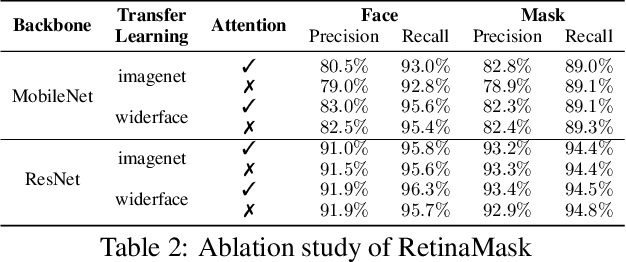
Coronavirus disease 2019 has affected the world seriously. One major protection method for people is to wear masks in public areas. Furthermore, many public service providers require customers to use the service only if they wear masks correctly. However, there are only a few research studies about face mask detection based on image analysis. In this paper, we propose RetinaFaceMask, which is a high-accuracy and efficient face mask detector. The proposed RetinaFaceMask is a one-stage detector, which consists of a feature pyramid network to fuse high-level semantic information with multiple feature maps, and a novel context attention module to focus on detecting face masks. In addition, we also propose a novel cross-class object removal algorithm to reject predictions with low confidences and the high intersection of union. Experiment results show that RetinaFaceMask achieves state-of-the-art results on a public face mask dataset with $2.3\%$ and $1.5\%$ higher than the baseline result in the face and mask detection precision, respectively, and $11.0\%$ and $5.9\%$ higher than baseline for recall. Besides, we also explore the possibility of implementing RetinaFaceMask with a light-weighted neural network MobileNet for embedded or mobile devices.