 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo in One Go: Single-stage Emotion Recognition with Decoupled Subject-context Transformer
Apr 29, 2024Emotion recognition aims to discern the emotional state of subjects within an image, relying on subject-centric and contextual visual cues. Current approaches typically follow a two-stage pipeline: first localize subjects by off-the-shelf detectors, then perform emotion classification through the late fusion of subject and context features. However, the complicated paradigm suffers from disjoint training stages and limited interaction between fine-grained subject-context elements. To address the challenge, we present a single-stage emotion recognition approach, employing a Decoupled Subject-Context Transformer (DSCT), for simultaneous subject localization and emotion classification. Rather than compartmentalizing training stages, we jointly leverage box and emotion signals as supervision to enrich subject-centric feature learning. Furthermore, we introduce DSCT to facilitate interactions between fine-grained subject-context cues in a decouple-then-fuse manner. The decoupled query token--subject queries and context queries--gradually intertwine across layers within DSCT, during which spatial and semantic relations are exploited and aggregated. We evaluate our single-stage framework on two widely used context-aware emotion recognition datasets, CAER-S and EMOTIC. Our approach surpasses two-stage alternatives with fewer parameter numbers, achieving a 3.39% accuracy improvement and a 6.46% average precision gain on CAER-S and EMOTIC datasets, respectively.
3D Landmark Detection on Human Point Clouds: A Benchmark and A Dual Cascade Point Transformer Framework
Jan 14, 2024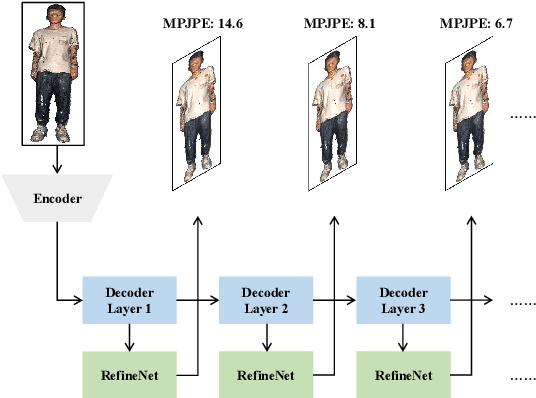
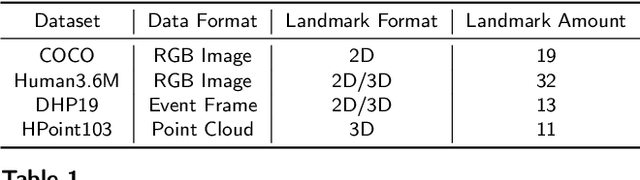
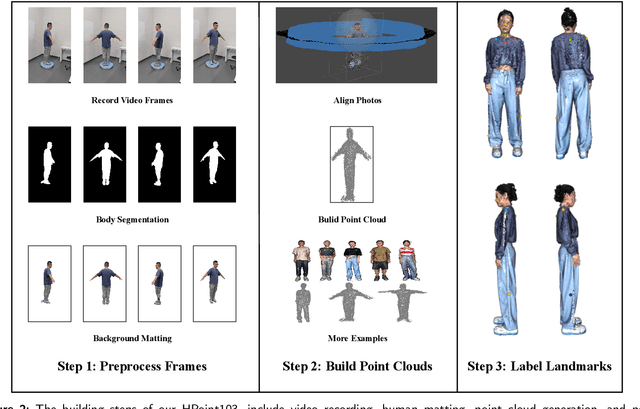
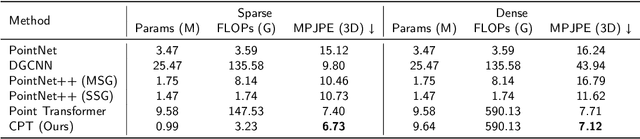
3D landmark detection plays a pivotal role in various applications such as 3D registration, pose estimation, and virtual try-on. While considerable success has been achieved in 2D human landmark detection or pose estimation, there is a notable scarcity of reported works on landmark detection in unordered 3D point clouds. This paper introduces a novel challenge, namely 3D landmark detection on human point clouds, presenting two primary contributions. Firstly, we establish a comprehensive human point cloud dataset, named HPoint103, designed to support the 3D landmark detection community. This dataset comprises 103 human point clouds created with commercial software and actors, each manually annotated with 11 stable landmarks. Secondly, we propose a Dual Cascade Point Transformer (D-CPT) model for precise point-based landmark detection. D-CPT gradually refines the landmarks through cascade Transformer decoder layers across the entire point cloud stream, simultaneously enhancing landmark coordinates with a RefineNet over local regions. Comparative evaluations with popular point-based methods on HPoint103 and the public dataset DHP19 demonstrate the dramatic outperformance of our D-CPT. Additionally, the integration of our RefineNet into existing methods consistently improves performance.
AU-Aware Vision Transformers for Biased Facial Expression Recognition
Nov 12, 2022



Studies have proven that domain bias and label bias exist in different Facial Expression Recognition (FER) datasets, making it hard to improve the performance of a specific dataset by adding other datasets. For the FER bias issue, recent researches mainly focus on the cross-domain issue with advanced domain adaption algorithms. This paper addresses another problem: how to boost FER performance by leveraging cross-domain datasets. Unlike the coarse and biased expression label, the facial Action Unit (AU) is fine-grained and objective suggested by psychological studies. Motivated by this, we resort to the AU information of different FER datasets for performance boosting and make contributions as follows. First, we experimentally show that the naive joint training of multiple FER datasets is harmful to the FER performance of individual datasets. We further introduce expression-specific mean images and AU cosine distances to measure FER dataset bias. This novel measurement shows consistent conclusions with experimental degradation of joint training. Second, we propose a simple yet conceptually-new framework, AU-aware Vision Transformer (AU-ViT). It improves the performance of individual datasets by jointly training auxiliary datasets with AU or pseudo-AU labels. We also find that the AU-ViT is robust to real-world occlusions. Moreover, for the first time, we prove that a carefully-initialized ViT achieves comparable performance to advanced deep convolutional networks. Our AU-ViT achieves state-of-the-art performance on three popular datasets, namely 91.10% on RAF-DB, 65.59% on AffectNet, and 90.15% on FERPlus. The code and models will be released soon.
AU-Supervised Convolutional Vision Transformers for Synthetic Facial Expression Recognition
Jul 22, 2022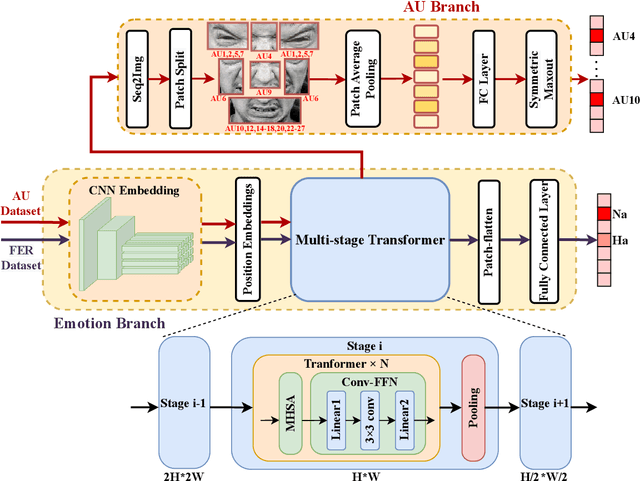
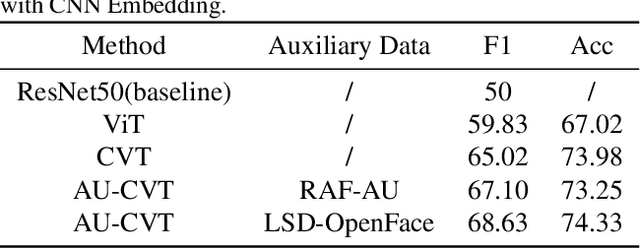
The paper describes our proposed methodology for the six basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2022. In Learing from Synthetic Data(LSD) task, facial expression recognition (FER) methods aim to learn the representation of expression from the artificially generated data and generalise to real data. Because of the ambiguous of the synthetic data and the objectivity of the facial Action Unit (AU), we resort to the AU information for performance boosting, and make contributions as follows. First, to adapt the model to synthetic scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose a conceptually-new framework, termed as AU-Supervised Convolutional Vision Transformers (AU-CVT), which clearly improves the performance of FER by jointly training auxiliary datasets with AU or pseudo AU labels. Our AU-CVT achieved F1 score as $0.6863$, accuracy as $0.7433$ on the validation set. The source code of our work is publicly available online: https://github.com/msy1412/ABAW4
Spatial and Temporal Networks for Facial Expression Recognition in the Wild Videos
Jul 12, 2021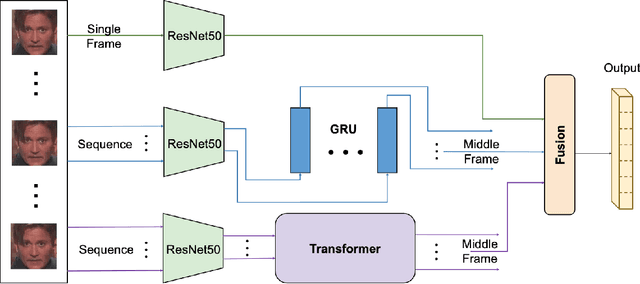
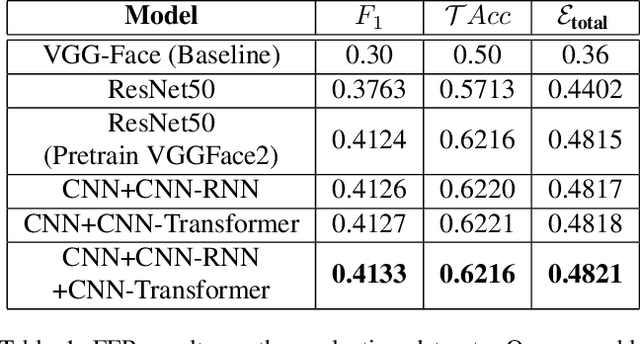
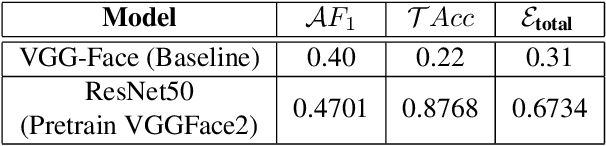
The paper describes our proposed methodology for the seven basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2021. In this task, facial expression recognition (FER) methods aim to classify the correct expression category from a diverse background, but there are several challenges. First, to adapt the model to in-the-wild scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose an ensemble model with a convolution neural network (CNN), a CNN-recurrent neural network (CNN-RNN), and a CNN-Transformer (CNN-Transformer), to incorporate both spatial and temporal information. Our ensemble model achieved F1 as 0.4133, accuracy as 0.6216 and final metric as 0.4821 on the validation set.