 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNutrifyAI: An AI-Powered System for Real-Time Food Detection, Nutritional Analysis, and Personalized Meal Recommendations
Aug 20, 2024



With diet and nutrition apps reaching 1.4 billion users in 2022 [1], it's no surprise that health apps like MyFitnessPal, Noom, and Calorie Counter, are surging in popularity. However, one major setback [2] of nearly all nutrition applications is that users must enter food data manually, which is time-consuming and tedious. Thus, there has been an increasing demand for applications that can accurately identify food items, analyze their nutritional content, and offer dietary recommendations in real-time. This paper introduces a comprehensive system that combines advanced computer vision techniques with nutrition analysis, implemented in a versatile mobile and web application. The system is divided into three key components: 1) food detection using the YOLOv8 model, 2) nutrient analysis via the Edamam Nutrition Analysis API, and 3) personalized meal recommendations using the Edamam Meal Planning and Recipe Search APIs. Designed for both mobile and web platforms, the application ensures fast processing times with an intuitive user interface, with features such as data visualizations using Chart.js, a login system, and personalized settings for dietary preferences, allergies, and cuisine choices. Preliminary results showcase the system's effectiveness, making it a valuable tool for users to make informed dietary decisions.
AU-Supervised Convolutional Vision Transformers for Synthetic Facial Expression Recognition
Jul 22, 2022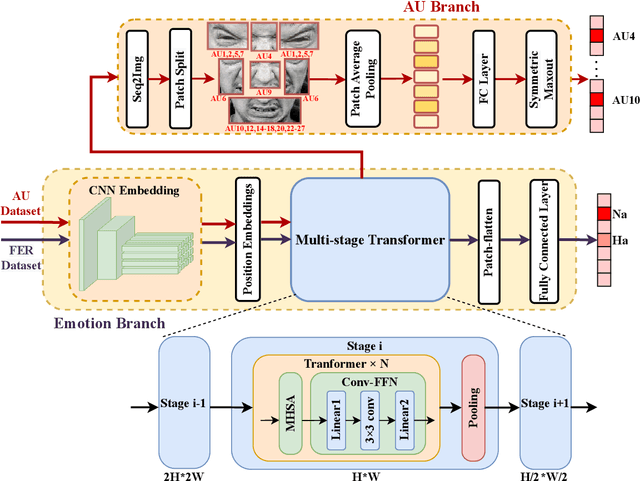
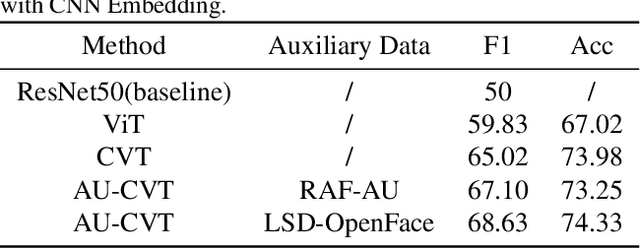
The paper describes our proposed methodology for the six basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2022. In Learing from Synthetic Data(LSD) task, facial expression recognition (FER) methods aim to learn the representation of expression from the artificially generated data and generalise to real data. Because of the ambiguous of the synthetic data and the objectivity of the facial Action Unit (AU), we resort to the AU information for performance boosting, and make contributions as follows. First, to adapt the model to synthetic scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose a conceptually-new framework, termed as AU-Supervised Convolutional Vision Transformers (AU-CVT), which clearly improves the performance of FER by jointly training auxiliary datasets with AU or pseudo AU labels. Our AU-CVT achieved F1 score as $0.6863$, accuracy as $0.7433$ on the validation set. The source code of our work is publicly available online: https://github.com/msy1412/ABAW4