 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation of common and internal carotid arteries from 3D ultrasound images using adaptive triple U-Net
Feb 09, 2021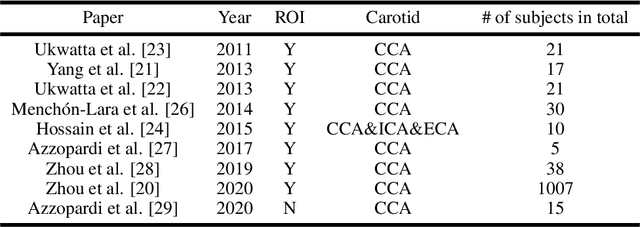
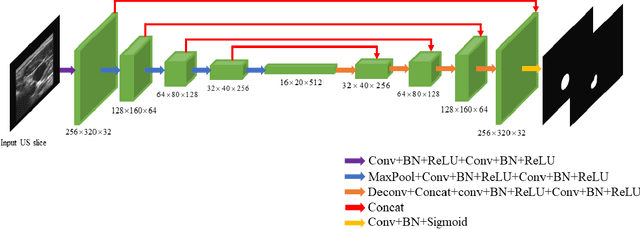
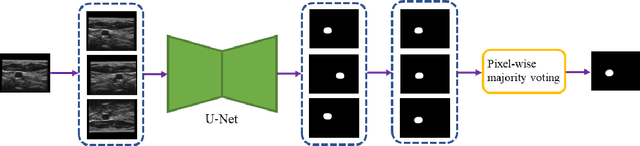
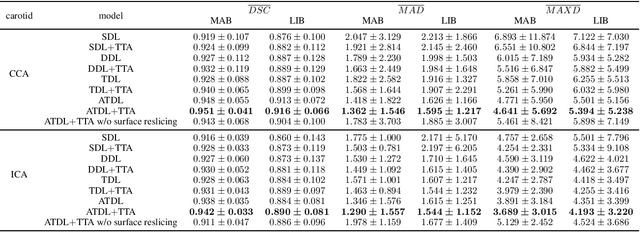
Objective: Vessel-wall-volume (VWV) and localized vessel-wall-thickness (VWT) measured from 3D ultrasound (US) carotid images are sensitive to anti-atherosclerotic effects of medical/dietary treatments. VWV and VWT measurements require the lumen-intima (LIB) and media-adventitia boundaries (MAB) at the common and internal carotid arteries (CCA and ICA). However, most existing segmentation techniques were capable of automating only CCA segmentation. An approach capable of segmenting the MAB and LIB from the CCA and ICA was required to accelerate VWV and VWT quantification. Methods: Segmentation for CCA and ICA were performed independently using the proposed two-channel U-Net, which was driven by a novel loss function known as the adaptive triple Dice loss (ADTL). A test-time augmentation (TTA) approach is used, in which segmentation was performed three times based on axial images and its flipped versions; the final segmentation was generated by pixel-wise majority voting. Results: Experiments involving 224 3DUS volumes produce a Dice-similarity-coefficient (DSC) of 95.1%$\pm$4.1% and 91.6%$\pm$6.6% for the MAB and LIB, in the CCA, respectively, and 94.2%$\pm$3.3% and 89.0%$\pm$8.1% for the MAB and LIB, in the ICA, respectively. TTA and ATDL independently contributed to a statistically significant improvement to all boundaries except the LIB in ICA. The total time required to segment the entire 3DUS volume (CCA+ICA) is 1.4s. Conclusion: The proposed two-channel U-Net with ADTL and TTA can segment the CCA and ICA accurately and efficiently from the 3DUS volume. Significance: Our approach has the potential to accelerate the transition of 3DUS measurements of carotid atherosclerosis to clinical research.
RetinaMask: A Face Mask detector
Jun 08, 2020
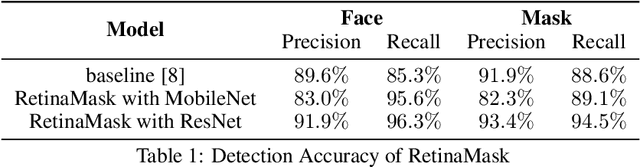
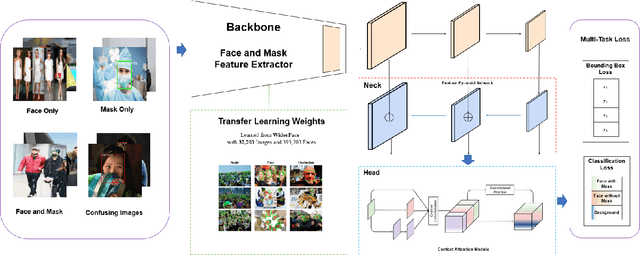
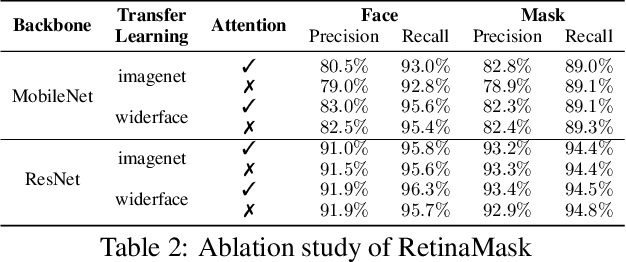
Coronavirus disease 2019 has affected the world seriously. One major protection method for people is to wear masks in public areas. Furthermore, many public service providers require customers to use the service only if they wear masks correctly. However, there are only a few research studies about face mask detection based on image analysis. In this paper, we propose RetinaFaceMask, which is a high-accuracy and efficient face mask detector. The proposed RetinaFaceMask is a one-stage detector, which consists of a feature pyramid network to fuse high-level semantic information with multiple feature maps, and a novel context attention module to focus on detecting face masks. In addition, we also propose a novel cross-class object removal algorithm to reject predictions with low confidences and the high intersection of union. Experiment results show that RetinaFaceMask achieves state-of-the-art results on a public face mask dataset with $2.3\%$ and $1.5\%$ higher than the baseline result in the face and mask detection precision, respectively, and $11.0\%$ and $5.9\%$ higher than baseline for recall. Besides, we also explore the possibility of implementing RetinaFaceMask with a light-weighted neural network MobileNet for embedded or mobile devices.