 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated Tip-and-Cue Framework for Optimized Satellite Tasking and Visual Intelligence
Dec 10, 2025The proliferation of satellite constellations, coupled with reduced tasking latency and diverse sensor capabilities, has expanded the opportunities for automated Earth observation. This paper introduces a fully automated Tip-and-Cue framework designed for satellite imaging tasking and scheduling. In this context, tips are generated from external data sources or analyses of prior satellite imagery, identifying spatiotemporal targets and prioritizing them for downstream planning. Corresponding cues are the imaging tasks formulated in response, which incorporate sensor constraints, timing requirements, and utility functions. The system autonomously generates candidate tasks, optimizes their scheduling across multiple satellites using continuous utility functions that reflect the expected value of each observation, and processes the resulting imagery using artificial-intelligence-based models, including object detectors and vision-language models. Structured visual reports are generated to support both interpretability and the identification of new insights for downstream tasking. The efficacy of the framework is demonstrated through a maritime vessel tracking scenario, utilizing Automatic Identification System (AIS) data for trajectory prediction, targeted observations, and the generation of actionable outputs. Maritime vessel tracking is a widely researched application, often used to benchmark novel approaches to satellite tasking, forecasting, and analysis. The system is extensible to broader applications such as smart-city monitoring and disaster response, where timely tasking and automated analysis are critical.
A Framework for Robust Speaker Verification in Highly Noisy Environments Leveraging Both Noisy and Enhanced Audio
Aug 26, 2025Recent advancements in speaker verification techniques show promise, but their performance often deteriorates significantly in challenging acoustic environments. Although speech enhancement methods can improve perceived audio quality, they may unintentionally distort speaker-specific information, which can affect verification accuracy. This problem has become more noticeable with the increasing use of generative deep neural networks (DNNs) for speech enhancement. While these networks can produce intelligible speech even in conditions of very low signal-to-noise ratio (SNR), they may also severely alter distinctive speaker characteristics. To tackle this issue, we propose a novel neural network framework that effectively combines speaker embeddings extracted from both noisy and enhanced speech using a Siamese architecture. This architecture allows us to leverage complementary information from both sources, enhancing the robustness of speaker verification under severe noise conditions. Our framework is lightweight and agnostic to specific speaker verification and speech enhancement techniques, enabling the use of a wide range of state-of-the-art solutions without modification. Experimental results demonstrate the superior performance of our proposed framework.
Domain Adaptation for DoA Estimation in Multipath Channels with Interferences
Sep 12, 2024We consider the problem of estimating the direction-of-arrival (DoA) of a desired source located in a known region of interest in the presence of interfering sources and multipath. We propose an approach that precedes the DoA estimation and relies on generating a set of reference steering vectors. The steering vectors' generative model is a free space model, which is beneficial for many DoA estimation algorithms. The set of reference steering vectors is then used to compute a function that maps the received signals from the adverse environment to a reference domain free from interfering sources and multipath. We show theoretically and empirically that the proposed map, which is analogous to domain adaption, improves DoA estimation by mitigating interference and multipath effects. Specifically, we demonstrate a substantial improvement in accuracy when the proposed approach is applied before three commonly used beamformers: the delay-and-sum (DS), the minimum variance distortionless response (MVDR), and the Multiple Signal Classification (MUSIC).
MBSS-T1: Model-Based Self-Supervised Motion Correction for Robust Cardiac T1 Mapping
Aug 21, 2024T1 mapping is a valuable quantitative MRI technique for diagnosing diffuse myocardial diseases. Traditional methods, relying on breath-hold sequences and echo triggering, face challenges with patient compliance and arrhythmias, limiting their effectiveness. Image registration can enable motion-robust T1 mapping, but inherent intensity differences between time points pose a challenge. We introduce MBSS-T1, a self-supervised model for motion correction in cardiac T1 mapping, constrained by physical and anatomical principles. The physical constraints ensure expected signal decay behavior, while the anatomical constraints maintain realistic deformations. The unique combination of these constraints ensures accurate T1 mapping along the longitudinal relaxation axis. MBSS-T1 outperformed baseline deep-learning-based image registration approaches in a 5-fold experiment on a public dataset of 210 patients (STONE sequence) and an internal dataset of 19 patients (MOLLI sequence). MBSS-T1 excelled in model fitting quality (R2: 0.974 vs. 0.941, 0.946), anatomical alignment (Dice score: 0.921 vs. 0.984, 0.988), and expert visual quality assessment for the presence of visible motion artifacts (4.33 vs. 3.34, 3.62). MBSS-T1 has the potential to enable motion-robust T1 mapping for a broader range of patients, overcoming challenges such as arrhythmias, and suboptimal compliance, and allowing for free-breathing T1 mapping without requiring large training datasets.
ViTime: A Visual Intelligence-Based Foundation Model for Time Series Forecasting
Jul 10, 2024



The success of large pretrained models in natural language processing (NLP) and computer vision (CV) has opened new avenues for constructing foundation models for time series forecasting (TSF). Traditional TSF foundation models rely heavily on numerical data fitting. In contrast, the human brain is inherently skilled at processing visual information, prefer predicting future trends by observing visualized sequences. From a biomimetic perspective, utilizing models to directly process numerical sequences might not be the most effective route to achieving Artificial General Intelligence (AGI). This paper proposes ViTime, a novel Visual Intelligence-based foundation model for TSF. ViTime overcomes the limitations of numerical time series data fitting by utilizing visual data processing paradigms and employs a innovative data synthesis method during training, called Real Time Series (RealTS). Experiments on a diverse set of previously unseen forecasting datasets demonstrate that ViTime achieves state-of-the-art zero-shot performance, even surpassing the best individually trained supervised models in some situations. These findings suggest that visual intelligence can significantly enhance time series analysis and forecasting, paving the way for more advanced and versatile models in the field. The code for our framework is accessible at https://github.com/IkeYang/ViTime.
Enhanced ASR Robustness to Packet Loss with a Front-End Adaptation Network
Jun 27, 2024



In the realm of automatic speech recognition (ASR), robustness in noisy environments remains a significant challenge. Recent ASR models, such as Whisper, have shown promise, but their efficacy in noisy conditions can be further enhanced. This study is focused on recovering from packet loss to improve the word error rate (WER) of ASR models. We propose using a front-end adaptation network connected to a frozen ASR model. The adaptation network is trained to modify the corrupted input spectrum by minimizing the criteria of the ASR model in addition to an enhancement loss function. Our experiments demonstrate that the adaptation network, trained on Whisper's criteria, notably reduces word error rates across domains and languages in packet-loss scenarios. This improvement is achieved with minimal affect to Whisper model's foundational performance, underscoring our method's practicality and potential in enhancing ASR models in challenging acoustic environments.
PCMC-T1: Free-breathing myocardial T1 mapping with Physically-Constrained Motion Correction
Aug 22, 2023T1 mapping is a quantitative magnetic resonance imaging (qMRI) technique that has emerged as a valuable tool in the diagnosis of diffuse myocardial diseases. However, prevailing approaches have relied heavily on breath-hold sequences to eliminate respiratory motion artifacts. This limitation hinders accessibility and effectiveness for patients who cannot tolerate breath-holding. Image registration can be used to enable free-breathing T1 mapping. Yet, inherent intensity differences between the different time points make the registration task challenging. We introduce PCMC-T1, a physically-constrained deep-learning model for motion correction in free-breathing T1 mapping. We incorporate the signal decay model into the network architecture to encourage physically-plausible deformations along the longitudinal relaxation axis. We compared PCMC-T1 to baseline deep-learning-based image registration approaches using a 5-fold experimental setup on a publicly available dataset of 210 patients. PCMC-T1 demonstrated superior model fitting quality (R2: 0.955) and achieved the highest clinical impact (clinical score: 3.93) compared to baseline methods (0.941, 0.946 and 3.34, 3.62 respectively). Anatomical alignment results were comparable (Dice score: 0.9835 vs. 0.984, 0.988). Our code and trained models are available at https://github.com/eyalhana/PCMC-T1.
Challenges and Opportunities in Multi-device Speech Processing
Jun 27, 2022
We review current solutions and technical challenges for automatic speech recognition, keyword spotting, device arbitration, speech enhancement, and source localization in multidevice home environments to provide context for the INTERSPEECH 2022 special session, "Challenges and opportunities for signal processing and machine learning for multiple smart devices". We also identify the datasets needed to support these research areas. Based on the review and our research experience in the multi-device domain, we conclude with an outlook on the future evolution
Objective Metrics to Evaluate Residual-Echo Suppression During Double-Talk
Jul 15, 2021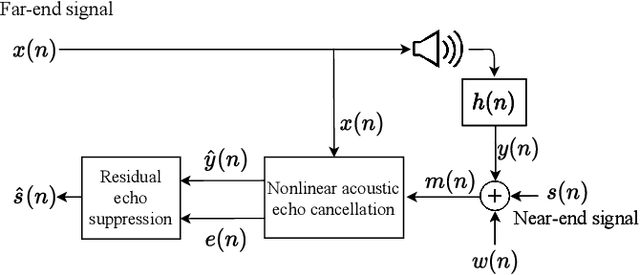
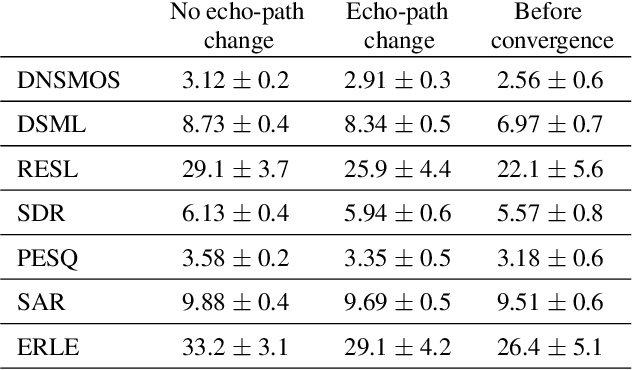
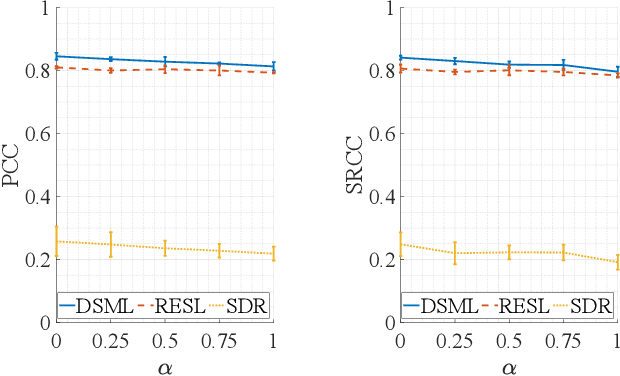
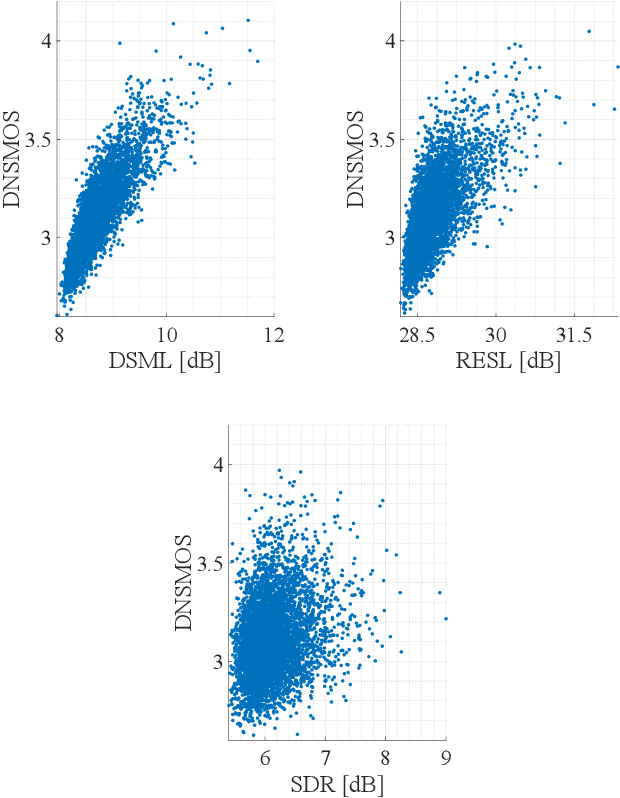
Human subjective evaluation is optimal to assess speech quality for human perception. The recently introduced deep noise suppression mean opinion score (DNSMOS) metric was shown to estimate human ratings with great accuracy. The signal-to-distortion ratio (SDR) metric is widely used to evaluate residual-echo suppression (RES) systems by estimating speech quality during double-talk. However, since the SDR is affected by both speech distortion and residual-echo presence, it does not correlate well with human ratings according to the DNSMOS. To address that, we introduce two objective metrics to separately quantify the desired-speech maintained level (DSML) and residual-echo suppression level (RESL) during double-talk. These metrics are evaluated using a deep learning-based RES-system with a tunable design parameter. Using 280 hours of real and simulated recordings, we show that the DSML and RESL correlate well with the DNSMOS with high generalization to various setups. Also, we empirically investigate the relation between tuning the RES-system design parameter and the DSML-RESL tradeoff it creates and offer a practical design scheme for dynamic system requirements.
Convolutional Sparse Coding Fast Approximation with Application to Seismic Reflectivity Estimation
Jun 29, 2021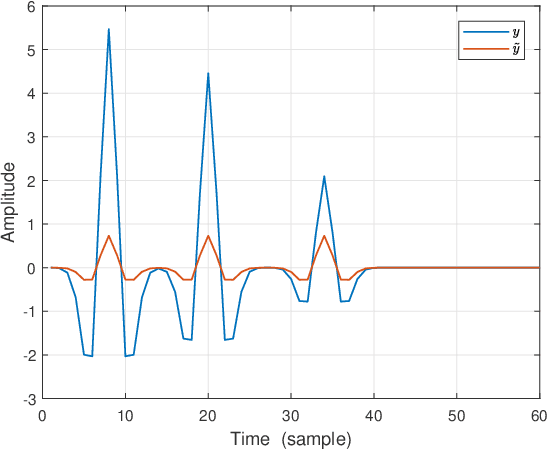
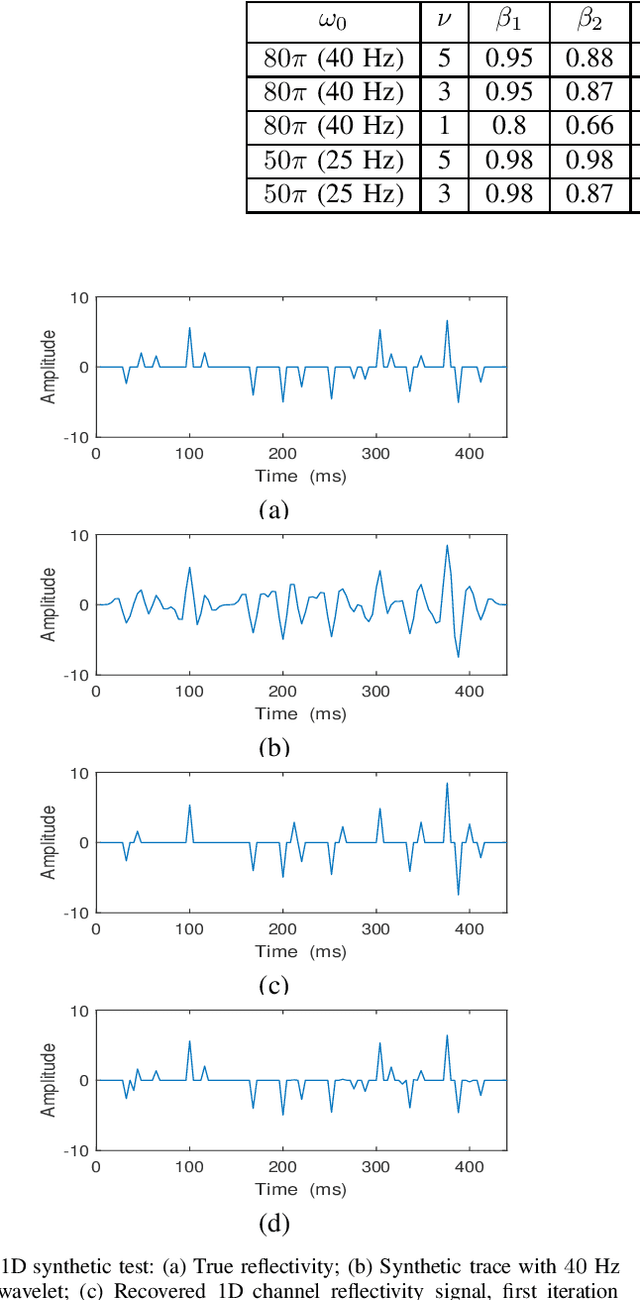
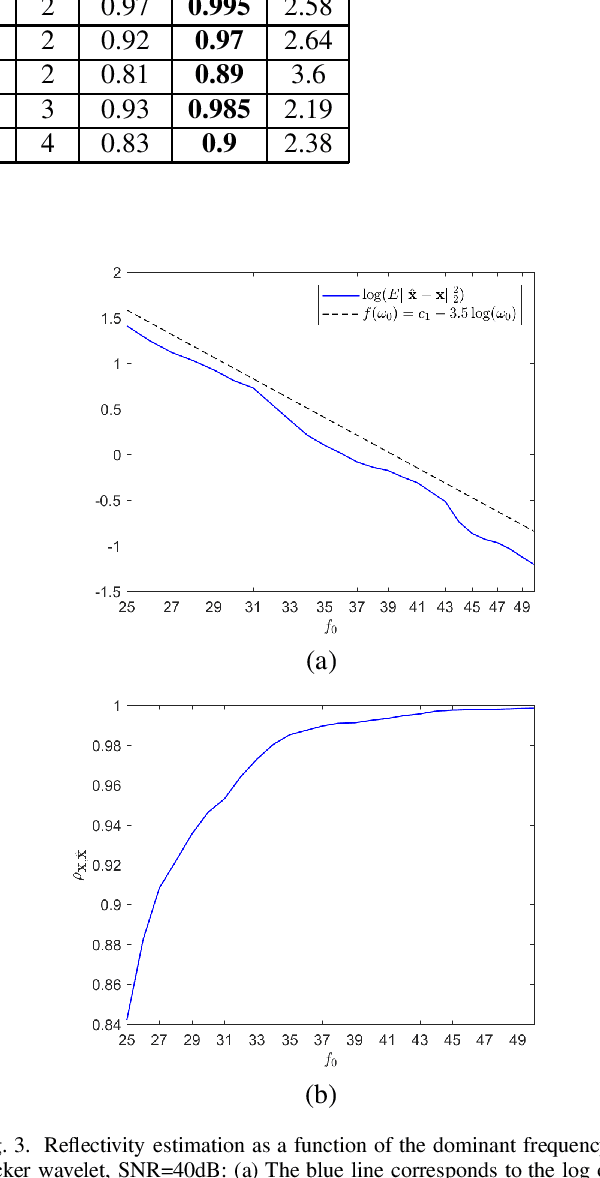
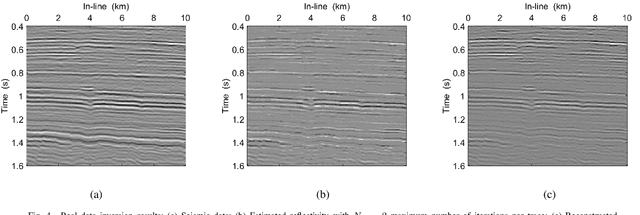
In sparse coding, we attempt to extract features of input vectors, assuming that the data is inherently structured as a sparse superposition of basic building blocks. Similarly, neural networks perform a given task by learning features of the training data set. Recently both data-driven and model-driven feature extracting methods have become extremely popular and have achieved remarkable results. Nevertheless, practical implementations are often too slow to be employed in real-life scenarios, especially for real-time applications. We propose a speed-up upgraded version of the classic iterative thresholding algorithm, that produces a good approximation of the convolutional sparse code within 2-5 iterations. The speed advantage is gained mostly from the observation that most solvers are slowed down by inefficient global thresholding. The main idea is to normalize each data point by the local receptive field energy, before applying a threshold. This way, the natural inclination towards strong feature expressions is suppressed, so that one can rely on a global threshold that can be easily approximated, or learned during training. The proposed algorithm can be employed with a known predetermined dictionary, or with a trained dictionary. The trained version is implemented as a neural net designed as the unfolding of the proposed solver. The performance of the proposed solution is demonstrated via the seismic inversion problem in both synthetic and real data scenarios. We also provide theoretical guarantees for a stable support recovery. Namely, we prove that under certain conditions the true support is perfectly recovered within the first iteration.