 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Activity Detection for Transient Noisy Environment Based on Diffusion Nets
Paper and Code
Jun 25, 2021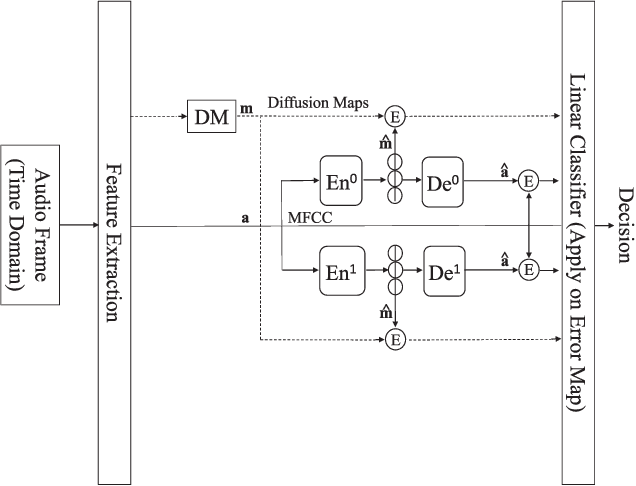
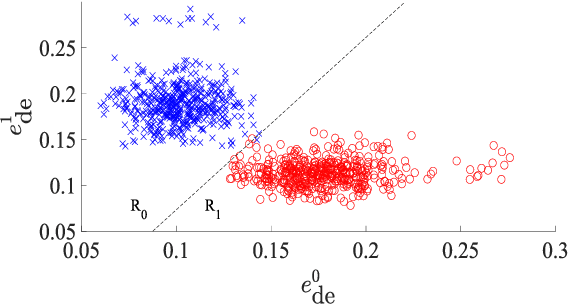
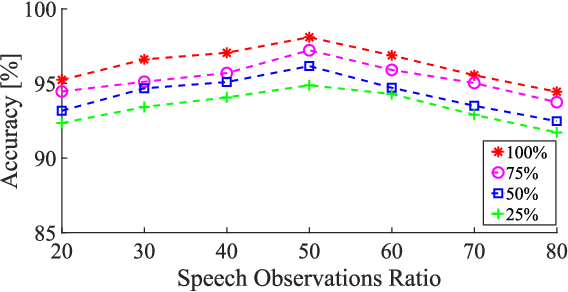
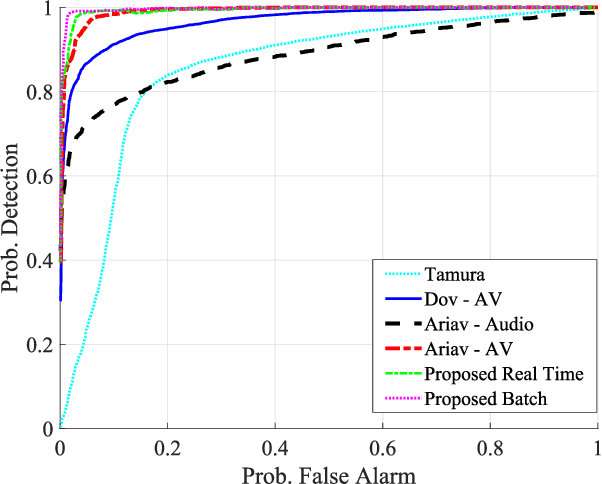
We address voice activity detection in acoustic environments of transients and stationary noises, which often occur in real life scenarios. We exploit unique spatial patterns of speech and non-speech audio frames by independently learning their underlying geometric structure. This process is done through a deep encoder-decoder based neural network architecture. This structure involves an encoder that maps spectral features with temporal information to their low-dimensional representations, which are generated by applying the diffusion maps method. The encoder feeds a decoder that maps the embedded data back into the high-dimensional space. A deep neural network, which is trained to separate speech from non-speech frames, is obtained by concatenating the decoder to the encoder, resembling the known Diffusion nets architecture. Experimental results show enhanced performance compared to competing voice activity detection methods. The improvement is achieved in both accuracy, robustness and generalization ability. Our model performs in a real-time manner and can be integrated into audio-based communication systems. We also present a batch algorithm which obtains an even higher accuracy for off-line applications.