 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Power Estimation via Riemannian Covariance Matching
May 12, 2026We propose a new method for spatial power spectrum estimation in array processing that leverages the Riemannian geometry of Hermitian positive definite (HPD) matrices. We show that conventional approaches minimize variants of the Euclidean distance between the sample covariance matrix and a model covariance matrix, without considering the fact that covariance matrices lie on the Riemannian manifold of HPD matrices. By exploiting this manifold, we present a Riemannian-aware covariance matching algorithm, termed SERCOM, using the Jensen-Bregman LogDet (JBLD) divergence, which, unlike other Riemannian distances, can be evaluated efficiently without eigen-decomposition. We theoretically compare the JBLD divergence to other Euclidean- and Riemannian-based distances, demonstrating robustness to spectral distortions. Experimental results demonstrate that SERCOM consistently outperforms existing methods in direction-of-arrival (DOA) and power estimation, particularly in challenging scenarios with low SNR, limited number of snapshots, and correlated sources.
Complex Interpolation of Matrices with an application to Multi-Manifold Learning
Apr 15, 2026Given two symmetric positive-definite matrices $A, B \in \mathbb{R}^{n \times n}$, we study the spectral properties of the interpolation $A^{1-x} B^x$ for $0 \leq x \leq 1$. The presence of `common structures' in $A$ and $B$, eigenvectors pointing in a similar direction, can be investigated using this interpolation perspective. Generically, exact log-linearity of the operator norm $\|A^{1-x} B^x\|$ is equivalent to the existence of a shared eigenvector in the original matrices; stability bounds show that approximate log-linearity forces principal singular vectors to align with leading eigenvectors of both matrices. These results give rise to and provide theoretical justification for a multi-manifold learning framework that identifies common and distinct latent structures in multiview data.
Geometric Framework for Robust Order Detection in Delay-Coordinates Dynamic Mode Decomposition
Mar 15, 2026Delay-coordinates dynamic mode decomposition (DC-DMD) is widely used to extract coherent spatiotemporal modes from high-dimensional time series. A central challenge is distinguishing dynamically meaningful modes from spurious modes induced by noise and order overestimation. We show that model order detection and mode selection in DC-DMD are fundamentally problems of subspace geometry. Specifically, true modes are characterized by concentration within a low-dimensional signal subspace, whereas spurious modes necessarily retain non-negligible components outside any moderate overestimate of that subspace. This geometric distinction yields a perturbation-robust definition of true and spurious modes and yields fully data-driven selection criteria. This geometric framework leads to two complementary data-driven selection criteria. The first is derived directly from the geometric distinction and uses a data-driven proxy of the signal-subspace to compute a residual score. The second arises from a new operator-theoretic analysis of delay embedding. Using a block-companion formulation, we show that all modes exhibit a Kronecker-Vandermonde (KV) structure induced by the delay-coordinates, and true modes are distinguished by the degree to which they conform to it. Importantly, we also show that this deviation is governed precisely by the geometric residual. In addition, our analysis provides a principled explanation for the empirical behavior of magnitude- and norm-based heuristics, clarifying when and why they fail under delay-coordinates. Extensive numerical experiments confirm the theoretical predictions and demonstrate that the proposed geometric and structure-based methods achieve robust and accurate order detection and mode selection, consistently better than existing baselines across noise levels, spectral separations, damping regimes, and embedding lengths.
It Takes a Graph to Know a Graph: Rewiring for Homophily with a Reference Graph
May 18, 2025Graph Neural Networks (GNNs) excel at analyzing graph-structured data but struggle on heterophilic graphs, where connected nodes often belong to different classes. While this challenge is commonly addressed with specialized GNN architectures, graph rewiring remains an underexplored strategy in this context. We provide theoretical foundations linking edge homophily, GNN embedding smoothness, and node classification performance, motivating the need to enhance homophily. Building on this insight, we introduce a rewiring framework that increases graph homophily using a reference graph, with theoretical guarantees on the homophily of the rewired graph. To broaden applicability, we propose a label-driven diffusion approach for constructing a homophilic reference graph from node features and training labels. Through extensive simulations, we analyze how the homophily of both the original and reference graphs influences the rewired graph homophily and downstream GNN performance. We evaluate our method on 11 real-world heterophilic datasets and show that it outperforms existing rewiring techniques and specialized GNNs for heterophilic graphs, achieving improved node classification accuracy while remaining efficient and scalable to large graphs.
Structure-Aware Matrix Pencil Method
Feb 24, 2025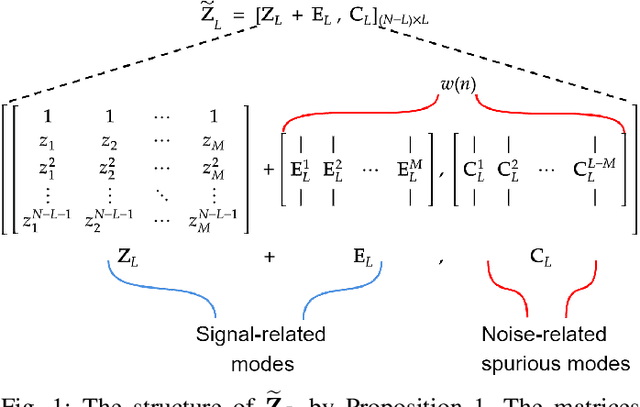
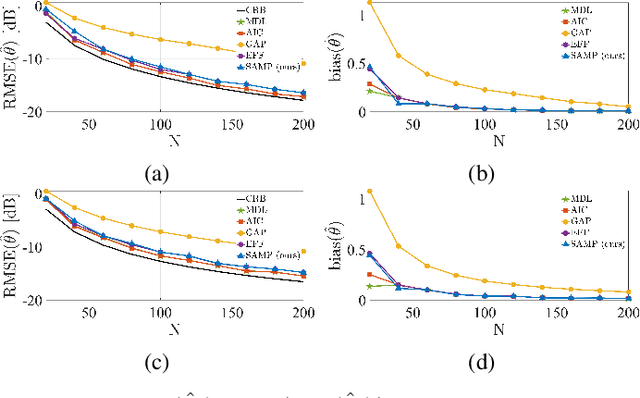
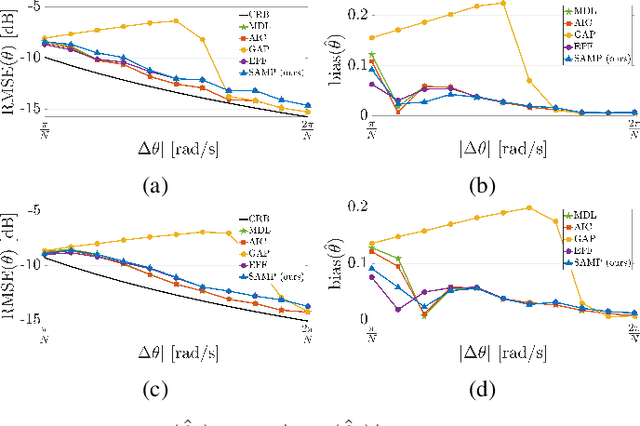
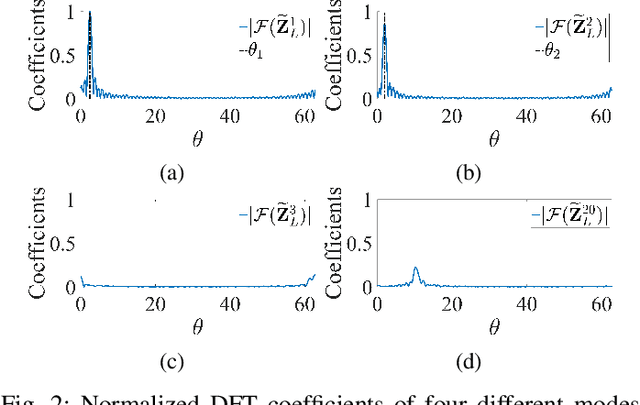
We address the problem of detecting the number of complex exponentials and estimating their parameters from a noisy signal using the Matrix Pencil (MP) method. We introduce the MP modes and present their informative spectral structure. We show theoretically that these modes can be divided into signal and noise modes, where the signal modes exhibit a perturbed Vandermonde structure. Leveraging this structure, we proposed a new MP algorithm, termed the SAMP algorithm, which has two novel components. First, we present a new and robust model order detection with theoretical guarantees. Second, we present an efficient estimation of signal amplitudes. We show empirically that the SAMP algorithm significantly outperforms the standard MP method, particularly in challenging conditions with closely-spaced frequencies and low Signal-to-Noise Ratio (SNR) values, approaching the Cramer-Rao lower bound (CRB) for a broad SNR range. Additionally, compared with prevalent information-based criteria, we show that SAMP is more computationally efficient and insensitive to noise distribution.
Coupled Hierarchical Structure Learning using Tree-Wasserstein Distance
Jan 07, 2025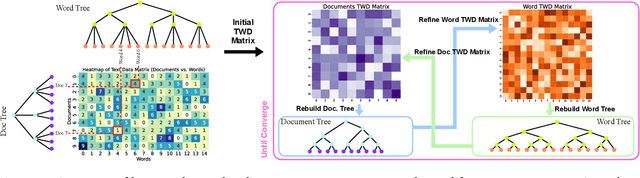
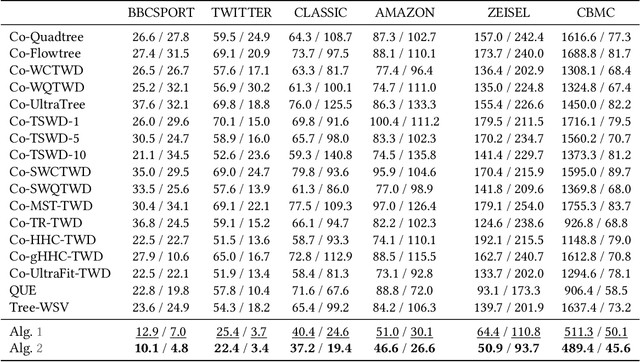
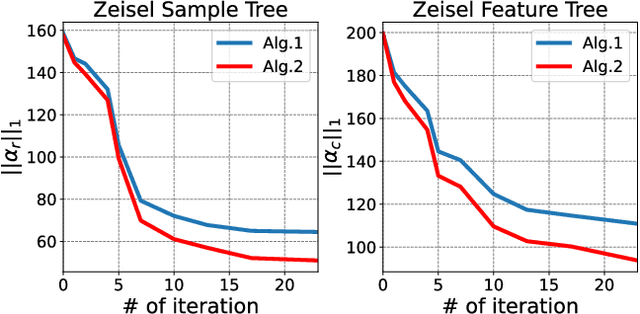
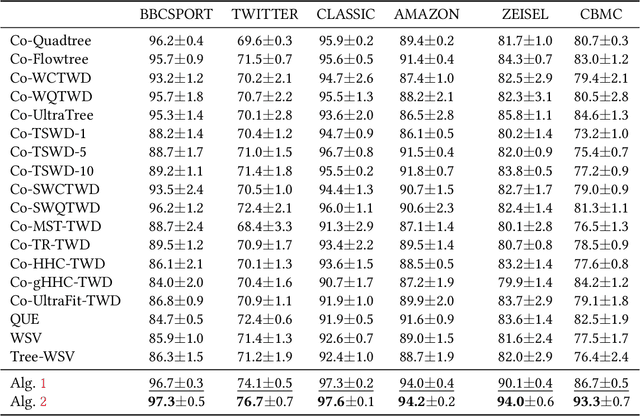
In many applications, both data samples and features have underlying hierarchical structures. However, existing methods for learning these latent structures typically focus on either samples or features, ignoring possible coupling between them. In this paper, we introduce a coupled hierarchical structure learning method using tree-Wasserstein distance (TWD). Our method jointly computes TWDs for samples and features, representing their latent hierarchies as trees. We propose an iterative, unsupervised procedure to build these sample and feature trees based on diffusion geometry, hyperbolic geometry, and wavelet filters. We show that this iterative procedure converges and empirically improves the quality of the constructed trees. The method is also computationally efficient and scales well in high-dimensional settings. Our method can be seamlessly integrated with hyperbolic graph convolutional networks (HGCN). We demonstrate that our method outperforms competing approaches in sparse approximation and unsupervised Wasserstein distance learning on several word-document and single-cell RNA-sequencing datasets. In addition, integrating our method into HGCN enhances performance in link prediction and node classification tasks.
Tree-Wasserstein Distance for High Dimensional Data with a Latent Feature Hierarchy
Oct 28, 2024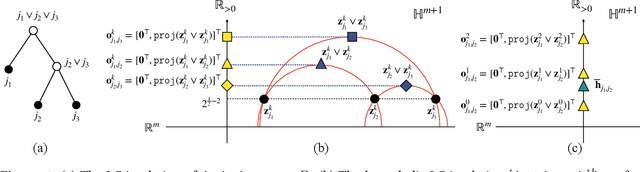
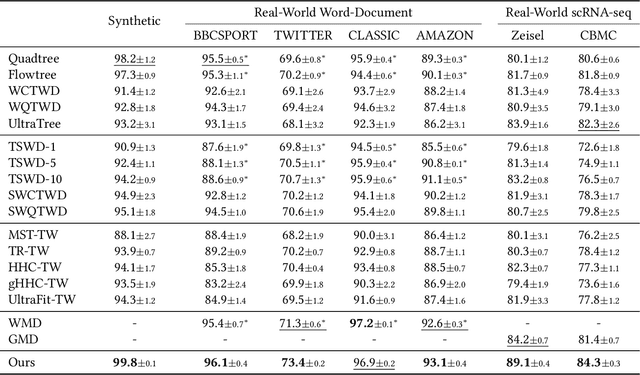
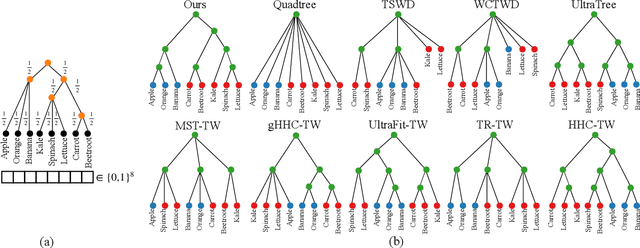
Finding meaningful distances between high-dimensional data samples is an important scientific task. To this end, we propose a new tree-Wasserstein distance (TWD) for high-dimensional data with two key aspects. First, our TWD is specifically designed for data with a latent feature hierarchy, i.e., the features lie in a hierarchical space, in contrast to the usual focus on embedding samples in hyperbolic space. Second, while the conventional use of TWD is to speed up the computation of the Wasserstein distance, we use its inherent tree as a means to learn the latent feature hierarchy. The key idea of our method is to embed the features into a multi-scale hyperbolic space using diffusion geometry and then present a new tree decoding method by establishing analogies between the hyperbolic embedding and trees. We show that our TWD computed based on data observations provably recovers the TWD defined with the latent feature hierarchy and that its computation is efficient and scalable. We showcase the usefulness of the proposed TWD in applications to word-document and single-cell RNA-sequencing datasets, demonstrating its advantages over existing TWDs and methods based on pre-trained models.
Domain Adaptation for DoA Estimation in Multipath Channels with Interferences
Sep 12, 2024We consider the problem of estimating the direction-of-arrival (DoA) of a desired source located in a known region of interest in the presence of interfering sources and multipath. We propose an approach that precedes the DoA estimation and relies on generating a set of reference steering vectors. The steering vectors' generative model is a free space model, which is beneficial for many DoA estimation algorithms. The set of reference steering vectors is then used to compute a function that maps the received signals from the adverse environment to a reference domain free from interfering sources and multipath. We show theoretically and empirically that the proposed map, which is analogous to domain adaption, improves DoA estimation by mitigating interference and multipath effects. Specifically, we demonstrate a substantial improvement in accuracy when the proposed approach is applied before three commonly used beamformers: the delay-and-sum (DS), the minimum variance distortionless response (MVDR), and the Multiple Signal Classification (MUSIC).
On Learning what to Learn: heterogeneous observations of dynamics and establishing (possibly causal) relations among them
Jun 10, 2024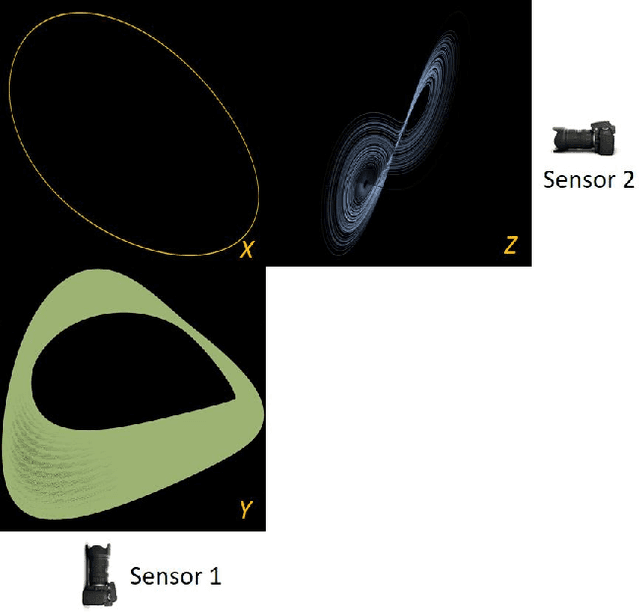
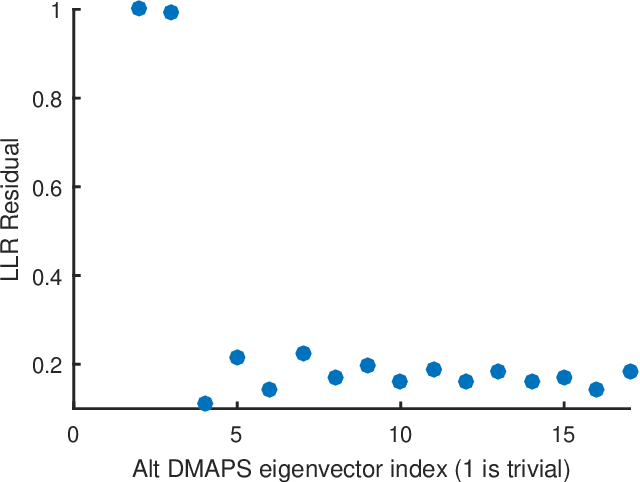
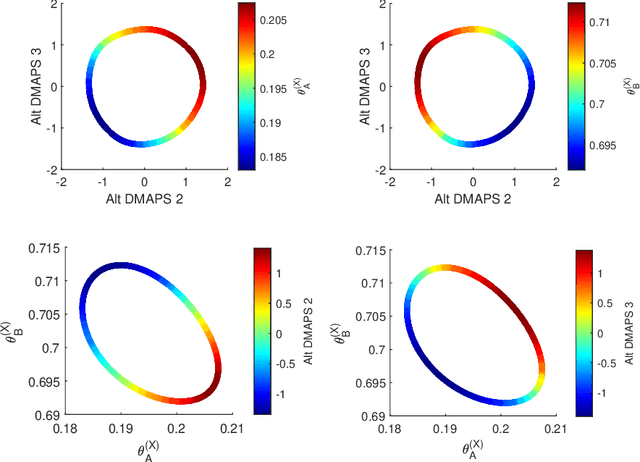
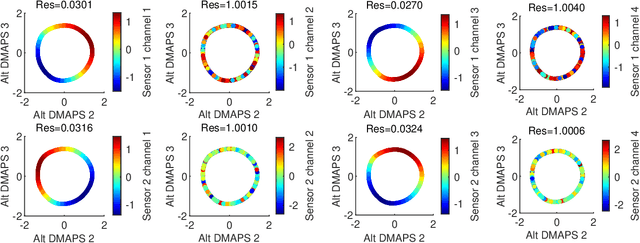
Before we attempt to learn a function between two (sets of) observables of a physical process, we must first decide what the inputs and what the outputs of the desired function are going to be. Here we demonstrate two distinct, data-driven ways of initially deciding ``the right quantities'' to relate through such a function, and then proceed to learn it. This is accomplished by processing multiple simultaneous heterogeneous data streams (ensembles of time series) from observations of a physical system: multiple observation processes of the system. We thus determine (a) what subsets of observables are common between the observation processes (and therefore observable from each other, relatable through a function); and (b) what information is unrelated to these common observables, and therefore particular to each observation process, and not contributing to the desired function. Any data-driven function approximation technique can subsequently be used to learn the input-output relation, from k-nearest neighbors and Geometric Harmonics to Gaussian Processes and Neural Networks. Two particular ``twists'' of the approach are discussed. The first has to do with the identifiability of particular quantities of interest from the measurements. We now construct mappings from a single set of observations of one process to entire level sets of measurements of the process, consistent with this single set. The second attempts to relate our framework to a form of causality: if one of the observation processes measures ``now'', while the second observation process measures ``in the future'', the function to be learned among what is common across observation processes constitutes a dynamical model for the system evolution.
Equivariant Machine Learning on Graphs with Nonlinear Spectral Filters
Jun 03, 2024



Equivariant machine learning is an approach for designing deep learning models that respect the symmetries of the problem, with the aim of reducing model complexity and improving generalization. In this paper, we focus on an extension of shift equivariance, which is the basis of convolution networks on images, to general graphs. Unlike images, graphs do not have a natural notion of domain translation. Therefore, we consider the graph functional shifts as the symmetry group: the unitary operators that commute with the graph shift operator. Notably, such symmetries operate in the signal space rather than directly in the spatial space. We remark that each linear filter layer of a standard spectral graph neural network (GNN) commutes with graph functional shifts, but the activation function breaks this symmetry. Instead, we propose nonlinear spectral filters (NLSFs) that are fully equivariant to graph functional shifts and show that they have universal approximation properties. The proposed NLSFs are based on a new form of spectral domain that is transferable between graphs. We demonstrate the superior performance of NLSFs over existing spectral GNNs in node and graph classification benchmarks.