 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning what to Learn: heterogeneous observations of dynamics and establishing (possibly causal) relations among them
Paper and Code
Jun 10, 2024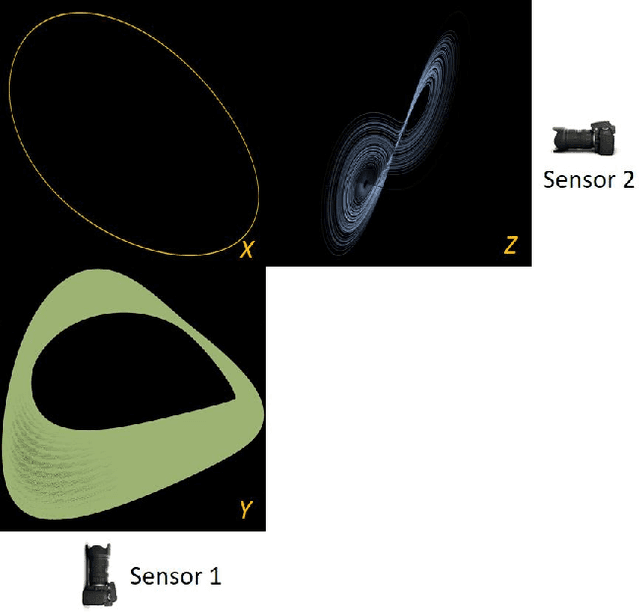
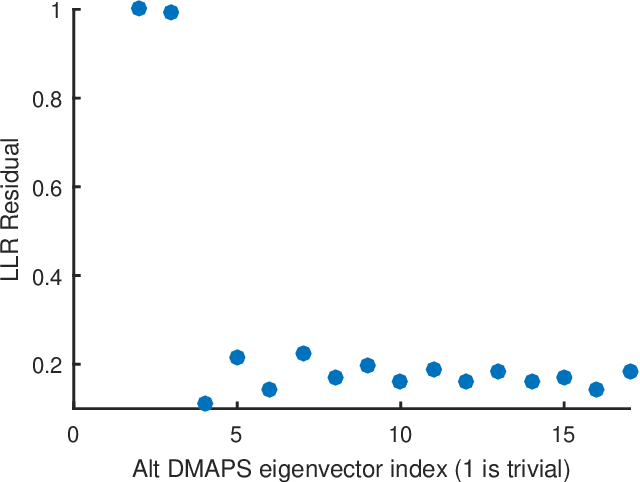
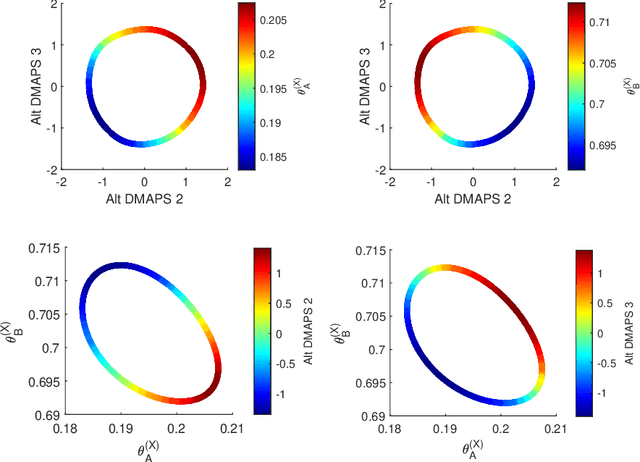
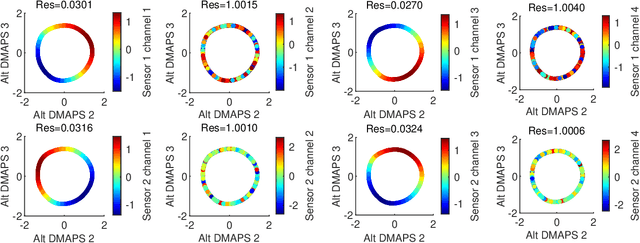
Before we attempt to learn a function between two (sets of) observables of a physical process, we must first decide what the inputs and what the outputs of the desired function are going to be. Here we demonstrate two distinct, data-driven ways of initially deciding ``the right quantities'' to relate through such a function, and then proceed to learn it. This is accomplished by processing multiple simultaneous heterogeneous data streams (ensembles of time series) from observations of a physical system: multiple observation processes of the system. We thus determine (a) what subsets of observables are common between the observation processes (and therefore observable from each other, relatable through a function); and (b) what information is unrelated to these common observables, and therefore particular to each observation process, and not contributing to the desired function. Any data-driven function approximation technique can subsequently be used to learn the input-output relation, from k-nearest neighbors and Geometric Harmonics to Gaussian Processes and Neural Networks. Two particular ``twists'' of the approach are discussed. The first has to do with the identifiability of particular quantities of interest from the measurements. We now construct mappings from a single set of observations of one process to entire level sets of measurements of the process, consistent with this single set. The second attempts to relate our framework to a form of causality: if one of the observation processes measures ``now'', while the second observation process measures ``in the future'', the function to be learned among what is common across observation processes constitutes a dynamical model for the system evolution.