 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDictionary learning for Kernel EDMD
Apr 28, 2026Studying nonlinear dynamical systems through their state space behavior can be challenging, and one possible alternative is to analyze them via their associated Koopman operator. This turns the nonlinear problem into a linear, infinite-dimensional one. To approximate the operator in finite dimensions, extended dynamic mode decomposition (EDMD) is a commonly used algorithm. It requires a finite list of functionals and a set of snapshots from the system to compute an approximation of the operator and its corresponding spectrum. Instead of choosing the list of functionals directly, it can be implicitly defined via kernels, a method known as kernel extended dynamic mode decomposition (kEDMD). However, one still needs to define the kernel and choose its parameter values. In this paper, we aim to streamline this process by extending dictionary learning for EDMD to kernel learning in kEDMD. By simplifying kEDMD we show how to perform gradient-based optimization over the learnable kernel parameters, and demonstrate that this method leads to useful kernels for the original kEDMD. The focus of our work is a method that takes a weighted list of kernels with randomly initialized values as input and outputs a list of kernels and parameter values suitable for approximating the Koopman operator of the underlying system. We demonstrate that unimportant kernels can be removed from the list by analyzing the weights in the weighted sum. We evaluate the method across several experiments, including the Duffing oscillator and the Kuramoto-Sivashinsky PDE, showcasing the method's different strengths.
Stability and Bifurcation Analysis of Nonlinear PDEs via Random Projection-based PINNs: A Krylov-Arnoldi Approach
Mar 23, 2026We address a numerical framework for the stability and bifurcation analysis of nonlinear partial differential equations (PDEs) in which the solution is sought in the function space spanned by physics-informed random projection neural networks (PI-RPNNs), and discretized via a collocation approach. These are single-hidden-layer networks with randomly sampled and fixed a priori hidden-layer weights; only the linear output layer weights are optimized, reducing training to a single least-squares solve. This linear output structure enables the direct and explicit formulation of the eigenvalue problem governing the linear stability of stationary solutions. This takes a generalized eigenvalue form, which naturally separates the physical domain interior dynamics from the algebraic constraints imposed by boundary conditions, at no additional training cost and without requiring additional PDE solves. However, the random projection collocation matrix is inherently numerically rank-deficient, rendering naive eigenvalue computation unreliable and contaminating the true eigenvalue spectrum with spurious near-zero modes. To overcome this limitation, we introduce a matrix-free shift-invert Krylov-Arnoldi method that operates directly in weight space, avoiding explicit inversion of the numerically rank-deficient collocation matrix and enabling the reliable computation of several leading eigenpairs of the physical Jacobian - the discretized Frechet derivative of the PDE operator with respect to the solution field, whose eigenvalue spectrum determines linear stability. We further prove that the PI-RPNN-based generalized eigenvalue problem is almost surely regular, guaranteeing solvability with standard eigensolvers, and that the singular values of the random projection collocation matrix decay exponentially for analytic activation functions.
A Mechanistic Analysis of Transformers for Dynamical Systems
Dec 24, 2025Transformers are increasingly adopted for modeling and forecasting time-series, yet their internal mechanisms remain poorly understood from a dynamical systems perspective. In contrast to classical autoregressive and state-space models, which benefit from well-established theoretical foundations, Transformer architectures are typically treated as black boxes. This gap becomes particularly relevant as attention-based models are considered for general-purpose or zero-shot forecasting across diverse dynamical regimes. In this work, we do not propose a new forecasting model, but instead investigate the representational capabilities and limitations of single-layer Transformers when applied to dynamical data. Building on a dynamical systems perspective we interpret causal self-attention as a linear, history-dependent recurrence and analyze how it processes temporal information. Through a series of linear and nonlinear case studies, we identify distinct operational regimes. For linear systems, we show that the convexity constraint imposed by softmax attention fundamentally restricts the class of dynamics that can be represented, leading to oversmoothing in oscillatory settings. For nonlinear systems under partial observability, attention instead acts as an adaptive delay-embedding mechanism, enabling effective state reconstruction when sufficient temporal context and latent dimensionality are available. These results help bridge empirical observations with classical dynamical systems theory, providing insight into when and why Transformers succeed or fail as models of dynamical systems.
BumpNet: A Sparse Neural Network Framework for Learning PDE Solutions
Dec 19, 2025We introduce BumpNet, a sparse neural network framework for PDE numerical solution and operator learning. BumpNet is based on meshless basis function expansion, in a similar fashion to radial-basis function (RBF) networks. Unlike RBF networks, the basis functions in BumpNet are constructed from ordinary sigmoid activation functions. This enables the efficient use of modern training techniques optimized for such networks. All parameters of the basis functions, including shape, location, and amplitude, are fully trainable. Model parsimony and h-adaptivity are effectively achieved through dynamically pruning basis functions during training. BumpNet is a general framework that can be combined with existing neural architectures for learning PDE solutions: here, we propose Bump-PINNs (BumpNet with physics-informed neural networks) for solving general PDEs; Bump-EDNN (BumpNet with evolutionary deep neural networks) to solve time-evolution PDEs; and Bump-DeepONet (BumpNet with deep operator networks) for PDE operator learning. Bump-PINNs are trained using the same collocation-based approach used by PINNs, Bump-EDNN uses a BumpNet only in the spatial domain and uses EDNNs to advance the solution in time, while Bump-DeepONets employ a BumpNet regression network as the trunk network of a DeepONet. Extensive numerical experiments demonstrate the efficiency and accuracy of the proposed architecture.
Enabling Local Neural Operators to perform Equation-Free System-Level Analysis
May 05, 2025Neural Operators (NOs) provide a powerful framework for computations involving physical laws that can be modelled by (integro-) partial differential equations (PDEs), directly learning maps between infinite-dimensional function spaces that bypass both the explicit equation identification and their subsequent numerical solving. Still, NOs have so far primarily been employed to explore the dynamical behavior as surrogates of brute-force temporal simulations/predictions. Their potential for systematic rigorous numerical system-level tasks, such as fixed-point, stability, and bifurcation analysis - crucial for predicting irreversible transitions in real-world phenomena - remains largely unexplored. Toward this aim, inspired by the Equation-Free multiscale framework, we propose and implement a framework that integrates (local) NOs with advanced iterative numerical methods in the Krylov subspace, so as to perform efficient system-level stability and bifurcation analysis of large-scale dynamical systems. Beyond fixed point, stability, and bifurcation analysis enabled by local in time NOs, we also demonstrate the usefulness of local in space as well as in space-time ("patch") NOs in accelerating the computer-aided analysis of spatiotemporal dynamics. We illustrate our framework via three nonlinear PDE benchmarks: the 1D Allen-Cahn equation, which undergoes multiple concatenated pitchfork bifurcations; the Liouville-Bratu-Gelfand PDE, which features a saddle-node tipping point; and the FitzHugh-Nagumo (FHN) model, consisting of two coupled PDEs that exhibit both Hopf and saddle-node bifurcations.
Generative Learning for Slow Manifolds and Bifurcation Diagrams
Apr 29, 2025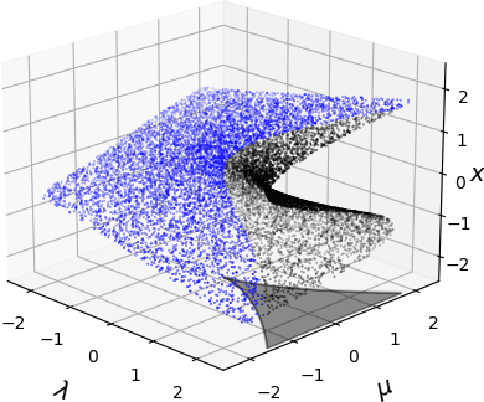

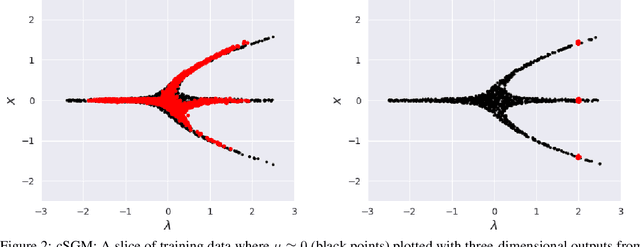
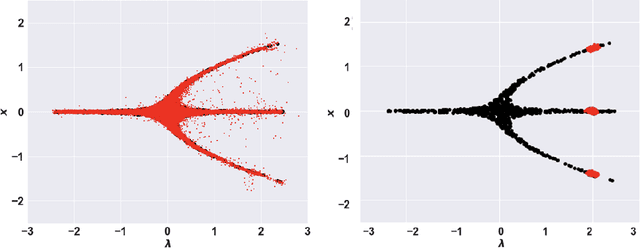
In dynamical systems characterized by separation of time scales, the approximation of so called ``slow manifolds'', on which the long term dynamics lie, is a useful step for model reduction. Initializing on such slow manifolds is a useful step in modeling, since it circumvents fast transients, and is crucial in multiscale algorithms alternating between fine scale (fast) and coarser scale (slow) simulations. In a similar spirit, when one studies the infinite time dynamics of systems depending on parameters, the system attractors (e.g., its steady states) lie on bifurcation diagrams. Sampling these manifolds gives us representative attractors (here, steady states of ODEs or PDEs) at different parameter values. Algorithms for the systematic construction of these manifolds are required parts of the ``traditional'' numerical nonlinear dynamics toolkit. In more recent years, as the field of Machine Learning develops, conditional score-based generative models (cSGMs) have demonstrated capabilities in generating plausible data from target distributions that are conditioned on some given label. It is tempting to exploit such generative models to produce samples of data distributions conditioned on some quantity of interest (QoI). In this work, we present a framework for using cSGMs to quickly (a) initialize on a low-dimensional (reduced-order) slow manifold of a multi-time-scale system consistent with desired value(s) of a QoI (a ``label'') on the manifold, and (b) approximate steady states in a bifurcation diagram consistent with a (new, out-of-sample) parameter value. This conditional sampling can help uncover the geometry of the reduced slow-manifold and/or approximately ``fill in'' missing segments of steady states in a bifurcation diagram.
Neural Chaos: A Spectral Stochastic Neural Operator
Feb 17, 2025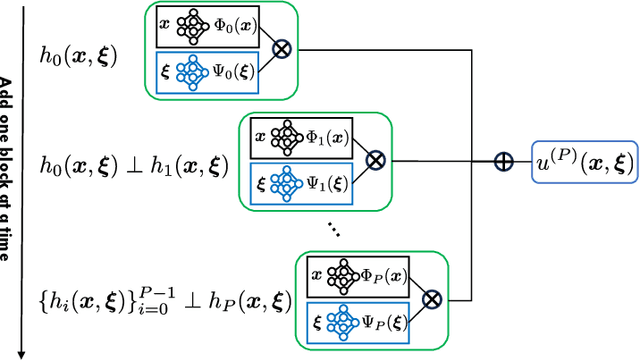
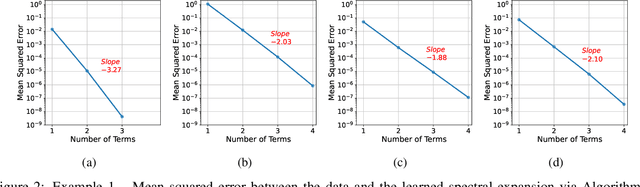
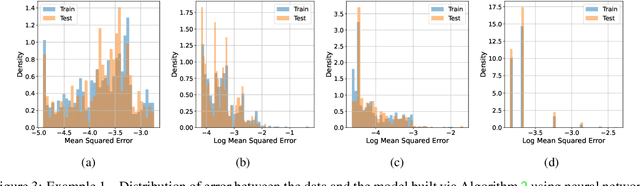
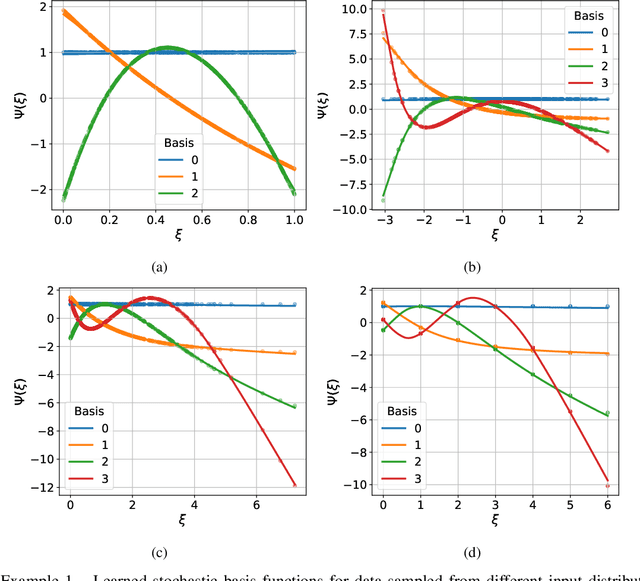
Building surrogate models with uncertainty quantification capabilities is essential for many engineering applications where randomness, such as variability in material properties, is unavoidable. Polynomial Chaos Expansion (PCE) is widely recognized as a to-go method for constructing stochastic solutions in both intrusive and non-intrusive ways. Its application becomes challenging, however, with complex or high-dimensional processes, as achieving accuracy requires higher-order polynomials, which can increase computational demands and or the risk of overfitting. Furthermore, PCE requires specialized treatments to manage random variables that are not independent, and these treatments may be problem-dependent or may fail with increasing complexity. In this work, we adopt the spectral expansion formalism used in PCE; however, we replace the classical polynomial basis functions with neural network (NN) basis functions to leverage their expressivity. To achieve this, we propose an algorithm that identifies NN-parameterized basis functions in a purely data-driven manner, without any prior assumptions about the joint distribution of the random variables involved, whether independent or dependent. The proposed algorithm identifies each NN-parameterized basis function sequentially, ensuring they are orthogonal with respect to the data distribution. The basis functions are constructed directly on the joint stochastic variables without requiring a tensor product structure. This approach may offer greater flexibility for complex stochastic models, while simplifying implementation compared to the tensor product structures typically used in PCE to handle random vectors. We demonstrate the effectiveness of the proposed scheme through several numerical examples of varying complexity and provide comparisons with classical PCE.
Comparing analytic and data-driven approaches to parameter identifiability: A power systems case study
Dec 24, 2024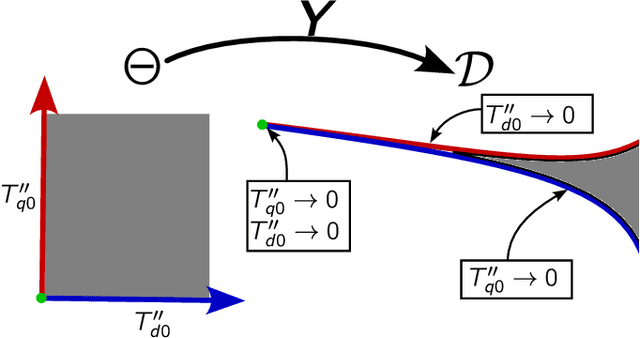
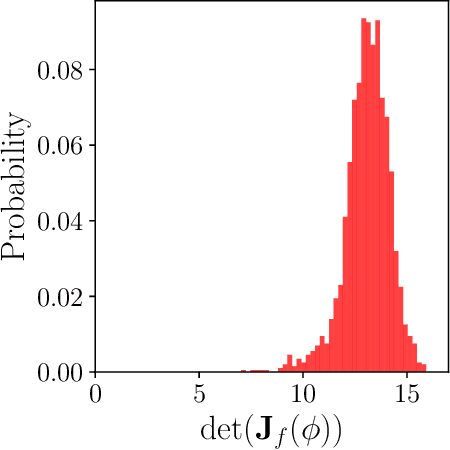
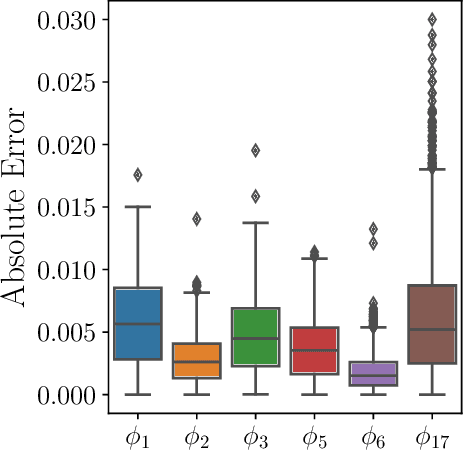
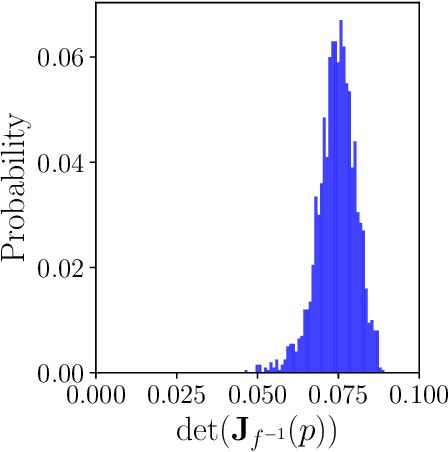
Parameter identifiability refers to the capability of accurately inferring the parameter values of a model from its observations (data). Traditional analysis methods exploit analytical properties of the closed form model, in particular sensitivity analysis, to quantify the response of the model predictions to variations in parameters. Techniques developed to analyze data, specifically manifold learning methods, have the potential to complement, and even extend the scope of the traditional analytical approaches. We report on a study comparing and contrasting analytical and data-driven approaches to quantify parameter identifiability and, importantly, perform parameter reduction tasks. We use the infinite bus synchronous generator model, a well-understood model from the power systems domain, as our benchmark problem. Our traditional analysis methods use the Fisher Information Matrix to quantify parameter identifiability analysis, and the Manifold Boundary Approximation Method to perform parameter reduction. We compare these results to those arrived at through data-driven manifold learning schemes: Output - Diffusion Maps and Geometric Harmonics. For our test case, we find that the two suites of tools (analytical when a model is explicitly available, as well as data-driven when the model is lacking and only measurement data are available) give (correct) comparable results; these results are also in agreement with traditional analysis based on singular perturbation theory. We then discuss the prospects of using data-driven methods for such model analysis.
A Resolution Independent Neural Operator
Jul 17, 2024



The Deep operator network (DeepONet) is a powerful yet simple neural operator architecture that utilizes two deep neural networks to learn mappings between infinite-dimensional function spaces. This architecture is highly flexible, allowing the evaluation of the solution field at any location within the desired domain. However, it imposes a strict constraint on the input space, requiring all input functions to be discretized at the same locations; this limits its practical applications. In this work, we introduce a Resolution Independent Neural Operator (RINO) that provides a framework to make DeepONet resolution-independent, enabling it to handle input functions that are arbitrarily, but sufficiently finely, discretized. To this end, we propose a dictionary learning algorithm to adaptively learn a set of appropriate continuous basis functions, parameterized as implicit neural representations (INRs), from the input data. These basis functions are then used to project arbitrary input function data as a point cloud onto an embedding space (i.e., a vector space of finite dimensions) with dimensionality equal to the dictionary size, which can be directly used by DeepONet without any architectural changes. In particular, we utilize sinusoidal representation networks (SIRENs) as our trainable INR basis functions. We demonstrate the robustness and applicability of RINO in handling arbitrarily (but sufficiently richly) sampled input functions during both training and inference through several numerical examples.
Active search for Bifurcations
Jun 17, 2024Bifurcations mark qualitative changes of long-term behavior in dynamical systems and can often signal sudden ("hard") transitions or catastrophic events (divergences). Accurately locating them is critical not just for deeper understanding of observed dynamic behavior, but also for designing efficient interventions. When the dynamical system at hand is complex, possibly noisy, and expensive to sample, standard (e.g. continuation based) numerical methods may become impractical. We propose an active learning framework, where Bayesian Optimization is leveraged to discover saddle-node or Hopf bifurcations, from a judiciously chosen small number of vector field observations. Such an approach becomes especially attractive in systems whose state x parameter space exploration is resource-limited. It also naturally provides a framework for uncertainty quantification (aleatoric and epistemic), useful in systems with inherent stochasticity.