 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics-Informed Deep Learning for Predicting Extreme Events
Mar 11, 2026Predicting extreme events in high-dimensional chaotic dynamical systems remains a fundamental challenge, as such events are rare, intermittent, and arise from transient dynamical mechanisms that are difficult to infer from limited observations. Accordingly, real-time forecasting calls for precursors that encode the mechanisms driving extremes, rather than relying solely on statistical associations. We propose a fully data-driven framework for long-lead prediction of extreme events that constructs interpretable, mechanism-aware precursors by explicitly tracking transient instabilities preceding event onset. The approach leverages a reduced-order formulation to compute finite-time Lyapunov exponent (FTLE)-like precursors directly from state snapshots, without requiring knowledge of the governing equations. To avoid the prohibitive computational cost of classical FTLE computation, instability growth is evaluated in an adaptively evolving low-dimensional subspace spanned by Optimal Time-Dependent (OTD) modes, enabling efficient identification of transiently amplifying directions. These precursors are then provided as input to a Transformer-based model, enabling forecast of extreme event observables. We demonstrate the framework on Kolmogorov flow, a canonical model of intermittent turbulence. The results show that explicitly encoding transient instability mechanisms substantially extends practical prediction horizons compared to baseline observable-based approaches.
Extreme Event Aware ($η$-) Learning
Oct 22, 2025Quantifying and predicting rare and extreme events persists as a crucial yet challenging task in understanding complex dynamical systems. Many practical challenges arise from the infrequency and severity of these events, including the considerable variance of simple sampling methods and the substantial computational cost of high-fidelity numerical simulations. Numerous data-driven methods have recently been developed to tackle these challenges. However, a typical assumption for the success of these methods is the occurrence of multiple extreme events, either within the training dataset or during the sampling process. This leads to accurate models in regions of quiescent events but with high epistemic uncertainty in regions associated with extremes. To overcome this limitation, we introduce Extreme Event Aware (e2a or eta) or $\eta$-learning which does not assume the existence of extreme events in the available data. $\eta$-learning reduces the uncertainty even in `uncharted' extreme event regions, by enforcing the extreme event statistics of an observable indicative of extremeness during training, which can be available through qualitative arguments or estimated with unlabeled data. This type of statistical regularization results in models that fit the observed data, while enforcing consistency with the prescribed observable statistics, enabling the generation of unprecedented extreme events even when the training data lack extremes therein. Theoretical results based on optimal transport offer a rigorous justification and highlight the optimality of the introduced method. Additionally, extensive numerical experiments illustrate the favorable properties of the $\eta$-learning framework on several prototype problems and real-world precipitation downscaling problems.
Active search for Bifurcations
Jun 17, 2024Bifurcations mark qualitative changes of long-term behavior in dynamical systems and can often signal sudden ("hard") transitions or catastrophic events (divergences). Accurately locating them is critical not just for deeper understanding of observed dynamic behavior, but also for designing efficient interventions. When the dynamical system at hand is complex, possibly noisy, and expensive to sample, standard (e.g. continuation based) numerical methods may become impractical. We propose an active learning framework, where Bayesian Optimization is leveraged to discover saddle-node or Hopf bifurcations, from a judiciously chosen small number of vector field observations. Such an approach becomes especially attractive in systems whose state x parameter space exploration is resource-limited. It also naturally provides a framework for uncertainty quantification (aleatoric and epistemic), useful in systems with inherent stochasticity.
Multifidelity digital twin for real-time monitoring of structural dynamics in aquaculture net cages
Jun 10, 2024As the global population grows and climate change intensifies, sustainable food production is critical. Marine aquaculture offers a viable solution, providing a sustainable protein source. However, the industry's expansion requires novel technologies for remote management and autonomous operations. Digital twin technology can advance the aquaculture industry, but its adoption has been limited. Fish net cages, which are flexible floating structures, are critical yet vulnerable components of aquaculture farms. Exposed to harsh and dynamic marine environments, the cages experience significant loads and risk damage, leading to fish escapes, environmental impacts, and financial losses. We propose a multifidelity surrogate modeling framework for integration into a digital twin for real-time monitoring of aquaculture net cage structural dynamics under stochastic marine conditions. Central to this framework is the nonlinear autoregressive Gaussian process method, which learns complex, nonlinear cross-correlations between models of varying fidelity. It combines low-fidelity simulation data with a small set of high-fidelity field sensor measurements, which offer the real dynamics but are costly and spatially sparse. Validated at the SINTEF ACE fish farm in Norway, our digital twin receives online metocean data and accurately predicts net cage displacements and mooring line loads, aligning closely with field measurements. The proposed framework is beneficial where application-specific data are scarce, offering rapid predictions and real-time system representation. The developed digital twin prevents potential damages by assessing structural integrity and facilitates remote operations with unmanned underwater vehicles. Our work also compares GP and GCNs for predicting net cage deformation, highlighting the latter's effectiveness in complex structural applications.
Multifidelity surrogate modeling, NARGP, digital twin, aquaculture net cage, real-time monitoring, graph convolutional networks
Jun 06, 2024As the global population grows and climate change intensifies, sustainable food production is critical. Marine aquaculture offers a viable solution, providing a sustainable protein source. However, the industry's expansion requires novel technologies for remote management and autonomous operations. Digital twin technology can advance the aquaculture industry, but its adoption has been limited. Fish net cages, which are flexible floating structures, are critical yet vulnerable components of aquaculture farms. Exposed to harsh and dynamic marine environments, the cages experience significant loads and risk damage, leading to fish escapes, environmental impacts, and financial losses. We propose a multifidelity surrogate modeling framework for integration into a digital twin for real-time monitoring of aquaculture net cage structural dynamics under stochastic marine conditions. Central to this framework is the nonlinear autoregressive Gaussian process method, which learns complex, nonlinear cross-correlations between models of varying fidelity. It combines low-fidelity simulation data with a small set of high-fidelity field sensor measurements, which offer the real dynamics but are costly and spatially sparse. Validated at the SINTEF ACE fish farm in Norway, our digital twin receives online metocean data and accurately predicts net cage displacements and mooring line loads, aligning closely with field measurements. The proposed framework is beneficial where application-specific data are scarce, offering rapid predictions and real-time system representation. The developed digital twin prevents potential damages by assessing structural integrity and facilitates remote operations with unmanned underwater vehicles. Our work also compares GP and GCNs for predicting net cage deformation, highlighting the latter's effectiveness in complex structural applications.
Evaluation of machine learning architectures on the quantification of epistemic and aleatoric uncertainties in complex dynamical systems
Jun 27, 2023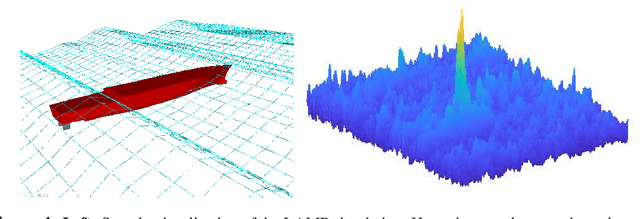

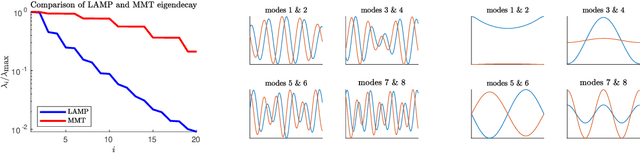
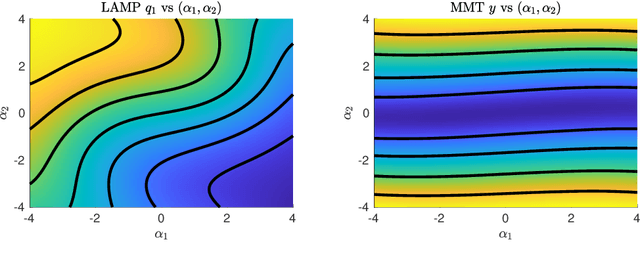
Machine learning methods for the construction of data-driven reduced order model models are used in an increasing variety of engineering domains, especially as a supplement to expensive computational fluid dynamics for design problems. An important check on the reliability of surrogate models is Uncertainty Quantification (UQ), a self assessed estimate of the model error. Accurate UQ allows for cost savings by reducing both the required size of training data sets and the required safety factors, while poor UQ prevents users from confidently relying on model predictions. We examine several machine learning techniques, including both Gaussian processes and a family UQ-augmented neural networks: Ensemble neural networks (ENN), Bayesian neural networks (BNN), Dropout neural networks (D-NN), and Gaussian neural networks (G-NN). We evaluate UQ accuracy (distinct from model accuracy) using two metrics: the distribution of normalized residuals on validation data, and the distribution of estimated uncertainties. We apply these metrics to two model data sets, representative of complex dynamical systems: an ocean engineering problem in which a ship traverses irregular wave episodes, and a dispersive wave turbulence system with extreme events, the Majda-McLaughlin-Tabak model. We present conclusions concerning model architecture and hyperparameter tuning.
Active Learning for Optimal Intervention Design in Causal Models
Sep 10, 2022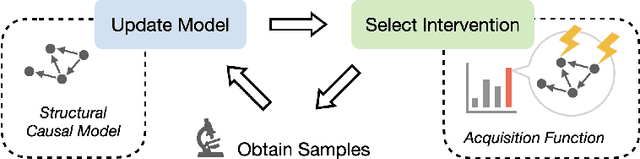
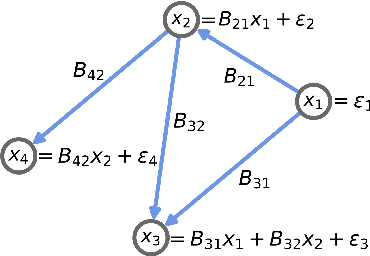
An important problem across disciplines is the discovery of interventions that produce a desired outcome. When the space of possible interventions is large, making an exhaustive search infeasible, experimental design strategies are needed. In this context, encoding the causal relationships between the variables, and thus the effect of interventions on the system, is critical in order to identify desirable interventions efficiently. We develop an iterative causal method to identify optimal interventions, as measured by the discrepancy between the post-interventional mean of the distribution and a desired target mean. We formulate an active learning strategy that uses the samples obtained so far from different interventions to update the belief about the underlying causal model, as well as to identify samples that are most informative about optimal interventions and thus should be acquired in the next batch. The approach employs a Bayesian update for the causal model and prioritizes interventions using a carefully designed, causally informed acquisition function. This acquisition function is evaluated in closed form, allowing for efficient optimization. The resulting algorithms are theoretically grounded with information-theoretic bounds and provable consistency results. We illustrate the method on both synthetic data and real-world biological data, namely gene expression data from Perturb-CITE-seq experiments, to identify optimal perturbations that induce a specific cell state transition; the proposed causal approach is observed to achieve better sample efficiency compared to several baselines. In both cases we observe that the causally informed acquisition function notably outperforms existing criteria allowing for optimal intervention design with significantly less experiments.
Information FOMO: The unhealthy fear of missing out on information. A method for removing misleading data for healthier models
Aug 27, 2022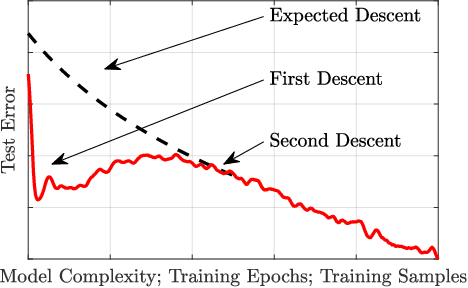
Not all data are equal. Misleading or unnecessary data can critically hinder the accuracy of Machine Learning (ML) models. When data is plentiful, misleading effects can be overcome, but in many real-world applications data is sparse and expensive to acquire. We present a method that substantially reduces the data size necessary to accurately train ML models, potentially opening the door for many new, limited-data applications in ML. Our method extracts the most informative data, while ignoring and omitting data that misleads the ML model to inferior generalization properties. Specifically, the method eliminates the phenomena of "double descent", where more data leads to worse performance. This approach brings several key features to the ML community. Notably, the method naturally converges and removes the traditional need to divide the dataset into training, testing, and validation data. Instead, the selection metric inherently assesses testing error. This ensures that key information is never wasted in testing or validation.
Discovering and forecasting extreme events via active learning in neural operators
Apr 05, 2022

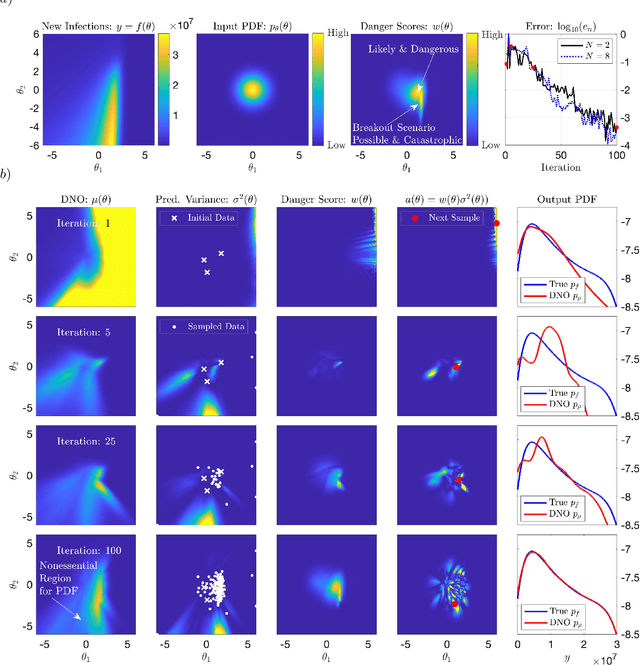
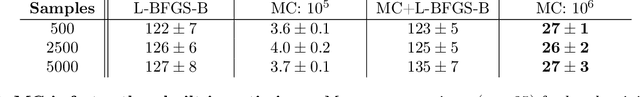
Extreme events in society and nature, such as pandemic spikes or rogue waves, can have catastrophic consequences. Characterizing extremes is difficult as they occur rarely, arise from seemingly benign conditions, and belong to complex and often unknown infinite-dimensional systems. Such challenges render attempts at characterizing them as moot. We address each of these difficulties by combining novel training schemes in Bayesian experimental design (BED) with an ensemble of deep neural operators (DNOs). This model-agnostic framework pairs a BED scheme that actively selects data for quantifying extreme events with an ensemble of DNOs that approximate infinite-dimensional nonlinear operators. We find that not only does this framework clearly beat Gaussian processes (GPs) but that 1) shallow ensembles of just two members perform best; 2) extremes are uncovered regardless of the state of initial data (i.e. with or without extremes); 3) our method eliminates "double-descent" phenomena; 4) the use of batches of suboptimal acquisition points compared to step-by-step global optima does not hinder BED performance; and 5) Monte Carlo acquisition outperforms standard minimizers in high-dimensions. Together these conclusions form the foundation of an AI-assisted experimental infrastructure that can efficiently infer and pinpoint critical situations across many domains, from physical to societal systems.
Structure and Distribution Metric for Quantifying the Quality of Uncertainty: Assessing Gaussian Processes, Deep Neural Nets, and Deep Neural Operators for Regression
Mar 09, 2022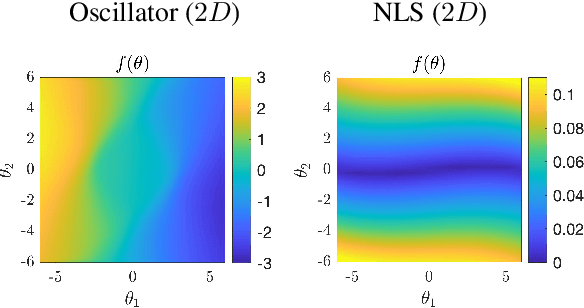
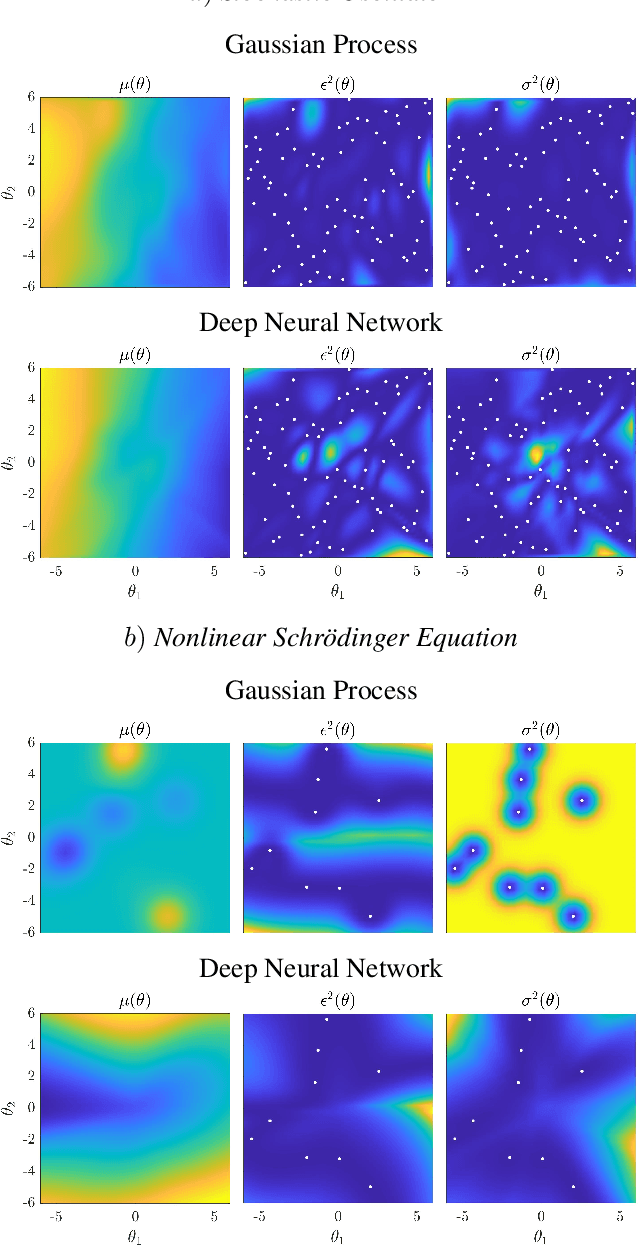
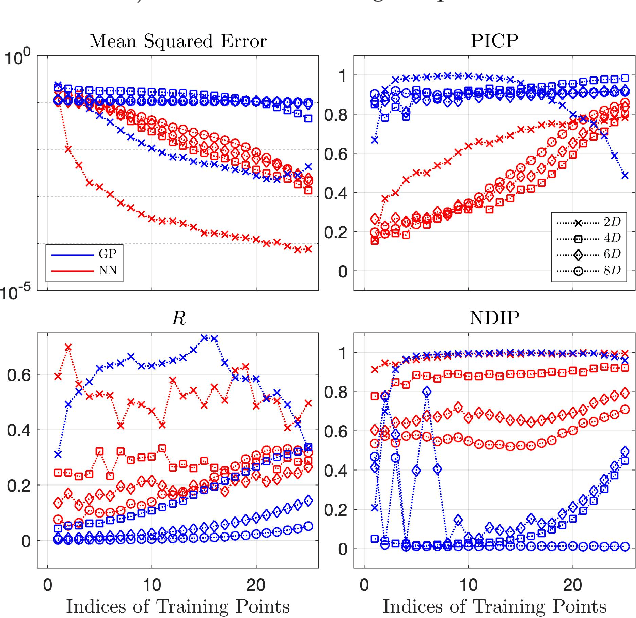
We propose two bounded comparison metrics that may be implemented to arbitrary dimensions in regression tasks. One quantifies the structure of uncertainty and the other quantifies the distribution of uncertainty. The structure metric assesses the similarity in shape and location of uncertainty with the true error, while the distribution metric quantifies the supported magnitudes between the two. We apply these metrics to Gaussian Processes (GPs), Ensemble Deep Neural Nets (DNNs), and Ensemble Deep Neural Operators (DNOs) on high-dimensional and nonlinear test cases. We find that comparing a model's uncertainty estimates with the model's squared error provides a compelling ground truth assessment. We also observe that both DNNs and DNOs, especially when compared to GPs, provide encouraging metric values in high dimensions with either sparse or plentiful data.