 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Methods for Automatic Relevance Determination
Paper and Code
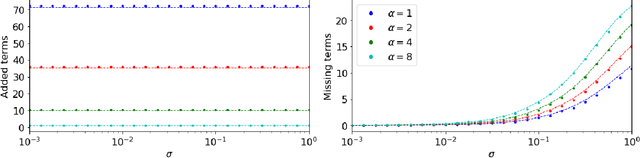
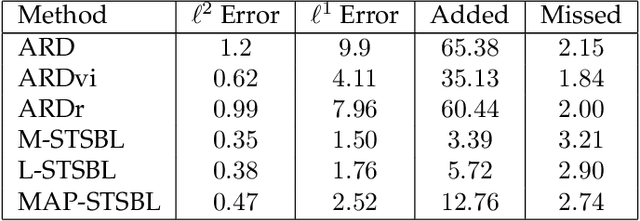
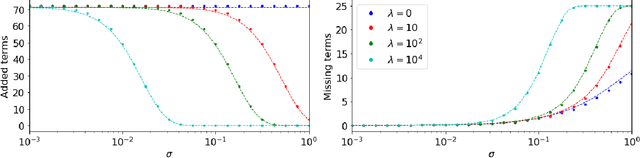
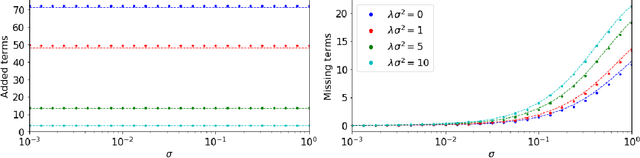
This work considers methods for imposing sparsity in Bayesian regression with applications in nonlinear system identification. We first review automatic relevance determination (ARD) and analytically demonstrate the need to additional regularization or thresholding to achieve sparse models. We then discuss two classes of methods, regularization based and thresholding based, which build on ARD to learn parsimonious solutions to linear problems. In the case of orthogonal covariates, we analytically demonstrate favorable performance with regards to learning a small set of active terms in a linear system with a sparse solution. Several example problems are presented to compare the set of proposed methods in terms of advantages and limitations to ARD in bases with hundreds of elements. The aim of this paper is to analyze and understand the assumptions that lead to several algorithms and to provide theoretical and empirical results so that the reader may gain insight and make more informed choices regarding sparse Bayesian regression.