 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation FOMO: The unhealthy fear of missing out on information. A method for removing misleading data for healthier models
Paper and Code
Aug 27, 2022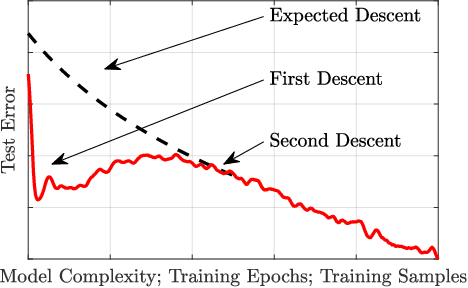
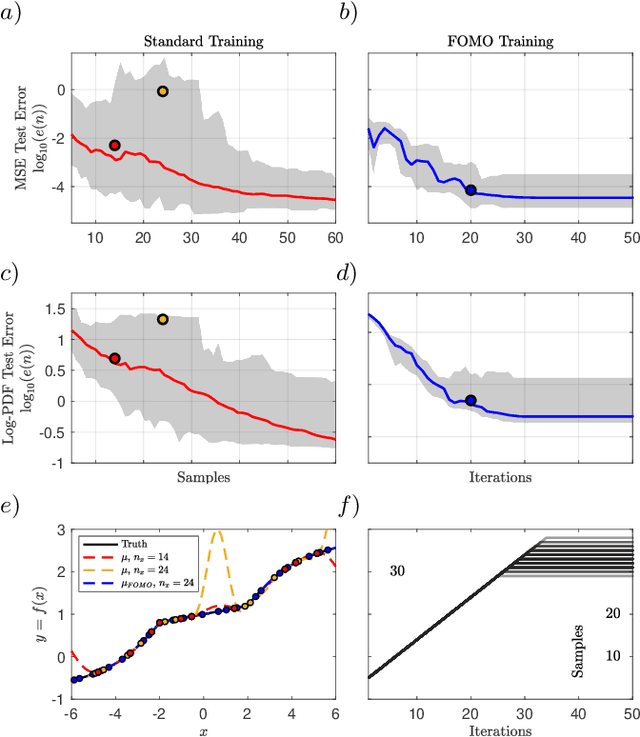
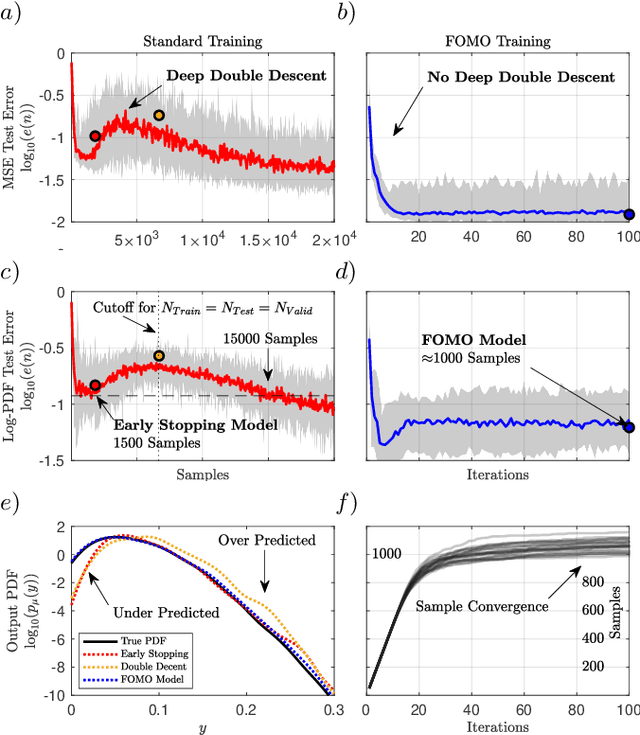
Not all data are equal. Misleading or unnecessary data can critically hinder the accuracy of Machine Learning (ML) models. When data is plentiful, misleading effects can be overcome, but in many real-world applications data is sparse and expensive to acquire. We present a method that substantially reduces the data size necessary to accurately train ML models, potentially opening the door for many new, limited-data applications in ML. Our method extracts the most informative data, while ignoring and omitting data that misleads the ML model to inferior generalization properties. Specifically, the method eliminates the phenomena of "double descent", where more data leads to worse performance. This approach brings several key features to the ML community. Notably, the method naturally converges and removes the traditional need to divide the dataset into training, testing, and validation data. Instead, the selection metric inherently assesses testing error. This ensures that key information is never wasted in testing or validation.