 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-constrained Gaussian Processes for Predicting Shockwave Hugoniot Curves
Jan 10, 2026A physics-constrained Gaussian Process regression framework is developed for predicting shocked material states along the Hugoniot curve using data from a small number of shockwave simulations. The proposed Gaussian process employs a probabilistic Taylor series expansion in conjunction with the Rankine-Hugoniot jump conditions between the various shocked material states to construct a thermodynamically consistent covariance function. This leads to the formulation of an optimization problem over a small number of interpretable hyperparameters and enables the identification of regime transitions, from a leading elastic wave to trailing plastic and phase transformation waves. This work is motivated by the need to investigate shock-driven material response for materials discovery and for offering mechanistic insights in regimes where experimental characterizations and simulations are costly. The proposed methodology relies on large-scale molecular dynamics which are an accurate but expensive computational alternative to experiments. Under these constraints, the proposed methodology establishes Hugoniot curves from a limited number of molecular dynamics simulations. We consider silicon carbide as a representative material and atomic-level simulations are performed using a reverse ballistic approach together with appropriate interatomic potentials. The framework reproduces the Hugoniot curve with satisfactory accuracy while also quantifying the uncertainty in the predictions using the Gaussian Process posterior.
Physics-informed Polynomial Chaos Expansion with Enhanced Constrained Optimization Solver and D-optimal Sampling
Dec 11, 2025Physics-informed polynomial chaos expansions (PC$^2$) provide an efficient physically constrained surrogate modeling framework by embedding governing equations and other physical constraints into the standard data-driven polynomial chaos expansions (PCE) and solving via the Karush-Kuhn-Tucker (KKT) conditions. This approach improves the physical interpretability of surrogate models while achieving high computational efficiency and accuracy. However, the performance and efficiency of PC$^2$ can still be degraded with high-dimensional parameter spaces, limited data availability, or unrepresentative training data. To address this problem, this study explores two complementary enhancements to the PC$^2$ framework. First, a numerically efficient constrained optimization solver, straightforward updating of Lagrange multipliers (SULM), is adopted as an alternative to the conventional KKT solver. The SULM method significantly reduces computational cost when solving physically constrained problems with high-dimensionality and derivative boundary conditions that require a large number of virtual points. Second, a D-optimal sampling strategy is utilized to select informative virtual points to improve the stability and achieve the balance of accuracy and efficiency of the PC$^2$. The proposed methods are integrated into the PC$^2$ framework and evaluated through numerical examples of representative physical systems governed by ordinary or partial differential equations. The results demonstrate that the enhanced PC$^2$ has better comprehensive capability than standard PC$^2$, and is well-suited for high-dimensional uncertainty quantification tasks.
Polynomial Chaos Expansion for Operator Learning
Aug 28, 2025Operator learning (OL) has emerged as a powerful tool in scientific machine learning (SciML) for approximating mappings between infinite-dimensional functional spaces. One of its main applications is learning the solution operator of partial differential equations (PDEs). While much of the progress in this area has been driven by deep neural network-based approaches such as Deep Operator Networks (DeepONet) and Fourier Neural Operator (FNO), recent work has begun to explore traditional machine learning methods for OL. In this work, we introduce polynomial chaos expansion (PCE) as an OL method. PCE has been widely used for uncertainty quantification (UQ) and has recently gained attention in the context of SciML. For OL, we establish a mathematical framework that enables PCE to approximate operators in both purely data-driven and physics-informed settings. The proposed framework reduces the task of learning the operator to solving a system of equations for the PCE coefficients. Moreover, the framework provides UQ by simply post-processing the PCE coefficients, without any additional computational cost. We apply the proposed method to a diverse set of PDE problems to demonstrate its capabilities. Numerical results demonstrate the strong performance of the proposed method in both OL and UQ tasks, achieving excellent numerical accuracy and computational efficiency.
Joint space-time wind field data extrapolation and uncertainty quantification using nonparametric Bayesian dictionary learning
Jul 15, 2025A methodology is developed, based on nonparametric Bayesian dictionary learning, for joint space-time wind field data extrapolation and estimation of related statistics by relying on limited/incomplete measurements. Specifically, utilizing sparse/incomplete measured data, a time-dependent optimization problem is formulated for determining the expansion coefficients of an associated low-dimensional representation of the stochastic wind field. Compared to an alternative, standard, compressive sampling treatment of the problem, the developed methodology exhibits the following advantages. First, the Bayesian formulation enables also the quantification of the uncertainty in the estimates. Second, the requirement in standard CS-based applications for an a priori selection of the expansion basis is circumvented. Instead, this is done herein in an adaptive manner based on the acquired data. Overall, the methodology exhibits enhanced extrapolation accuracy, even in cases of high-dimensional data of arbitrary form, and of relatively large extrapolation distances. Thus, it can be used, potentially, in a wide range of wind engineering applications where various constraints dictate the use of a limited number of sensors. The efficacy of the methodology is demonstrated by considering two case studies. The first relates to the extrapolation of simulated wind velocity records consistent with a prescribed joint wavenumber-frequency power spectral density in a three-dimensional domain (2D and time). The second pertains to the extrapolation of four-dimensional (3D and time) boundary layer wind tunnel experimental data that exhibit significant spatial variability and non-Gaussian characteristics.
Neural Chaos: A Spectral Stochastic Neural Operator
Feb 17, 2025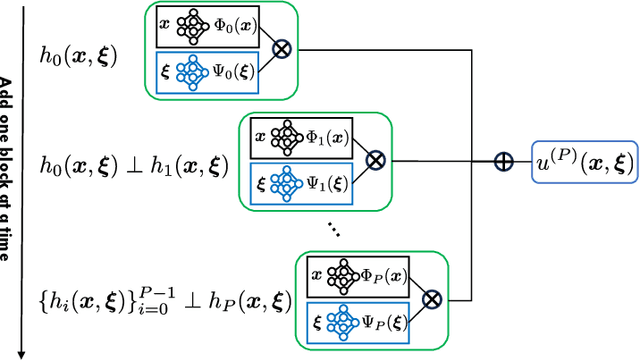
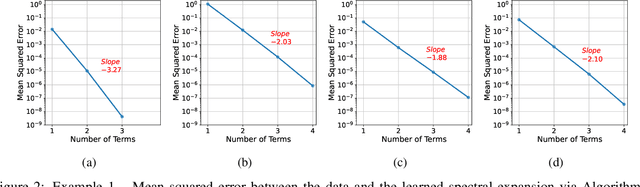
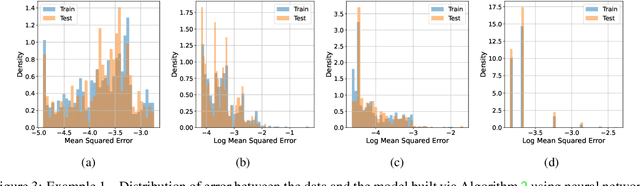
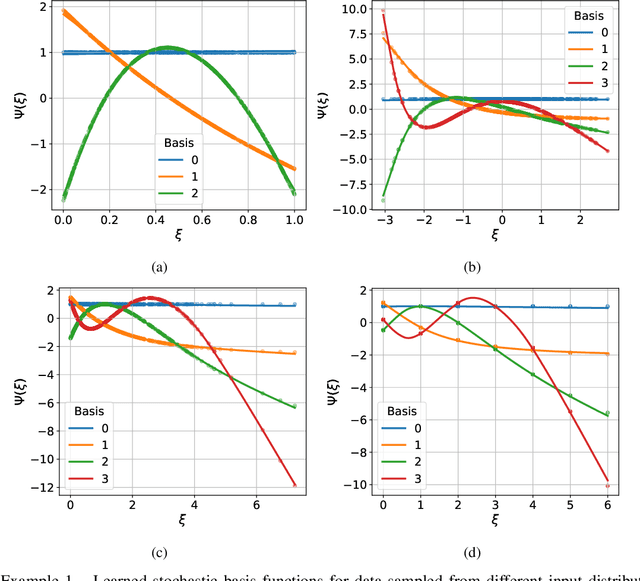
Building surrogate models with uncertainty quantification capabilities is essential for many engineering applications where randomness, such as variability in material properties, is unavoidable. Polynomial Chaos Expansion (PCE) is widely recognized as a to-go method for constructing stochastic solutions in both intrusive and non-intrusive ways. Its application becomes challenging, however, with complex or high-dimensional processes, as achieving accuracy requires higher-order polynomials, which can increase computational demands and or the risk of overfitting. Furthermore, PCE requires specialized treatments to manage random variables that are not independent, and these treatments may be problem-dependent or may fail with increasing complexity. In this work, we adopt the spectral expansion formalism used in PCE; however, we replace the classical polynomial basis functions with neural network (NN) basis functions to leverage their expressivity. To achieve this, we propose an algorithm that identifies NN-parameterized basis functions in a purely data-driven manner, without any prior assumptions about the joint distribution of the random variables involved, whether independent or dependent. The proposed algorithm identifies each NN-parameterized basis function sequentially, ensuring they are orthogonal with respect to the data distribution. The basis functions are constructed directly on the joint stochastic variables without requiring a tensor product structure. This approach may offer greater flexibility for complex stochastic models, while simplifying implementation compared to the tensor product structures typically used in PCE to handle random vectors. We demonstrate the effectiveness of the proposed scheme through several numerical examples of varying complexity and provide comparisons with classical PCE.
Synergistic Learning with Multi-Task DeepONet for Efficient PDE Problem Solving
Aug 05, 2024Multi-task learning (MTL) is an inductive transfer mechanism designed to leverage useful information from multiple tasks to improve generalization performance compared to single-task learning. It has been extensively explored in traditional machine learning to address issues such as data sparsity and overfitting in neural networks. In this work, we apply MTL to problems in science and engineering governed by partial differential equations (PDEs). However, implementing MTL in this context is complex, as it requires task-specific modifications to accommodate various scenarios representing different physical processes. To this end, we present a multi-task deep operator network (MT-DeepONet) to learn solutions across various functional forms of source terms in a PDE and multiple geometries in a single concurrent training session. We introduce modifications in the branch network of the vanilla DeepONet to account for various functional forms of a parameterized coefficient in a PDE. Additionally, we handle parameterized geometries by introducing a binary mask in the branch network and incorporating it into the loss term to improve convergence and generalization to new geometry tasks. Our approach is demonstrated on three benchmark problems: (1) learning different functional forms of the source term in the Fisher equation; (2) learning multiple geometries in a 2D Darcy Flow problem and showcasing better transfer learning capabilities to new geometries; and (3) learning 3D parameterized geometries for a heat transfer problem and demonstrate the ability to predict on new but similar geometries. Our MT-DeepONet framework offers a novel approach to solving PDE problems in engineering and science under a unified umbrella based on synergistic learning that reduces the overall training cost for neural operators.
A Resolution Independent Neural Operator
Jul 17, 2024



The Deep operator network (DeepONet) is a powerful yet simple neural operator architecture that utilizes two deep neural networks to learn mappings between infinite-dimensional function spaces. This architecture is highly flexible, allowing the evaluation of the solution field at any location within the desired domain. However, it imposes a strict constraint on the input space, requiring all input functions to be discretized at the same locations; this limits its practical applications. In this work, we introduce a Resolution Independent Neural Operator (RINO) that provides a framework to make DeepONet resolution-independent, enabling it to handle input functions that are arbitrarily, but sufficiently finely, discretized. To this end, we propose a dictionary learning algorithm to adaptively learn a set of appropriate continuous basis functions, parameterized as implicit neural representations (INRs), from the input data. These basis functions are then used to project arbitrary input function data as a point cloud onto an embedding space (i.e., a vector space of finite dimensions) with dimensionality equal to the dictionary size, which can be directly used by DeepONet without any architectural changes. In particular, we utilize sinusoidal representation networks (SIRENs) as our trainable INR basis functions. We demonstrate the robustness and applicability of RINO in handling arbitrarily (but sufficiently richly) sampled input functions during both training and inference through several numerical examples.
Bayesian neural networks for predicting uncertainty in full-field material response
Jun 21, 2024Stress and material deformation field predictions are among the most important tasks in computational mechanics. These predictions are typically made by solving the governing equations of continuum mechanics using finite element analysis, which can become computationally prohibitive considering complex microstructures and material behaviors. Machine learning (ML) methods offer potentially cost effective surrogates for these applications. However, existing ML surrogates are either limited to low-dimensional problems and/or do not provide uncertainty estimates in the predictions. This work proposes an ML surrogate framework for stress field prediction and uncertainty quantification for diverse materials microstructures. A modified Bayesian U-net architecture is employed to provide a data-driven image-to-image mapping from initial microstructure to stress field with prediction (epistemic) uncertainty estimates. The Bayesian posterior distributions for the U-net parameters are estimated using three state-of-the-art inference algorithms: the posterior sampling-based Hamiltonian Monte Carlo method and two variational approaches, the Monte-Carlo Dropout method and the Bayes by Backprop algorithm. A systematic comparison of the predictive accuracy and uncertainty estimates for these methods is performed for a fiber reinforced composite material and polycrystalline microstructure application. It is shown that the proposed methods yield predictions of high accuracy compared to the FEA solution, while uncertainty estimates depend on the inference approach. Generally, the Hamiltonian Monte Carlo and Bayes by Backprop methods provide consistent uncertainty estimates. Uncertainty estimates from Monte Carlo Dropout, on the other hand, are more difficult to interpret and depend strongly on the method's design.
Physics-constrained polynomial chaos expansion for scientific machine learning and uncertainty quantification
Feb 23, 2024We present a novel physics-constrained polynomial chaos expansion as a surrogate modeling method capable of performing both scientific machine learning (SciML) and uncertainty quantification (UQ) tasks. The proposed method possesses a unique capability: it seamlessly integrates SciML into UQ and vice versa, which allows it to quantify the uncertainties in SciML tasks effectively and leverage SciML for improved uncertainty assessment during UQ-related tasks. The proposed surrogate model can effectively incorporate a variety of physical constraints, such as governing partial differential equations (PDEs) with associated initial and boundary conditions constraints, inequality-type constraints (e.g., monotonicity, convexity, non-negativity, among others), and additional a priori information in the training process to supplement limited data. This ensures physically realistic predictions and significantly reduces the need for expensive computational model evaluations to train the surrogate model. Furthermore, the proposed method has a built-in uncertainty quantification (UQ) feature to efficiently estimate output uncertainties. To demonstrate the effectiveness of the proposed method, we apply it to a diverse set of problems, including linear/non-linear PDEs with deterministic and stochastic parameters, data-driven surrogate modeling of a complex physical system, and UQ of a stochastic system with parameters modeled as random fields.
Polynomial Chaos Expansions on Principal Geodesic Grassmannian Submanifolds for Surrogate Modeling and Uncertainty Quantification
Jan 30, 2024



In this work we introduce a manifold learning-based surrogate modeling framework for uncertainty quantification in high-dimensional stochastic systems. Our first goal is to perform data mining on the available simulation data to identify a set of low-dimensional (latent) descriptors that efficiently parameterize the response of the high-dimensional computational model. To this end, we employ Principal Geodesic Analysis on the Grassmann manifold of the response to identify a set of disjoint principal geodesic submanifolds, of possibly different dimension, that captures the variation in the data. Since operations on the Grassmann require the data to be concentrated, we propose an adaptive algorithm based on Riemanniann K-means and the minimization of the sample Frechet variance on the Grassmann manifold to identify "local" principal geodesic submanifolds that represent different system behavior across the parameter space. Polynomial chaos expansion is then used to construct a mapping between the random input parameters and the projection of the response on these local principal geodesic submanifolds. The method is demonstrated on four test cases, a toy-example that involves points on a hypersphere, a Lotka-Volterra dynamical system, a continuous-flow stirred-tank chemical reactor system, and a two-dimensional Rayleigh-Benard convection problem