 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning surrogate models of many-body dispersion interactions in polymer melts
Mar 19, 2025



Accurate prediction of many-body dispersion (MBD) interactions is essential for understanding the van der Waals forces that govern the behavior of many complex molecular systems. However, the high computational cost of MBD calculations limits their direct application in large-scale simulations. In this work, we introduce a machine learning surrogate model specifically designed to predict MBD forces in polymer melts, a system that demands accurate MBD description and offers structural advantages for machine learning approaches. Our model is based on a trimmed SchNet architecture that selectively retains the most relevant atomic connections and incorporates trainable radial basis functions for geometric encoding. We validate our surrogate model on datasets from polyethylene, polypropylene, and polyvinyl chloride melts, demonstrating high predictive accuracy and robust generalization across diverse polymer systems. In addition, the model captures key physical features, such as the characteristic decay behavior of MBD interactions, providing valuable insights for optimizing cutoff strategies. Characterized by high computational efficiency, our surrogate model enables practical incorporation of MBD effects into large-scale molecular simulations.
Implementing LLMs in industrial process modeling: Addressing Categorical Variables
Sep 27, 2024



Important variables of processes are, in many occasions, categorical, i.e. names or labels representing, e.g. categories of inputs, or types of reactors or a sequence of steps. In this work, we use Large Language Models (LLMs) to derive embeddings of such inputs that represent their actual meaning, or reflect the ``distances" between categories, i.e. how similar or dissimilar they are. This is a marked difference from the current standard practice of using binary, or one-hot encoding to replace categorical variables with sequences of ones and zeros. Combined with dimensionality reduction techniques, either linear such as Principal Components Analysis (PCA), or nonlinear such as Uniform Manifold Approximation and Projection (UMAP), the proposed approach leads to a \textit{meaningful}, low-dimensional feature space. The significance of obtaining meaningful embeddings is illustrated in the context of an industrial coating process for cutting tools that includes both numerical and categorical inputs. The proposed approach enables feature importance which is a marked improvement compared to the current state-of-the-art (SotA) in the encoding of categorical variables.
Graph Representation Learning Strategies for Omics Data: A Case Study on Parkinson's Disease
Jun 20, 2024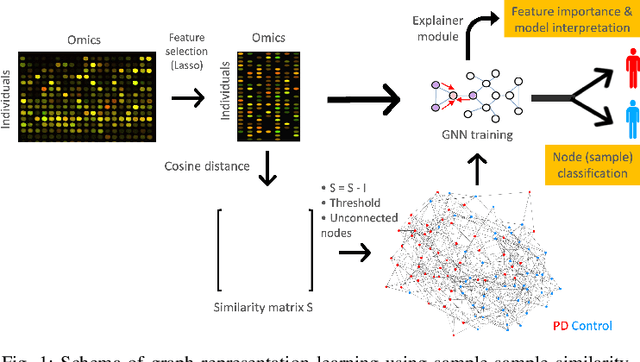
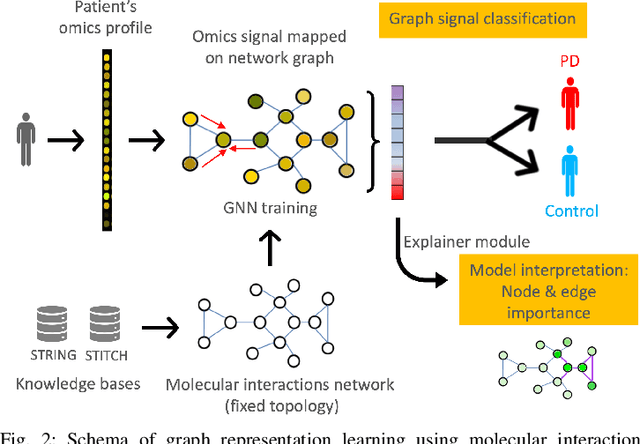
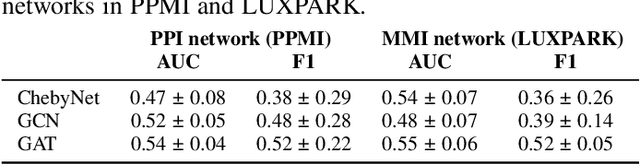
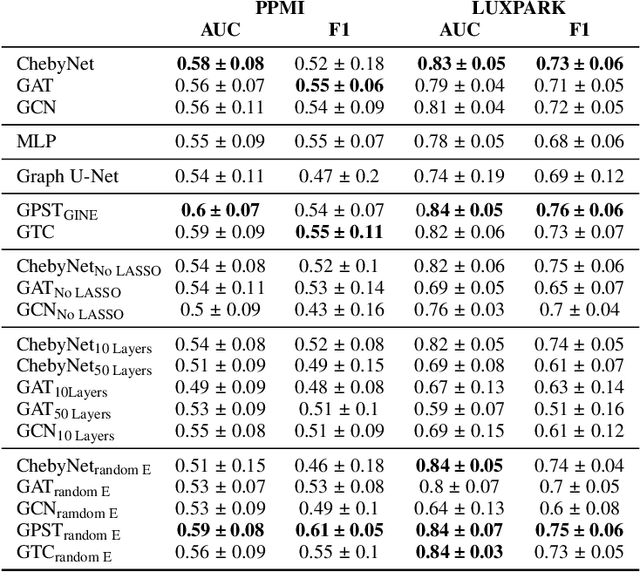
Omics data analysis is crucial for studying complex diseases, but its high dimensionality and heterogeneity challenge classical statistical and machine learning methods. Graph neural networks have emerged as promising alternatives, yet the optimal strategies for their design and optimization in real-world biomedical challenges remain unclear. This study evaluates various graph representation learning models for case-control classification using high-throughput biological data from Parkinson's disease and control samples. We compare topologies derived from sample similarity networks and molecular interaction networks, including protein-protein and metabolite-metabolite interactions (PPI, MMI). Graph Convolutional Network (GCNs), Chebyshev spectral graph convolution (ChebyNet), and Graph Attention Network (GAT), are evaluated alongside advanced architectures like graph transformers, the graph U-net, and simpler models like multilayer perceptron (MLP). These models are systematically applied to transcriptomics and metabolomics data independently. Our comparative analysis highlights the benefits and limitations of various architectures in extracting patterns from omics data, paving the way for more accurate and interpretable models in biomedical research.
Discovering deposition process regimes: leveraging unsupervised learning for process insights, surrogate modeling, and sensitivity analysis
May 24, 2024


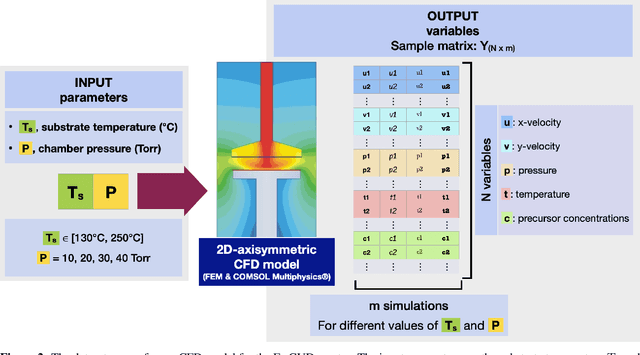
This work introduces a comprehensive approach utilizing data-driven methods to elucidate the deposition process regimes in Chemical Vapor Deposition (CVD) reactors and the interplay of physical mechanism that dominate in each one of them. Through this work, we address three key objectives. Firstly, our methodology relies on process outcomes, derived by a detailed CFD model, to identify clusters of "outcomes" corresponding to distinct process regimes, wherein the relative influence of input variables undergoes notable shifts. This phenomenon is experimentally validated through Arrhenius plot analysis, affirming the efficacy of our approach. Secondly, we demonstrate the development of an efficient surrogate model, based on Polynomial Chaos Expansion (PCE), that maintains accuracy, facilitating streamlined computational analyses. Finally, as a result of PCE, sensitivity analysis is made possible by means of Sobol' indices, that quantify the impact of process inputs across identified regimes. The insights gained from our analysis contribute to the formulation of hypotheses regarding phenomena occurring beyond the transition regime. Notably, the significance of temperature even in the diffusion-limited regime, as evidenced by the Arrhenius plot, suggests activation of gas phase reactions at elevated temperatures. Importantly, our proposed methods yield insights that align with experimental observations and theoretical principles, aiding decision-making in process design and optimization. By circumventing the need for costly and time-consuming experiments, our approach offers a pragmatic pathway towards enhanced process efficiency. Moreover, this study underscores the potential of data-driven computational methods for innovating reactor design paradigms.
Integrating supervised and unsupervised learning approaches to unveil critical process inputs
May 13, 2024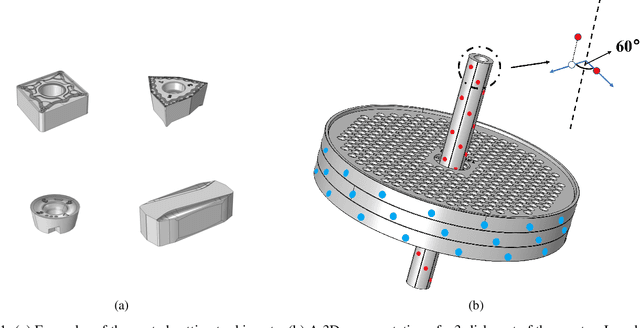



This study introduces a machine learning framework tailored to large-scale industrial processes characterized by a plethora of numerical and categorical inputs. The framework aims to (i) discern critical parameters influencing the output and (ii) generate accurate out-of-sample qualitative and quantitative predictions of production outcomes. Specifically, we address the pivotal question of the significance of each input in shaping the process outcome, using an industrial Chemical Vapor Deposition (CVD) process as an example. The initial objective involves merging subject matter expertise and clustering techniques exclusively on the process output, here, coating thickness measurements at various positions in the reactor. This approach identifies groups of production runs that share similar qualitative characteristics, such as film mean thickness and standard deviation. In particular, the differences of the outcomes represented by the different clusters can be attributed to differences in specific inputs, indicating that these inputs are critical for the production outcome. Leveraging this insight, we subsequently implement supervised classification and regression methods using the identified critical process inputs. The proposed methodology proves to be valuable in scenarios with a multitude of inputs and insufficient data for the direct application of deep learning techniques, providing meaningful insights into the underlying processes.
Convolution, aggregation and attention based deep neural networks for accelerating simulations in mechanics
Dec 01, 2022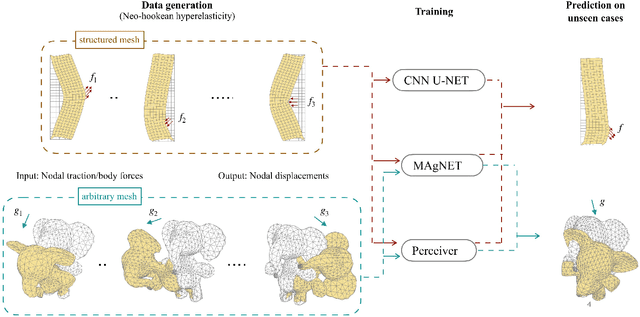

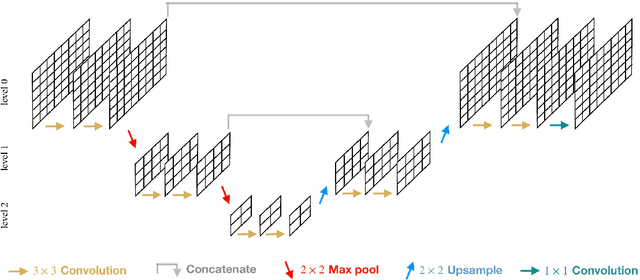

Deep learning surrogate models are being increasingly used in accelerating scientific simulations as a replacement for costly conventional numerical techniques. However, their use remains a significant challenge when dealing with real-world complex examples. In this work, we demonstrate three types of neural network architectures for efficient learning of highly non-linear deformations of solid bodies. The first two architectures are based on the recently proposed CNN U-NET and MAgNET (graph U-NET) frameworks which have shown promising performance for learning on mesh-based data. The third architecture is Perceiver IO, a very recent architecture that belongs to the family of attention-based neural networks--a class that has revolutionised diverse engineering fields and is still unexplored in computational mechanics. We study and compare the performance of all three networks on two benchmark examples, and show their capabilities to accurately predict the non-linear mechanical responses of soft bodies.
MAgNET: A Graph U-Net Architecture for Mesh-Based Simulations
Nov 01, 2022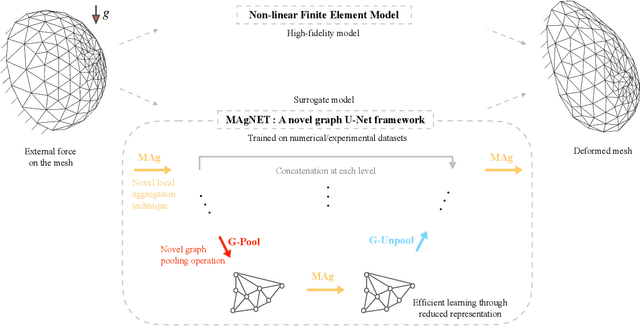

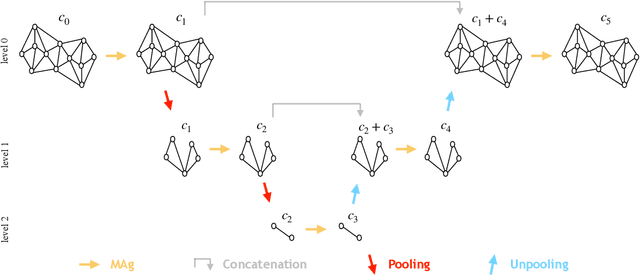

Mesh-based approaches are fundamental to solving physics-based simulations, however, they require significant computational efforts, especially for highly non-linear problems. Deep learning techniques accelerate physics-based simulations, however, they fail to perform efficiently as the size and complexity of the problem increases. Hence in this work, we propose MAgNET: Multi-channel Aggregation Network, a novel geometric deep learning framework for performing supervised learning on mesh-based graph data. MAgNET is based on the proposed MAg (Multichannel Aggregation) operation which generalises the concept of multi-channel local operations in convolutional neural networks to arbitrary non-grid inputs. MAg can efficiently perform non-linear regression mapping for graph-structured data. MAg layers are interleaved with the proposed novel graph pooling operations to constitute a graph U-Net architecture that is robust, handles arbitrary complex meshes and scales efficiently with the size of the problem. Although not limited to the type of discretisation, we showcase the predictive capabilities of MAgNET for several non-linear finite element simulations.
FEM-based Real-Time Simulations of Large Deformations with Probabilistic Deep Learning
Nov 02, 2021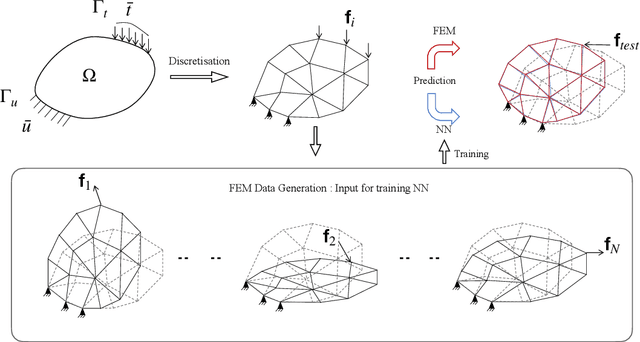
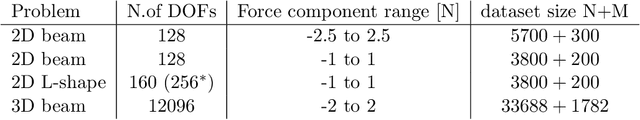
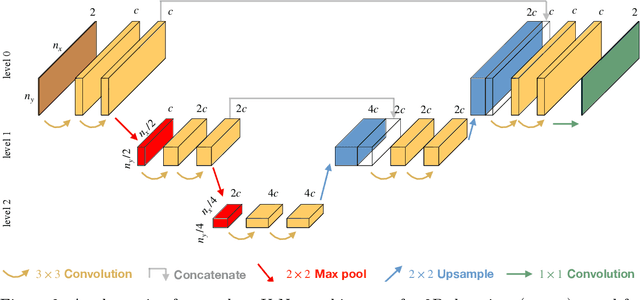

For many engineering applications, such as real-time simulations or control, conventional solution techniques of the underlying nonlinear problems are usually computationally too expensive. In this work, we propose a highly efficient deep-learning surrogate framework that is able to predict the response of hyper-elastic bodies under load. The surrogate model takes the form of special convolutional neural network architecture, so-called U-Net, which is trained with force-displacement data obtained with the finite element method. We propose deterministic- and probabilistic versions of the framework and study it for three benchmark problems. In particular, we check the capabilities of the Maximum Likelihood and the Variational Bayes Inference formulations to assess the confidence intervals of solutions.
Machine learning in the social and health sciences
Jun 20, 2021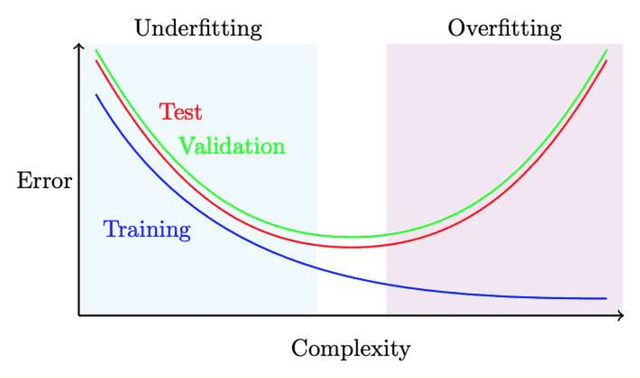

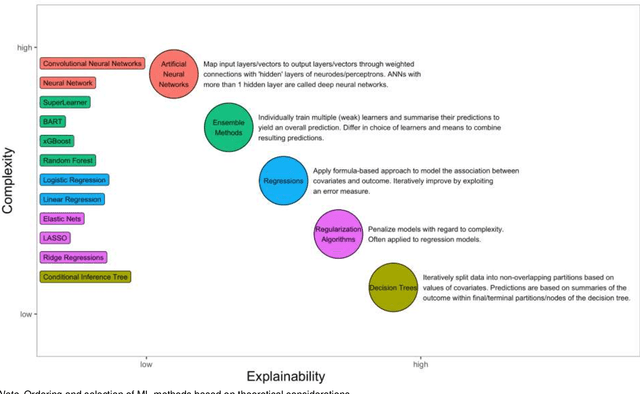
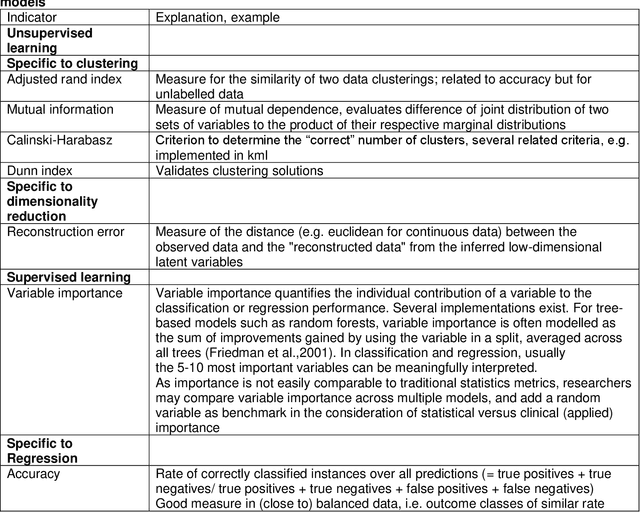
The uptake of machine learning (ML) approaches in the social and health sciences has been rather slow, and research using ML for social and health research questions remains fragmented. This may be due to the separate development of research in the computational/data versus social and health sciences as well as a lack of accessible overviews and adequate training in ML techniques for non data science researchers. This paper provides a meta-mapping of research questions in the social and health sciences to appropriate ML approaches, by incorporating the necessary requirements to statistical analysis in these disciplines. We map the established classification into description, prediction, and causal inference to common research goals, such as estimating prevalence of adverse health or social outcomes, predicting the risk of an event, and identifying risk factors or causes of adverse outcomes. This meta-mapping aims at overcoming disciplinary barriers and starting a fluid dialogue between researchers from the social and health sciences and methodologically trained researchers. Such mapping may also help to fully exploit the benefits of ML while considering domain-specific aspects relevant to the social and health sciences, and hopefully contribute to the acceleration of the uptake of ML applications to advance both basic and applied social and health sciences research.
Bayesian Convolutional Neural Networks as probabilistic surrogates for the fast prediction of stress fields in structures with microscale features
Dec 17, 2020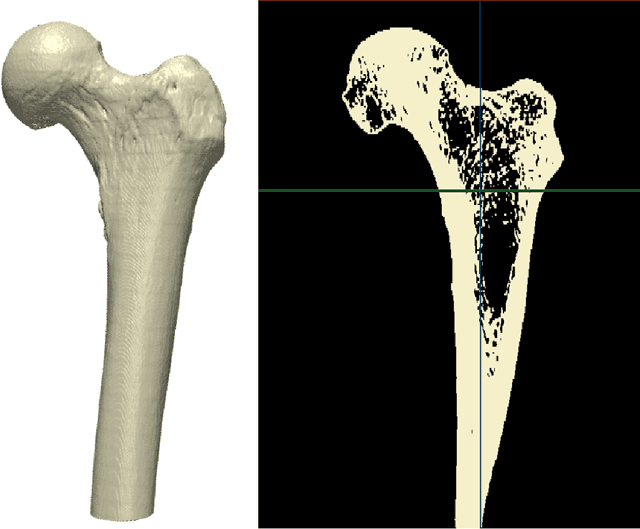
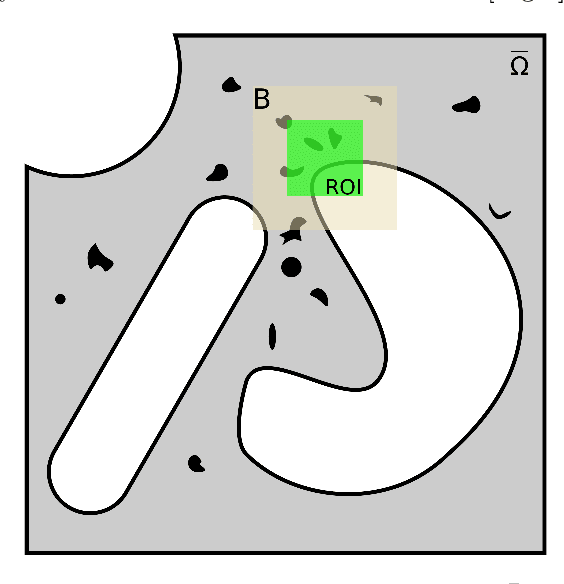
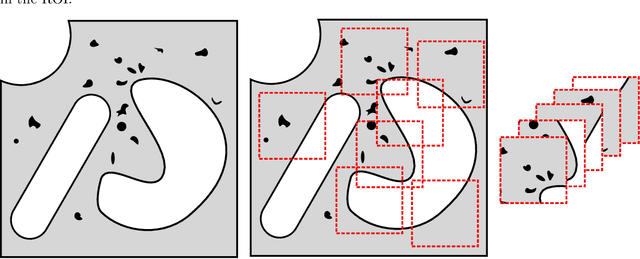
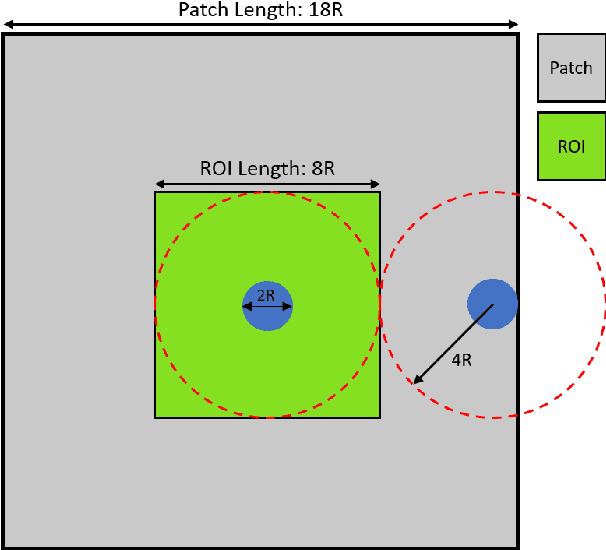
Finite Element Analysis (FEA) for stress prediction in structures with microstructural features is computationally expensive since those features are much smaller than the other geometric features of the structure. The accurate prediction of the additional stress generated by such microstructural features therefore requires a very fine FE mesh. Omitting or averaging the effect of the microstructural features from FEA models is standard practice, resulting in faster calculations of global stress fields, which, assuming some degree of scale separability, may then be complemented by local defect analyses. The purpose of this work is to train an Encoder-Decoder Convolutional Neural Networks (CNN) to automatically add local fine-scale stress corrections to coarse stress predictions around defects. We wish to understand to what extent such a framework may provide reliable stress predictions inside and outside the training set, i.e. for unseen coarse scale geometries and stress distributions and/or unseen defect geometries. Ultimately, we aim to develop efficient offline data generation and online data acquisition methods to maximise the domain of validity of the CNN predictions. To achieve these ambitious goals, we will deploy a Bayesian approach providing not point estimates, but credible intervals of the fine-scale stress field, as a means to evaluate the uncertainty of the predictions. The uncertainty quantified by the network will automatically encompass the lack of knowledge due to unseen macro and micro features, and the lack of knowledge due to the potential lack of scale separability. This uncertainty will be used in a Selective Learning framework to reduce the data requirements of the network. In this work we will investigate stress prediction in 2D composite structures with randomly distributed circular pores.