 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Expected Loss of Preconditioned Langevin Dynamics Reveals the Hessian Rank
Paper and Code
Feb 21, 2024


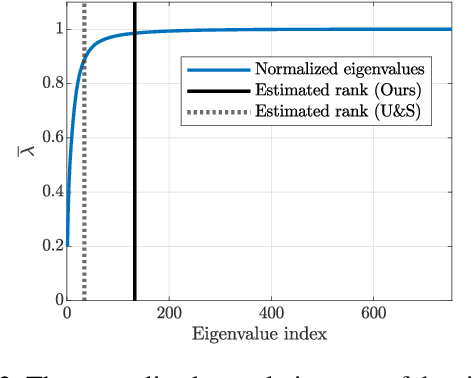
Langevin dynamics (LD) is widely used for sampling from distributions and for optimization. In this work, we derive a closed-form expression for the expected loss of preconditioned LD near stationary points of the objective function. We use the fact that at the vicinity of such points, LD reduces to an Ornstein-Uhlenbeck process, which is amenable to convenient mathematical treatment. Our analysis reveals that when the preconditioning matrix satisfies a particular relation with respect to the noise covariance, LD's expected loss becomes proportional to the rank of the objective's Hessian. We illustrate the applicability of this result in the context of neural networks, where the Hessian rank has been shown to capture the complexity of the predictor function but is usually computationally hard to probe. Finally, we use our analysis to compare SGD-like and Adam-like preconditioners and identify the regimes under which each of them leads to a lower expected loss.