 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency
Oct 05, 2023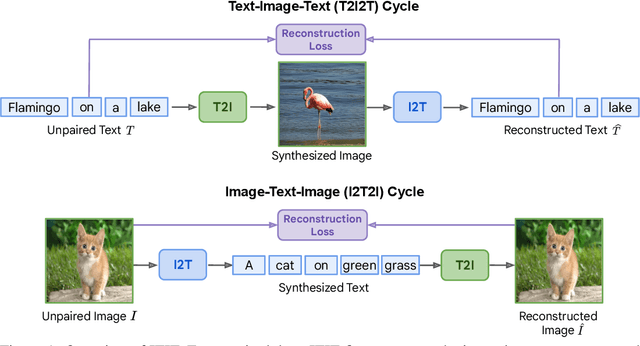
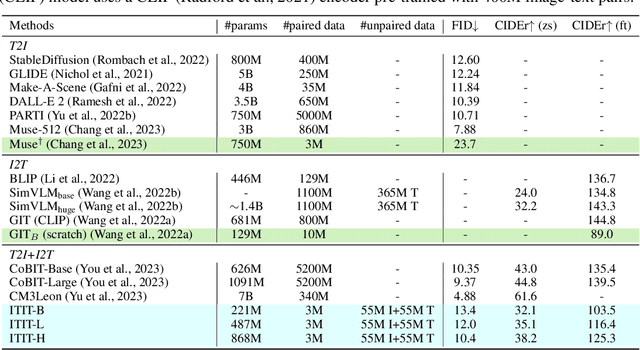
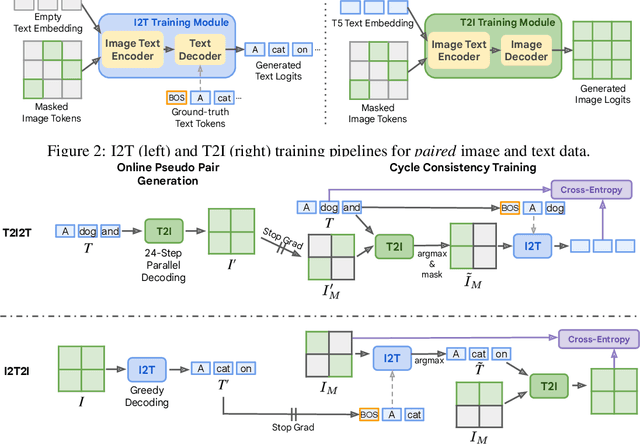
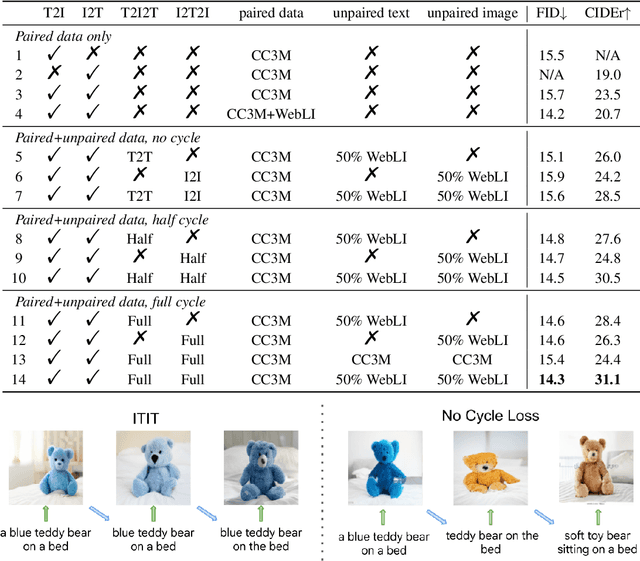
Current vision-language generative models rely on expansive corpora of paired image-text data to attain optimal performance and generalization capabilities. However, automatically collecting such data (e.g. via large-scale web scraping) leads to low quality and poor image-text correlation, while human annotation is more accurate but requires significant manual effort and expense. We introduce $\textbf{ITIT}$ ($\textbf{I}$n$\textbf{T}$egrating $\textbf{I}$mage $\textbf{T}$ext): an innovative training paradigm grounded in the concept of cycle consistency which allows vision-language training on unpaired image and text data. ITIT is comprised of a joint image-text encoder with disjoint image and text decoders that enable bidirectional image-to-text and text-to-image generation in a single framework. During training, ITIT leverages a small set of paired image-text data to ensure its output matches the input reasonably well in both directions. Simultaneously, the model is also trained on much larger datasets containing only images or texts. This is achieved by enforcing cycle consistency between the original unpaired samples and the cycle-generated counterparts. For instance, it generates a caption for a given input image and then uses the caption to create an output image, and enforces similarity between the input and output images. Our experiments show that ITIT with unpaired datasets exhibits similar scaling behavior as using high-quality paired data. We demonstrate image generation and captioning performance on par with state-of-the-art text-to-image and image-to-text models with orders of magnitude fewer (only 3M) paired image-text data.
StyleDrop: Text-to-Image Generation in Any Style
Jun 01, 2023
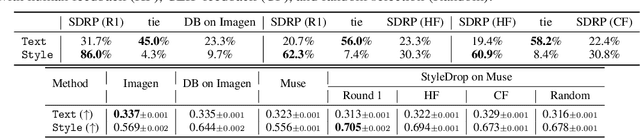


Pre-trained large text-to-image models synthesize impressive images with an appropriate use of text prompts. However, ambiguities inherent in natural language and out-of-distribution effects make it hard to synthesize image styles, that leverage a specific design pattern, texture or material. In this paper, we introduce StyleDrop, a method that enables the synthesis of images that faithfully follow a specific style using a text-to-image model. The proposed method is extremely versatile and captures nuances and details of a user-provided style, such as color schemes, shading, design patterns, and local and global effects. It efficiently learns a new style by fine-tuning very few trainable parameters (less than $1\%$ of total model parameters) and improving the quality via iterative training with either human or automated feedback. Better yet, StyleDrop is able to deliver impressive results even when the user supplies only a single image that specifies the desired style. An extensive study shows that, for the task of style tuning text-to-image models, StyleDrop implemented on Muse convincingly outperforms other methods, including DreamBooth and textual inversion on Imagen or Stable Diffusion. More results are available at our project website: https://styledrop.github.io
SPADE: Self-supervised Pretraining for Acoustic DisEntanglement
Feb 03, 2023
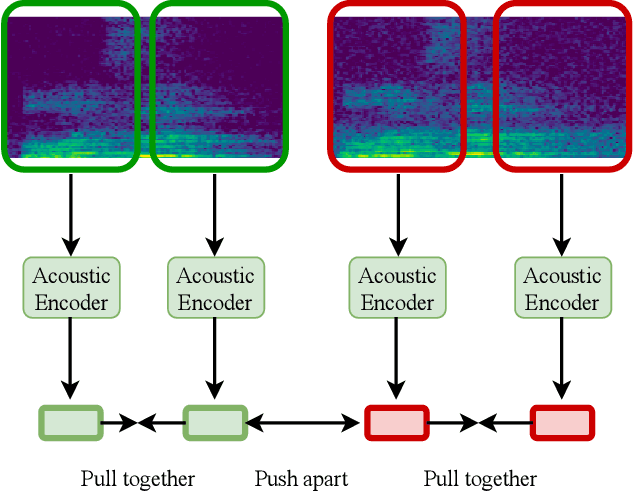

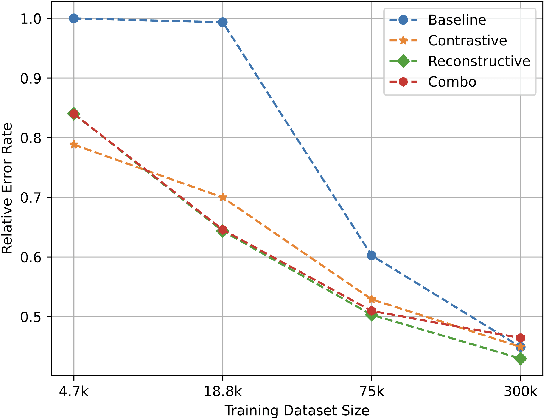
Self-supervised representation learning approaches have grown in popularity due to the ability to train models on large amounts of unlabeled data and have demonstrated success in diverse fields such as natural language processing, computer vision, and speech. Previous self-supervised work in the speech domain has disentangled multiple attributes of speech such as linguistic content, speaker identity, and rhythm. In this work, we introduce a self-supervised approach to disentangle room acoustics from speech and use the acoustic representation on the downstream task of device arbitration. Our results demonstrate that our proposed approach significantly improves performance over a baseline when labeled training data is scarce, indicating that our pretraining scheme learns to encode room acoustic information while remaining invariant to other attributes of the speech signal.
Muse: Text-To-Image Generation via Masked Generative Transformers
Jan 02, 2023


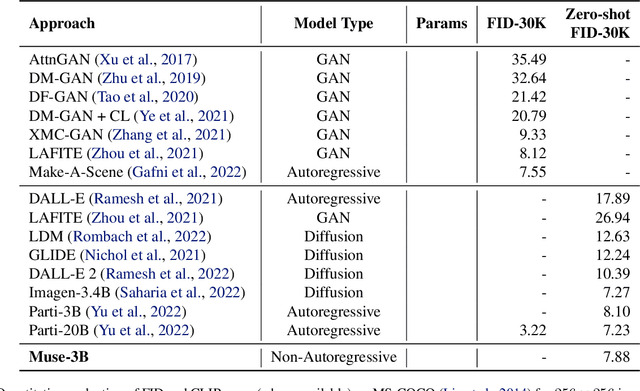
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at https://muse-model.github.io
Challenges and Opportunities in Multi-device Speech Processing
Jun 27, 2022
We review current solutions and technical challenges for automatic speech recognition, keyword spotting, device arbitration, speech enhancement, and source localization in multidevice home environments to provide context for the INTERSPEECH 2022 special session, "Challenges and opportunities for signal processing and machine learning for multiple smart devices". We also identify the datasets needed to support these research areas. Based on the review and our research experience in the multi-device domain, we conclude with an outlook on the future evolution
Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning
Jan 13, 2022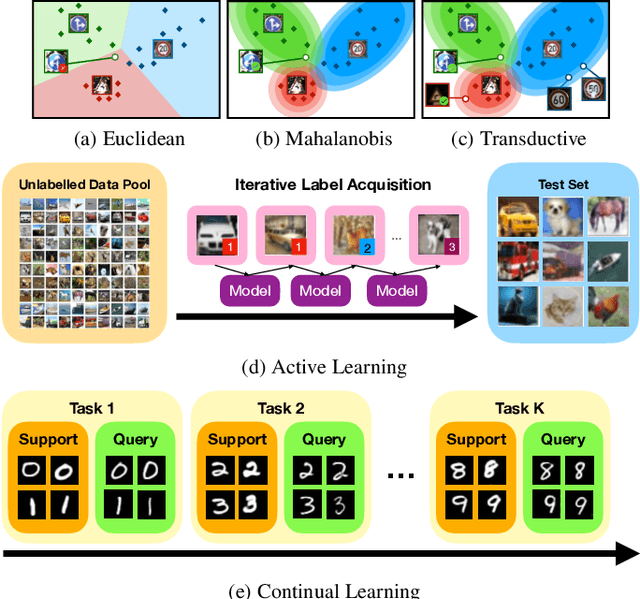
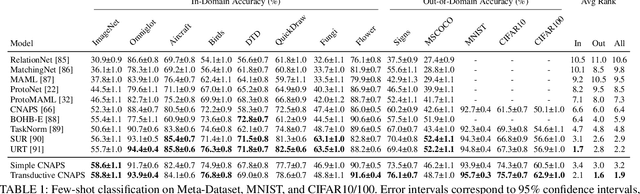
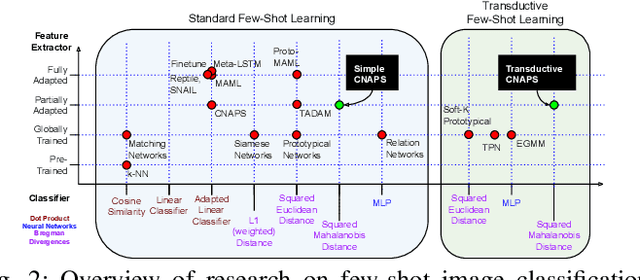
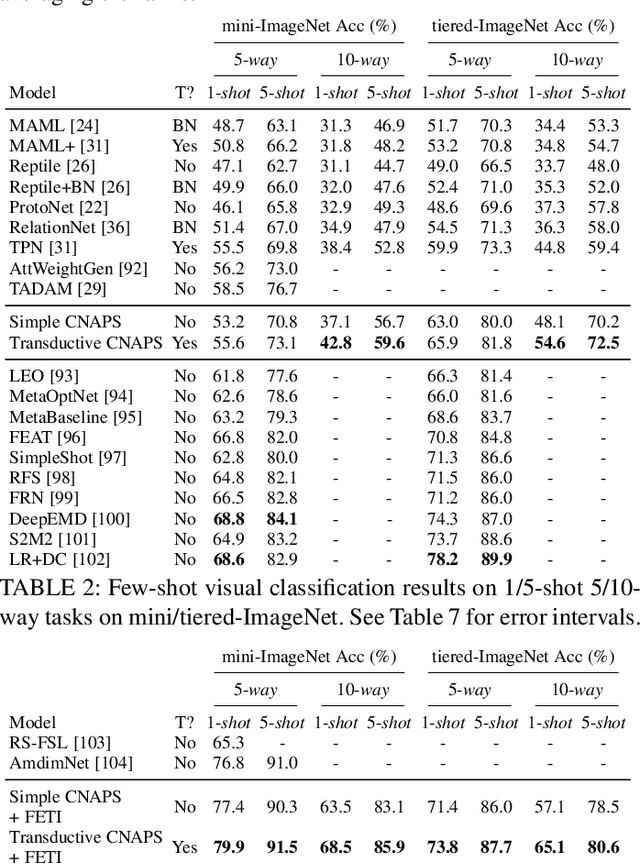
Modern deep learning requires large-scale extensively labelled datasets for training. Few-shot learning aims to alleviate this issue by learning effectively from few labelled examples. In previously proposed few-shot visual classifiers, it is assumed that the feature manifold, where classifier decisions are made, has uncorrelated feature dimensions and uniform feature variance. In this work, we focus on addressing the limitations arising from this assumption by proposing a variance-sensitive class of models that operates in a low-label regime. The first method, Simple CNAPS, employs a hierarchically regularized Mahalanobis-distance based classifier combined with a state of the art neural adaptive feature extractor to achieve strong performance on Meta-Dataset, mini-ImageNet and tiered-ImageNet benchmarks. We further extend this approach to a transductive learning setting, proposing Transductive CNAPS. This transductive method combines a soft k-means parameter refinement procedure with a two-step task encoder to achieve improved test-time classification accuracy using unlabelled data. Transductive CNAPS achieves state of the art performance on Meta-Dataset. Finally, we explore the use of our methods (Simple and Transductive) for "out of the box" continual and active learning. Extensive experiments on large scale benchmarks illustrate robustness and versatility of this, relatively speaking, simple class of models. All trained model checkpoints and corresponding source codes have been made publicly available.
End-to-end Alexa Device Arbitration
Dec 08, 2021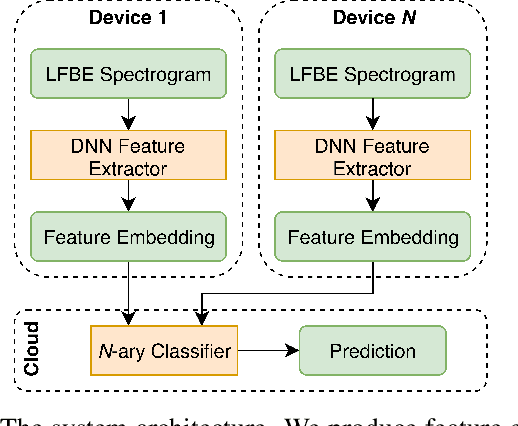
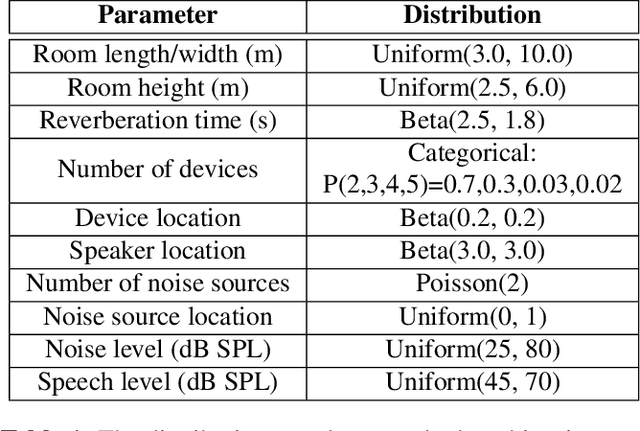
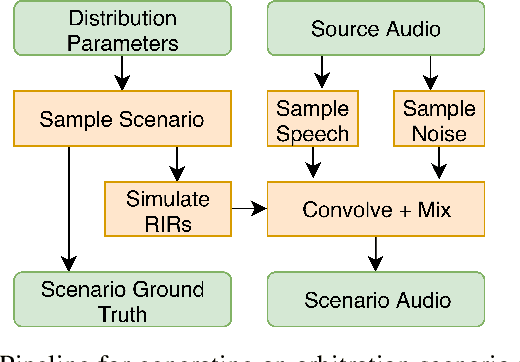
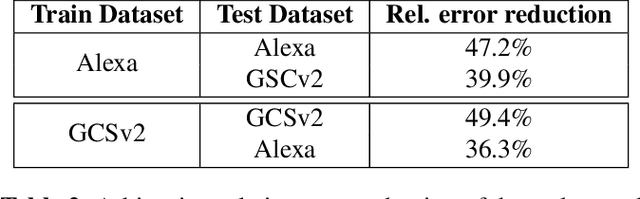
We introduce a variant of the speaker localization problem, which we call device arbitration. In the device arbitration problem, a user utters a keyword that is detected by multiple distributed microphone arrays (smart home devices), and we want to determine which device was closest to the user. Rather than solving the full localization problem, we propose an end-to-end machine learning system. This system learns a feature embedding that is computed independently on each device. The embeddings from each device are then aggregated together to produce the final arbitration decision. We use a large-scale room simulation to generate training and evaluation data, and compare our system against a signal processing baseline.
Improving Few-Shot Visual Classification with Unlabelled Examples
Jun 17, 2020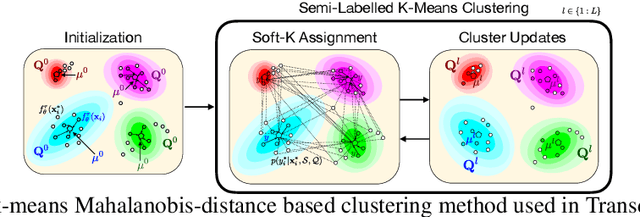
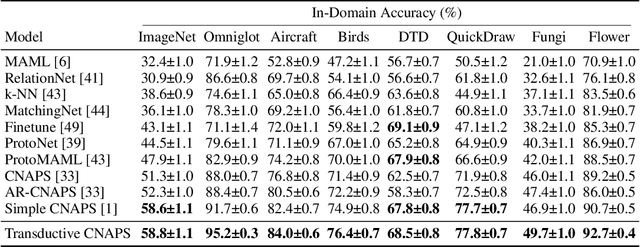
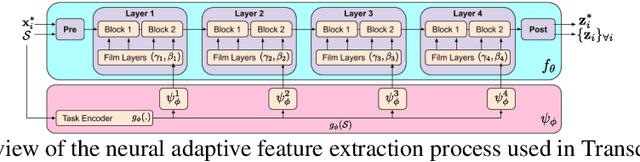
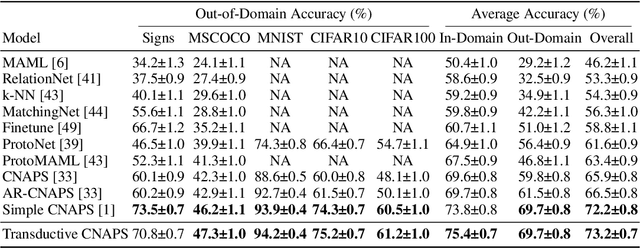
We propose a transductive meta-learning method that uses unlabelled instances to improve few-shot image classification performance. Our approach combines a regularized Mahalanobis-distance-based soft k-means clustering procedure with a state of the art neural adaptive feature extractor to achieve improved test-time classification accuracy using unlabelled data. We evaluate our method on transductive few-shot learning tasks, in which the goal is to jointly predict labels for query (test) examples given a set of support (training) examples. We achieve new state of the art in-domain performance on Meta-Dataset, and improve accuracy on mini- and tiered-ImageNet as compared to other conditional neural adaptive methods that use the same pre-trained feature extractor.
Sparse Gaussian Processes via Parametric Families of Compactly-supported Kernels
Jun 05, 2020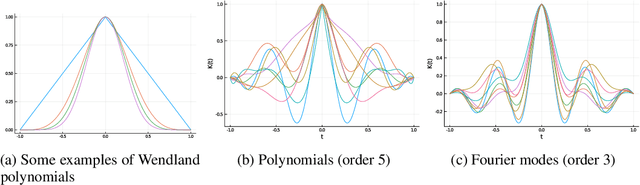
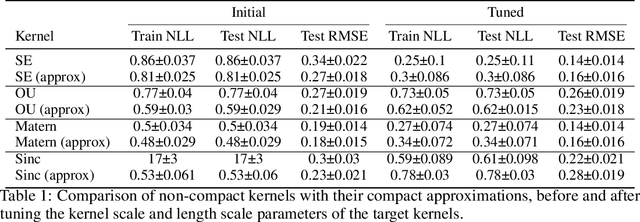
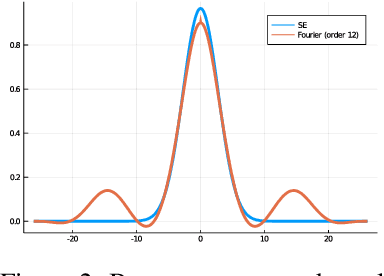
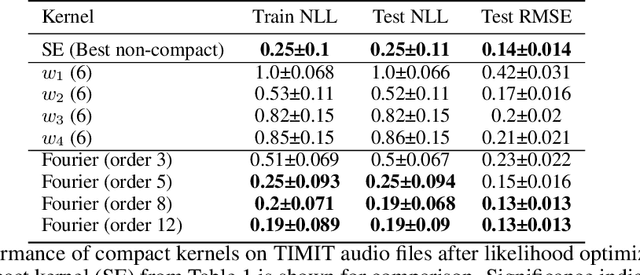
Gaussian processes are powerful models for probabilistic machine learning, but are limited in application by their $O(N^3)$ inference complexity. We propose a method for deriving parametric families of kernel functions with compact spatial support, which yield naturally sparse kernel matrices and enable fast Gaussian process inference via sparse linear algebra. These families generalize known compactly-supported kernel functions, such as the Wendland polynomials. The parameters of this family of kernels can be learned from data using maximum likelihood estimation. Alternatively, we can quickly compute compact approximations of a target kernel using convex optimization. We demonstrate that these approximations incur minimal error over the exact models when modeling data drawn directly from a target GP, and can out-perform the traditional GP kernels on real-world signal reconstruction tasks, while exhibiting sub-quadratic inference complexity.