 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
Aug 13, 2025The new paradigm of test-time scaling has yielded remarkable breakthroughs in Large Language Models (LLMs) (e.g. reasoning models) and in generative vision models, allowing models to allocate additional computation during inference to effectively tackle increasingly complex problems. Despite the improvements of this approach, an important limitation emerges: the substantial increase in computation time makes the process slow and impractical for many applications. Given the success of this paradigm and its growing usage, we seek to preserve its benefits while eschewing the inference overhead. In this work we propose one solution to the critical problem of integrating test-time scaling knowledge into a model during post-training. Specifically, we replace reward guided test-time noise optimization in diffusion models with a Noise Hypernetwork that modulates initial input noise. We propose a theoretically grounded framework for learning this reward-tilted distribution for distilled generators, through a tractable noise-space objective that maintains fidelity to the base model while optimizing for desired characteristics. We show that our approach recovers a substantial portion of the quality gains from explicit test-time optimization at a fraction of the computational cost. Code is available at https://github.com/ExplainableML/HyperNoise
$\texttt{Complex-Edit}$: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark
Apr 17, 2025We introduce $\texttt{Complex-Edit}$, a comprehensive benchmark designed to systematically evaluate instruction-based image editing models across instructions of varying complexity. To develop this benchmark, we harness GPT-4o to automatically collect a diverse set of editing instructions at scale. Our approach follows a well-structured ``Chain-of-Edit'' pipeline: we first generate individual atomic editing tasks independently and then integrate them to form cohesive, complex instructions. Additionally, we introduce a suite of metrics to assess various aspects of editing performance, along with a VLM-based auto-evaluation pipeline that supports large-scale assessments. Our benchmark yields several notable insights: 1) Open-source models significantly underperform relative to proprietary, closed-source models, with the performance gap widening as instruction complexity increases; 2) Increased instructional complexity primarily impairs the models' ability to retain key elements from the input images and to preserve the overall aesthetic quality; 3) Decomposing a complex instruction into a sequence of atomic steps, executed in a step-by-step manner, substantially degrades performance across multiple metrics; 4) A straightforward Best-of-N selection strategy improves results for both direct editing and the step-by-step sequential approach; and 5) We observe a ``curse of synthetic data'': when synthetic data is involved in model training, the edited images from such models tend to appear increasingly synthetic as the complexity of the editing instructions rises -- a phenomenon that intriguingly also manifests in the latest GPT-4o outputs.
D-Feat Occlusions: Diffusion Features for Robustness to Partial Visual Occlusions in Object Recognition
Apr 08, 2025Applications of diffusion models for visual tasks have been quite noteworthy. This paper targets making classification models more robust to occlusions for the task of object recognition by proposing a pipeline that utilizes a frozen diffusion model. Diffusion features have demonstrated success in image generation and image completion while understanding image context. Occlusion can be posed as an image completion problem by deeming the pixels of the occluder to be `missing.' We hypothesize that such features can help hallucinate object visual features behind occluding objects, and hence we propose using them to enable models to become more occlusion robust. We design experiments to include input-based augmentations as well as feature-based augmentations. Input-based augmentations involve finetuning on images where the occluder pixels are inpainted, and feature-based augmentations involve augmenting classification features with intermediate diffusion features. We demonstrate that our proposed use of diffusion-based features results in models that are more robust to partial object occlusions for both Transformers and ConvNets on ImageNet with simulated occlusions. We also propose a dataset that encompasses real-world occlusions and demonstrate that our method is more robust to partial object occlusions.
M-VAR: Decoupled Scale-wise Autoregressive Modeling for High-Quality Image Generation
Nov 15, 2024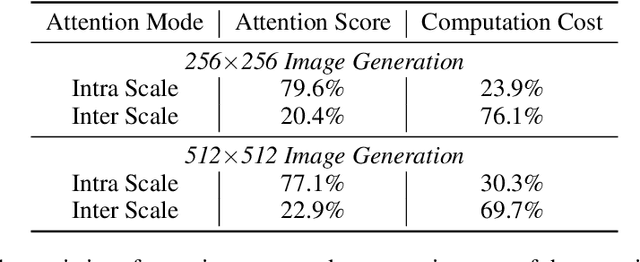



There exists recent work in computer vision, named VAR, that proposes a new autoregressive paradigm for image generation. Diverging from the vanilla next-token prediction, VAR structurally reformulates the image generation into a coarse to fine next-scale prediction. In this paper, we show that this scale-wise autoregressive framework can be effectively decoupled into \textit{intra-scale modeling}, which captures local spatial dependencies within each scale, and \textit{inter-scale modeling}, which models cross-scale relationships progressively from coarse-to-fine scales. This decoupling structure allows to rebuild VAR in a more computationally efficient manner. Specifically, for intra-scale modeling -- crucial for generating high-fidelity images -- we retain the original bidirectional self-attention design to ensure comprehensive modeling; for inter-scale modeling, which semantically connects different scales but is computationally intensive, we apply linear-complexity mechanisms like Mamba to substantially reduce computational overhead. We term this new framework M-VAR. Extensive experiments demonstrate that our method outperforms existing models in both image quality and generation speed. For example, our 1.5B model, with fewer parameters and faster inference speed, outperforms the largest VAR-d30-2B. Moreover, our largest model M-VAR-d32 impressively registers 1.78 FID on ImageNet 256$\times$256 and outperforms the prior-art autoregressive models LlamaGen/VAR by 0.4/0.19 and popular diffusion models LDM/DiT by 1.82/0.49, respectively. Code is avaiable at \url{https://github.com/OliverRensu/MVAR}.
ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
Nov 07, 2024



Recently, breakthroughs in video modeling have allowed for controllable camera trajectories in generated videos. However, these methods cannot be directly applied to user-provided videos that are not generated by a video model. In this paper, we present ReCapture, a method for generating new videos with novel camera trajectories from a single user-provided video. Our method allows us to re-generate the reference video, with all its existing scene motion, from vastly different angles and with cinematic camera motion. Notably, using our method we can also plausibly hallucinate parts of the scene that were not observable in the reference video. Our method works by (1) generating a noisy anchor video with a new camera trajectory using multiview diffusion models or depth-based point cloud rendering and then (2) regenerating the anchor video into a clean and temporally consistent reangled video using our proposed masked video fine-tuning technique.
Unbounded: A Generative Infinite Game of Character Life Simulation
Oct 24, 2024


We introduce the concept of a generative infinite game, a video game that transcends the traditional boundaries of finite, hard-coded systems by using generative models. Inspired by James P. Carse's distinction between finite and infinite games, we leverage recent advances in generative AI to create Unbounded: a game of character life simulation that is fully encapsulated in generative models. Specifically, Unbounded draws inspiration from sandbox life simulations and allows you to interact with your autonomous virtual character in a virtual world by feeding, playing with and guiding it - with open-ended mechanics generated by an LLM, some of which can be emergent. In order to develop Unbounded, we propose technical innovations in both the LLM and visual generation domains. Specifically, we present: (1) a specialized, distilled large language model (LLM) that dynamically generates game mechanics, narratives, and character interactions in real-time, and (2) a new dynamic regional image prompt Adapter (IP-Adapter) for vision models that ensures consistent yet flexible visual generation of a character across multiple environments. We evaluate our system through both qualitative and quantitative analysis, showing significant improvements in character life simulation, user instruction following, narrative coherence, and visual consistency for both characters and the environments compared to traditional related approaches.
Semantic Image Inversion and Editing using Rectified Stochastic Differential Equations
Oct 14, 2024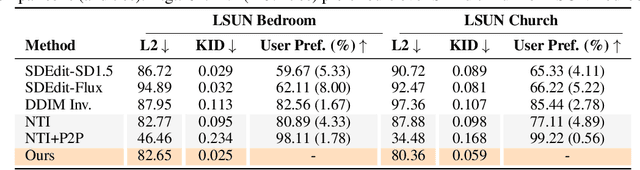
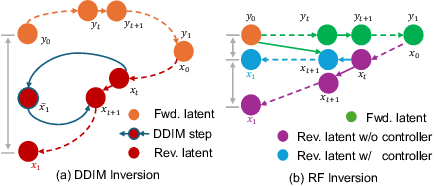
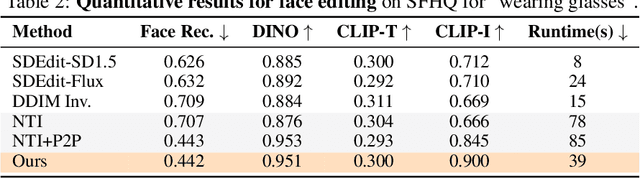

Generative models transform random noise into images; their inversion aims to transform images back to structured noise for recovery and editing. This paper addresses two key tasks: (i) inversion and (ii) editing of a real image using stochastic equivalents of rectified flow models (such as Flux). Although Diffusion Models (DMs) have recently dominated the field of generative modeling for images, their inversion presents faithfulness and editability challenges due to nonlinearities in drift and diffusion. Existing state-of-the-art DM inversion approaches rely on training of additional parameters or test-time optimization of latent variables; both are expensive in practice. Rectified Flows (RFs) offer a promising alternative to diffusion models, yet their inversion has been underexplored. We propose RF inversion using dynamic optimal control derived via a linear quadratic regulator. We prove that the resulting vector field is equivalent to a rectified stochastic differential equation. Additionally, we extend our framework to design a stochastic sampler for Flux. Our inversion method allows for state-of-the-art performance in zero-shot inversion and editing, outperforming prior works in stroke-to-image synthesis and semantic image editing, with large-scale human evaluations confirming user preference.
Magic Insert: Style-Aware Drag-and-Drop
Jul 02, 2024We present Magic Insert, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. This work formalizes the problem of style-aware drag-and-drop and presents a method for tackling it by addressing two sub-problems: style-aware personalization and realistic object insertion in stylized images. For style-aware personalization, our method first fine-tunes a pretrained text-to-image diffusion model using LoRA and learned text tokens on the subject image, and then infuses it with a CLIP representation of the target style. For object insertion, we use Bootstrapped Domain Adaption to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional approaches such as inpainting. Finally, we present a dataset, SubjectPlop, to facilitate evaluation and future progress in this area. Project page: https://magicinsert.github.io/
RB-Modulation: Training-Free Personalization of Diffusion Models using Stochastic Optimal Control
May 27, 2024
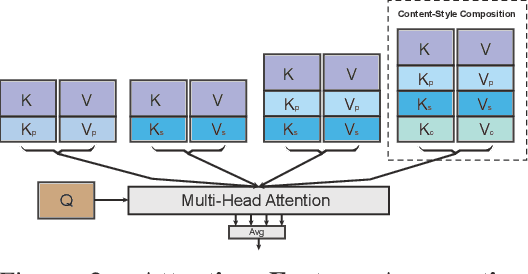
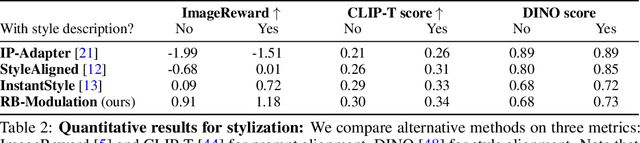
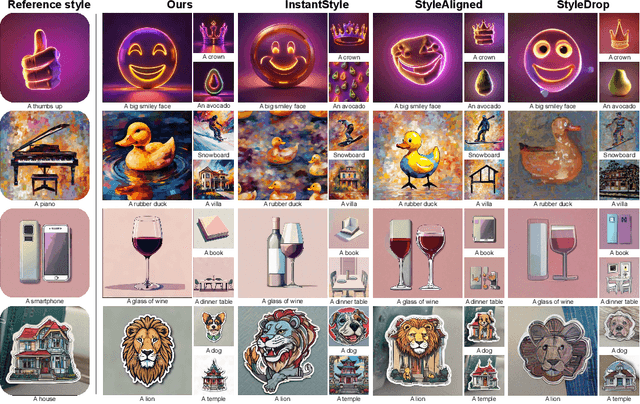
We propose Reference-Based Modulation (RB-Modulation), a new plug-and-play solution for training-free personalization of diffusion models. Existing training-free approaches exhibit difficulties in (a) style extraction from reference images in the absence of additional style or content text descriptions, (b) unwanted content leakage from reference style images, and (c) effective composition of style and content. RB-Modulation is built on a novel stochastic optimal controller where a style descriptor encodes the desired attributes through a terminal cost. The resulting drift not only overcomes the difficulties above, but also ensures high fidelity to the reference style and adheres to the given text prompt. We also introduce a cross-attention-based feature aggregation scheme that allows RB-Modulation to decouple content and style from the reference image. With theoretical justification and empirical evidence, our framework demonstrates precise extraction and control of content and style in a training-free manner. Further, our method allows a seamless composition of content and style, which marks a departure from the dependency on external adapters or ControlNets.
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
Nov 22, 2023



Methods for finetuning generative models for concept-driven personalization generally achieve strong results for subject-driven or style-driven generation. Recently, low-rank adaptations (LoRA) have been proposed as a parameter-efficient way of achieving concept-driven personalization. While recent work explores the combination of separate LoRAs to achieve joint generation of learned styles and subjects, existing techniques do not reliably address the problem; they often compromise either subject fidelity or style fidelity. We propose ZipLoRA, a method to cheaply and effectively merge independently trained style and subject LoRAs in order to achieve generation of any user-provided subject in any user-provided style. Experiments on a wide range of subject and style combinations show that ZipLoRA can generate compelling results with meaningful improvements over baselines in subject and style fidelity while preserving the ability to recontextualize. Project page: https://ziplora.github.io