 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
Nov 07, 2024



Recently, breakthroughs in video modeling have allowed for controllable camera trajectories in generated videos. However, these methods cannot be directly applied to user-provided videos that are not generated by a video model. In this paper, we present ReCapture, a method for generating new videos with novel camera trajectories from a single user-provided video. Our method allows us to re-generate the reference video, with all its existing scene motion, from vastly different angles and with cinematic camera motion. Notably, using our method we can also plausibly hallucinate parts of the scene that were not observable in the reference video. Our method works by (1) generating a noisy anchor video with a new camera trajectory using multiview diffusion models or depth-based point cloud rendering and then (2) regenerating the anchor video into a clean and temporally consistent reangled video using our proposed masked video fine-tuning technique.
Unbounded: A Generative Infinite Game of Character Life Simulation
Oct 24, 2024


We introduce the concept of a generative infinite game, a video game that transcends the traditional boundaries of finite, hard-coded systems by using generative models. Inspired by James P. Carse's distinction between finite and infinite games, we leverage recent advances in generative AI to create Unbounded: a game of character life simulation that is fully encapsulated in generative models. Specifically, Unbounded draws inspiration from sandbox life simulations and allows you to interact with your autonomous virtual character in a virtual world by feeding, playing with and guiding it - with open-ended mechanics generated by an LLM, some of which can be emergent. In order to develop Unbounded, we propose technical innovations in both the LLM and visual generation domains. Specifically, we present: (1) a specialized, distilled large language model (LLM) that dynamically generates game mechanics, narratives, and character interactions in real-time, and (2) a new dynamic regional image prompt Adapter (IP-Adapter) for vision models that ensures consistent yet flexible visual generation of a character across multiple environments. We evaluate our system through both qualitative and quantitative analysis, showing significant improvements in character life simulation, user instruction following, narrative coherence, and visual consistency for both characters and the environments compared to traditional related approaches.
Magic Insert: Style-Aware Drag-and-Drop
Jul 02, 2024We present Magic Insert, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. This work formalizes the problem of style-aware drag-and-drop and presents a method for tackling it by addressing two sub-problems: style-aware personalization and realistic object insertion in stylized images. For style-aware personalization, our method first fine-tunes a pretrained text-to-image diffusion model using LoRA and learned text tokens on the subject image, and then infuses it with a CLIP representation of the target style. For object insertion, we use Bootstrapped Domain Adaption to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional approaches such as inpainting. Finally, we present a dataset, SubjectPlop, to facilitate evaluation and future progress in this area. Project page: https://magicinsert.github.io/
RealFill: Reference-Driven Generation for Authentic Image Completion
Sep 28, 2023Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. See more results on our project page: https://realfill.github.io
Computational Long Exposure Mobile Photography
Aug 02, 2023
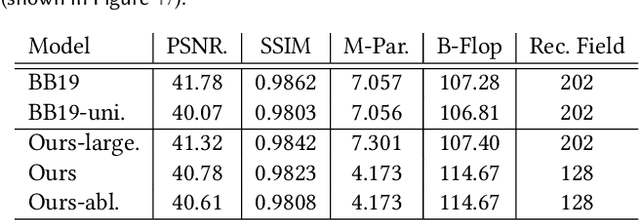


Long exposure photography produces stunning imagery, representing moving elements in a scene with motion-blur. It is generally employed in two modalities, producing either a foreground or a background blur effect. Foreground blur images are traditionally captured on a tripod-mounted camera and portray blurred moving foreground elements, such as silky water or light trails, over a perfectly sharp background landscape. Background blur images, also called panning photography, are captured while the camera is tracking a moving subject, to produce an image of a sharp subject over a background blurred by relative motion. Both techniques are notoriously challenging and require additional equipment and advanced skills. In this paper, we describe a computational burst photography system that operates in a hand-held smartphone camera app, and achieves these effects fully automatically, at the tap of the shutter button. Our approach first detects and segments the salient subject. We track the scene motion over multiple frames and align the images in order to preserve desired sharpness and to produce aesthetically pleasing motion streaks. We capture an under-exposed burst and select the subset of input frames that will produce blur trails of controlled length, regardless of scene or camera motion velocity. We predict inter-frame motion and synthesize motion-blur to fill the temporal gaps between the input frames. Finally, we composite the blurred image with the sharp regular exposure to protect the sharpness of faces or areas of the scene that are barely moving, and produce a final high resolution and high dynamic range (HDR) photograph. Our system democratizes a capability previously reserved to professionals, and makes this creative style accessible to most casual photographers. More information and supplementary material can be found on our project webpage: https://motion-mode.github.io/
* 15 pages, 17 figures
Deep Saliency Prior for Reducing Visual Distraction
Sep 05, 2021
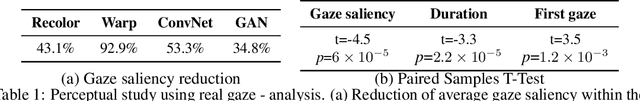


Using only a model that was trained to predict where people look at images, and no additional training data, we can produce a range of powerful editing effects for reducing distraction in images. Given an image and a mask specifying the region to edit, we backpropagate through a state-of-the-art saliency model to parameterize a differentiable editing operator, such that the saliency within the masked region is reduced. We demonstrate several operators, including: a recoloring operator, which learns to apply a color transform that camouflages and blends distractors into their surroundings; a warping operator, which warps less salient image regions to cover distractors, gradually collapsing objects into themselves and effectively removing them (an effect akin to inpainting); a GAN operator, which uses a semantic prior to fully replace image regions with plausible, less salient alternatives. The resulting effects are consistent with cognitive research on the human visual system (e.g., since color mismatch is salient, the recoloring operator learns to harmonize objects' colors with their surrounding to reduce their saliency), and, importantly, are all achieved solely through the guidance of the pretrained saliency model, with no additional supervision. We present results on a variety of natural images and conduct a perceptual study to evaluate and validate the changes in viewers' eye-gaze between the original images and our edited results.
Portrait Shadow Manipulation
May 20, 2020
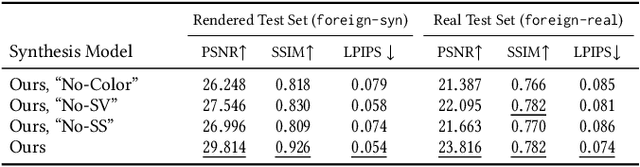
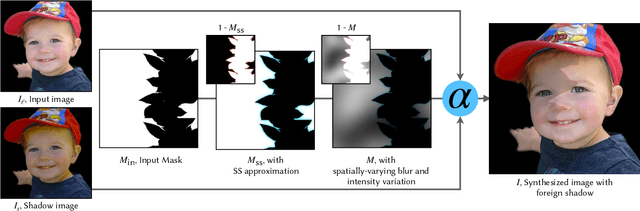
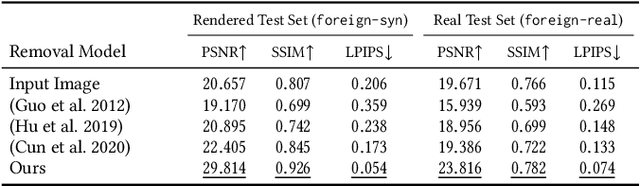
Casually-taken portrait photographs often suffer from unflattering lighting and shadowing because of suboptimal conditions in the environment. Aesthetic qualities such as the position and softness of shadows and the lighting ratio between the bright and dark parts of the face are frequently determined by the constraints of the environment rather than by the photographer. Professionals address this issue by adding light shaping tools such as scrims, bounce cards, and flashes. In this paper, we present a computational approach that gives casual photographers some of this control, thereby allowing poorly-lit portraits to be relit post-capture in a realistic and easily-controllable way. Our approach relies on a pair of neural networks---one to remove foreign shadows cast by external objects, and another to soften facial shadows cast by the features of the subject and to add a synthetic fill light to improve the lighting ratio. To train our first network we construct a dataset of real-world portraits wherein synthetic foreign shadows are rendered onto the face, and we show that our network learns to remove those unwanted shadows. To train our second network we use a dataset of Light Stage scans of human subjects to construct input/output pairs of input images harshly lit by a small light source, and variably softened and fill-lit output images of each face. We propose a way to explicitly encode facial symmetry and show that our dataset and training procedure enable the model to generalize to images taken in the wild. Together, these networks enable the realistic and aesthetically pleasing enhancement of shadows and lights in real-world portrait images
Synthetic Depth-of-Field with a Single-Camera Mobile Phone
Jun 11, 2018

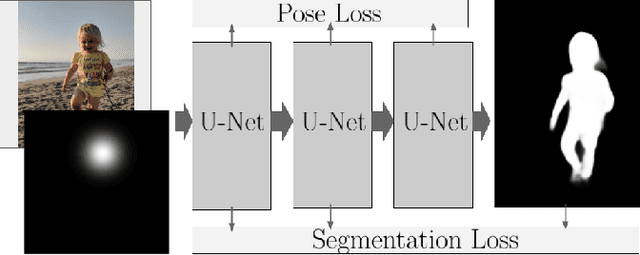
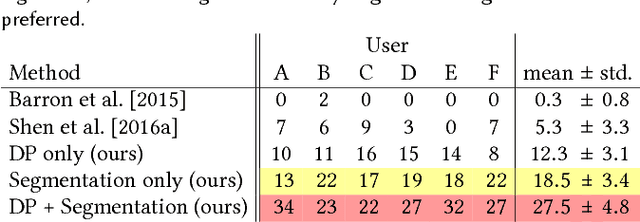
Shallow depth-of-field is commonly used by photographers to isolate a subject from a distracting background. However, standard cell phone cameras cannot produce such images optically, as their short focal lengths and small apertures capture nearly all-in-focus images. We present a system to computationally synthesize shallow depth-of-field images with a single mobile camera and a single button press. If the image is of a person, we use a person segmentation network to separate the person and their accessories from the background. If available, we also use dense dual-pixel auto-focus hardware, effectively a 2-sample light field with an approximately 1 millimeter baseline, to compute a dense depth map. These two signals are combined and used to render a defocused image. Our system can process a 5.4 megapixel image in 4 seconds on a mobile phone, is fully automatic, and is robust enough to be used by non-experts. The modular nature of our system allows it to degrade naturally in the absence of a dual-pixel sensor or a human subject.