 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Lens Blur Fields
Oct 17, 2023Optical blur is an inherent property of any lens system and is challenging to model in modern cameras because of their complex optical elements. To tackle this challenge, we introduce a high-dimensional neural representation of blur$-$$\textit{the lens blur field}$$-$and a practical method for acquiring it. The lens blur field is a multilayer perceptron (MLP) designed to (1) accurately capture variations of the lens 2D point spread function over image plane location, focus setting and, optionally, depth and (2) represent these variations parametrically as a single, sensor-specific function. The representation models the combined effects of defocus, diffraction, aberration, and accounts for sensor features such as pixel color filters and pixel-specific micro-lenses. To learn the real-world blur field of a given device, we formulate a generalized non-blind deconvolution problem that directly optimizes the MLP weights using a small set of focal stacks as the only input. We also provide a first-of-its-kind dataset of 5D blur fields$-$for smartphone cameras, camera bodies equipped with a variety of lenses, etc. Lastly, we show that acquired 5D blur fields are expressive and accurate enough to reveal, for the first time, differences in optical behavior of smartphone devices of the same make and model.
SunStage: Portrait Reconstruction and Relighting using the Sun as a Light Stage
Apr 07, 2022
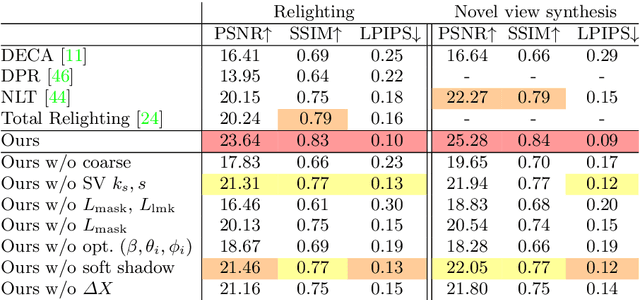
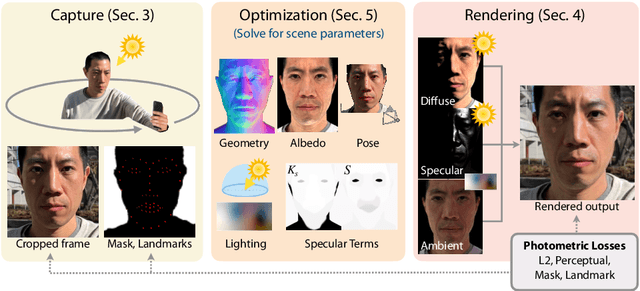

Outdoor portrait photographs are often marred by the harsh shadows cast under direct sunlight. To resolve this, one can use post-capture lighting manipulation techniques, but these methods either require complex hardware (e.g., a light stage) to capture each individual, or rely on image-based priors and thus fail to reconstruct many of the subtle facial details that vary from person to person. In this paper, we present SunStage, a system for accurate, individually-tailored, and lightweight reconstruction of facial geometry and reflectance that can be used for general portrait relighting with cast shadows. Our method only requires the user to capture a selfie video outdoors, rotating in place, and uses the varying angles between the sun and the face as constraints in the joint reconstruction of facial geometry, reflectance properties, and lighting parameters. Aside from relighting, we show that our reconstruction can be used for applications like reflectance editing and view synthesis. Results and interactive demos are available at https://grail.cs.washington.edu/projects/sunstage/.
Learned Dual-View Reflection Removal
Oct 01, 2020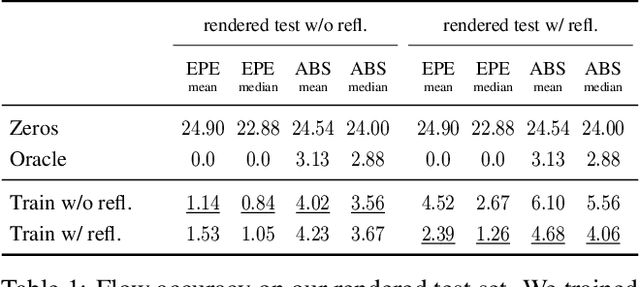

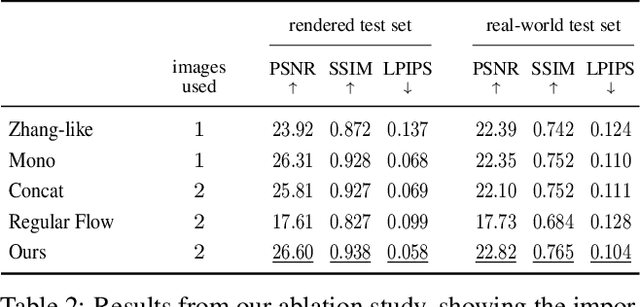

Traditional reflection removal algorithms either use a single image as input, which suffers from intrinsic ambiguities, or use multiple images from a moving camera, which is inconvenient for users. We instead propose a learning-based dereflection algorithm that uses stereo images as input. This is an effective trade-off between the two extremes: the parallax between two views provides cues to remove reflections, and two views are easy to capture due to the adoption of stereo cameras in smartphones. Our model consists of a learning-based reflection-invariant flow model for dual-view registration, and a learned synthesis model for combining aligned image pairs. Because no dataset for dual-view reflection removal exists, we render a synthetic dataset of dual-views with and without reflections for use in training. Our evaluation on an additional real-world dataset of stereo pairs shows that our algorithm outperforms existing single-image and multi-image dereflection approaches.
Portrait Shadow Manipulation
May 20, 2020
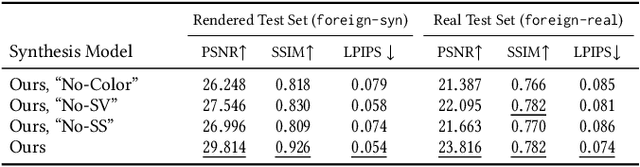
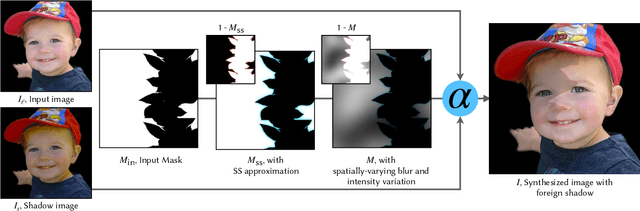
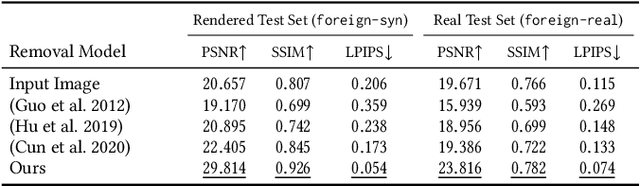
Casually-taken portrait photographs often suffer from unflattering lighting and shadowing because of suboptimal conditions in the environment. Aesthetic qualities such as the position and softness of shadows and the lighting ratio between the bright and dark parts of the face are frequently determined by the constraints of the environment rather than by the photographer. Professionals address this issue by adding light shaping tools such as scrims, bounce cards, and flashes. In this paper, we present a computational approach that gives casual photographers some of this control, thereby allowing poorly-lit portraits to be relit post-capture in a realistic and easily-controllable way. Our approach relies on a pair of neural networks---one to remove foreign shadows cast by external objects, and another to soften facial shadows cast by the features of the subject and to add a synthetic fill light to improve the lighting ratio. To train our first network we construct a dataset of real-world portraits wherein synthetic foreign shadows are rendered onto the face, and we show that our network learns to remove those unwanted shadows. To train our second network we use a dataset of Light Stage scans of human subjects to construct input/output pairs of input images harshly lit by a small light source, and variably softened and fill-lit output images of each face. We propose a way to explicitly encode facial symmetry and show that our dataset and training procedure enable the model to generalize to images taken in the wild. Together, these networks enable the realistic and aesthetically pleasing enhancement of shadows and lights in real-world portrait images
Zoom To Learn, Learn To Zoom
May 13, 2019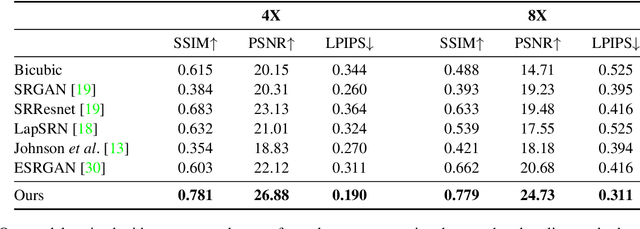
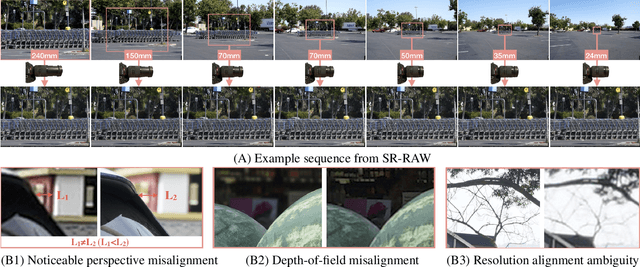


This paper shows that when applying machine learning to digital zoom for photography, it is beneficial to use real, RAW sensor data for training. Existing learning-based super-resolution methods do not use real sensor data, instead operating on RGB images. In practice, these approaches result in loss of detail and accuracy in their digitally zoomed output when zooming in on distant image regions. We also show that synthesizing sensor data by resampling high-resolution RGB images is an oversimplified approximation of real sensor data and noise, resulting in worse image quality. The key barrier to using real sensor data for training is that ground truth high-resolution imagery is missing. We show how to obtain the ground-truth data with optically zoomed images and contribute a dataset, SR-RAW, for real-world computational zoom. We use SR-RAW to train a deep network with a novel contextual bilateral loss (CoBi) that delivers critical robustness to mild misalignment in input-output image pairs. The trained network achieves state-of-the-art performance in 4X and 8X computational zoom.