 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAeroHaptix: A Wearable Vibrotactile Feedback System for Enhancing Collision Avoidance in UAV Teleoperation
Jul 16, 2024Haptic feedback enhances collision avoidance by providing directional obstacle information to operators in unmanned aerial vehicle (UAV) teleoperation. However, such feedback is often rendered via haptic joysticks, which are unfamiliar to UAV operators and limited to single-directional force feedback. Additionally, the direct coupling of the input device and the feedback method diminishes the operators' control authority and causes oscillatory movements. To overcome these limitations, we propose AeroHaptix, a wearable haptic feedback system that uses high-resolution vibrations to communicate multiple obstacle directions simultaneously. The vibrotactile actuators' layout was optimized based on a perceptual study to eliminate perceptual biases and achieve uniform spatial coverage. A novel rendering algorithm, MultiCBF, was adapted from control barrier functions to support multi-directional feedback. System evaluation showed that AeroHaptix effectively reduced collisions in complex environment, and operators reported significantly lower physical workload, improved situational awareness, and increased control authority.
SkyScript: A Large and Semantically Diverse Vision-Language Dataset for Remote Sensing
Dec 20, 2023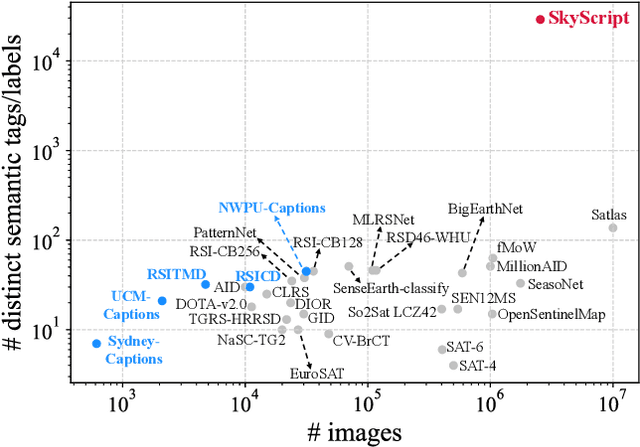
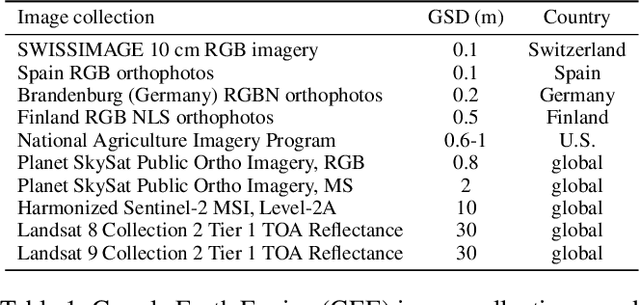

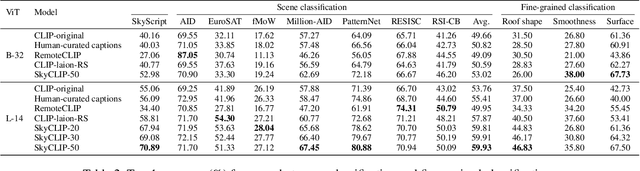
Remote sensing imagery, despite its broad applications in helping achieve Sustainable Development Goals and tackle climate change, has not yet benefited from the recent advancements of versatile, task-agnostic vision language models (VLMs). A key reason is that the large-scale, semantically diverse image-text dataset required for developing VLMs is still absent for remote sensing images. Unlike natural images, remote sensing images and their associated text descriptions cannot be efficiently collected from the public Internet at scale. In this work, we bridge this gap by using geo-coordinates to automatically connect open, unlabeled remote sensing images with rich semantics covered in OpenStreetMap, and thus construct SkyScript, a comprehensive vision-language dataset for remote sensing images, comprising 2.6 million image-text pairs covering 29K distinct semantic tags. With continual pre-training on this dataset, we obtain a VLM that surpasses baseline models with a 6.2% average accuracy gain in zero-shot scene classification across seven benchmark datasets. It also demonstrates the ability of zero-shot transfer for fine-grained object attribute classification and cross-modal retrieval. We hope this dataset can support the advancement of VLMs for various multi-modal tasks in remote sensing, such as open-vocabulary classification, retrieval, captioning, and text-to-image synthesis.
Learning Lens Blur Fields
Oct 17, 2023Optical blur is an inherent property of any lens system and is challenging to model in modern cameras because of their complex optical elements. To tackle this challenge, we introduce a high-dimensional neural representation of blur$-$$\textit{the lens blur field}$$-$and a practical method for acquiring it. The lens blur field is a multilayer perceptron (MLP) designed to (1) accurately capture variations of the lens 2D point spread function over image plane location, focus setting and, optionally, depth and (2) represent these variations parametrically as a single, sensor-specific function. The representation models the combined effects of defocus, diffraction, aberration, and accounts for sensor features such as pixel color filters and pixel-specific micro-lenses. To learn the real-world blur field of a given device, we formulate a generalized non-blind deconvolution problem that directly optimizes the MLP weights using a small set of focal stacks as the only input. We also provide a first-of-its-kind dataset of 5D blur fields$-$for smartphone cameras, camera bodies equipped with a variety of lenses, etc. Lastly, we show that acquired 5D blur fields are expressive and accurate enough to reveal, for the first time, differences in optical behavior of smartphone devices of the same make and model.
Detecting Neighborhood Gentrification at Scale via Street-level Visual Data
Jan 04, 2023



Neighborhood gentrification plays a significant role in shaping the social and economic well-being of both individuals and communities at large. While some efforts have been made to detect gentrification in cities, existing approaches rely mainly on estimated measures from survey data, require substantial work of human labeling, and are limited in characterizing the neighborhood as a whole. We propose a novel approach to detecting neighborhood gentrification at a large-scale based on the physical appearance of neighborhoods by incorporating historical street-level visual data. We show the effectiveness of the proposed method by comparing results from our approach with gentrification measures from previous literature and case studies. Our approach has the potential to supplement existing indicators of gentrification and become a valid resource for urban researchers and policy makers.
AugNet: End-to-End Unsupervised Visual Representation Learning with Image Augmentation
Jun 11, 2021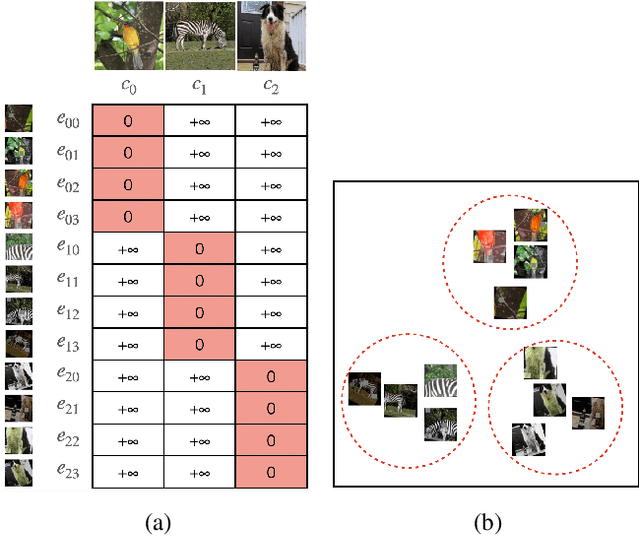

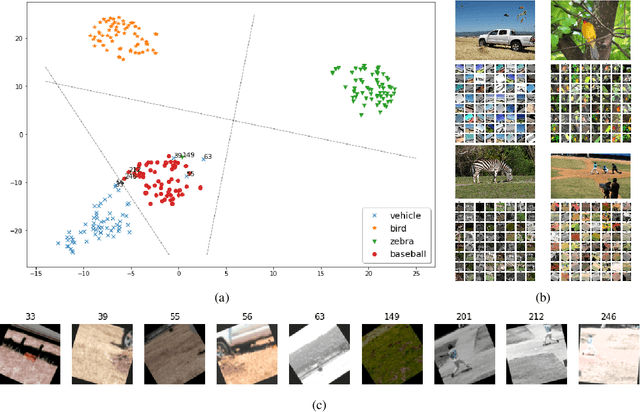

Most of the achievements in artificial intelligence so far were accomplished by supervised learning which requires numerous annotated training data and thus costs innumerable manpower for labeling. Unsupervised learning is one of the effective solutions to overcome such difficulties. In our work, we propose AugNet, a new deep learning training paradigm to learn image features from a collection of unlabeled pictures. We develop a method to construct the similarities between pictures as distance metrics in the embedding space by leveraging the inter-correlation between augmented versions of samples. Our experiments demonstrate that the method is able to represent the image in low dimensional space and performs competitively in downstream tasks such as image classification and image similarity comparison. Specifically, we achieved over 60% and 27% accuracy on the STL10 and CIFAR100 datasets with unsupervised clustering, respectively. Moreover, unlike many deep-learning-based image retrieval algorithms, our approach does not require access to external annotated datasets to train the feature extractor, but still shows comparable or even better feature representation ability and easy-to-use characteristics. In our evaluations, the method outperforms all the state-of-the-art image retrieval algorithms on some out-of-domain image datasets. The code for the model implementation is available at https://github.com/chenmingxiang110/AugNet.
Learning Neighborhood Representation from Multi-Modal Multi-Graph: Image, Text, Mobility Graph and Beyond
May 06, 2021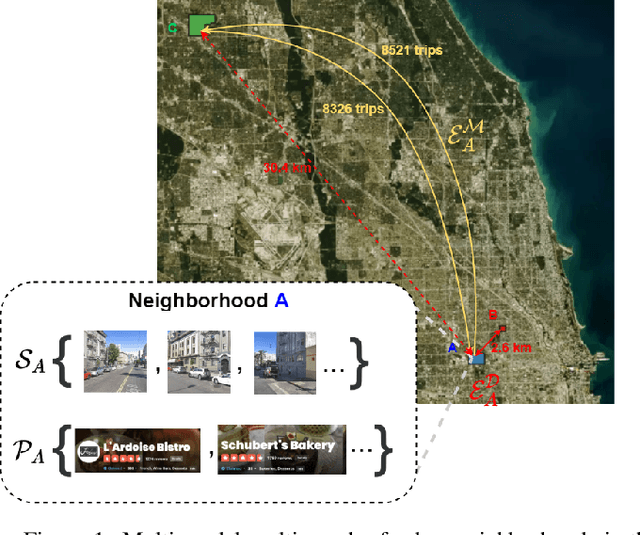

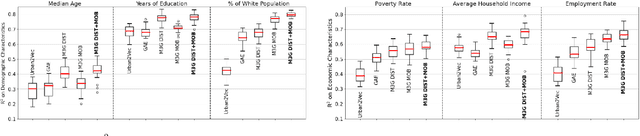

Recent urbanization has coincided with the enrichment of geotagged data, such as street view and point-of-interest (POI). Region embedding enhanced by the richer data modalities has enabled researchers and city administrators to understand the built environment, socioeconomics, and the dynamics of cities better. While some efforts have been made to simultaneously use multi-modal inputs, existing methods can be improved by incorporating different measures of 'proximity' in the same embedding space - leveraging not only the data that characterizes the regions (e.g., street view, local businesses pattern) but also those that depict the relationship between regions (e.g., trips, road network). To this end, we propose a novel approach to integrate multi-modal geotagged inputs as either node or edge features of a multi-graph based on their relations with the neighborhood region (e.g., tiles, census block, ZIP code region, etc.). We then learn the neighborhood representation based on a contrastive-sampling scheme from the multi-graph. Specifically, we use street view images and POI features to characterize neighborhoods (nodes) and use human mobility to characterize the relationship between neighborhoods (directed edges). We show the effectiveness of the proposed methods with quantitative downstream tasks as well as qualitative analysis of the embedding space: The embedding we trained outperforms the ones using only unimodal data as regional inputs.
Image Generation With Neural Cellular Automatas
Oct 10, 2020


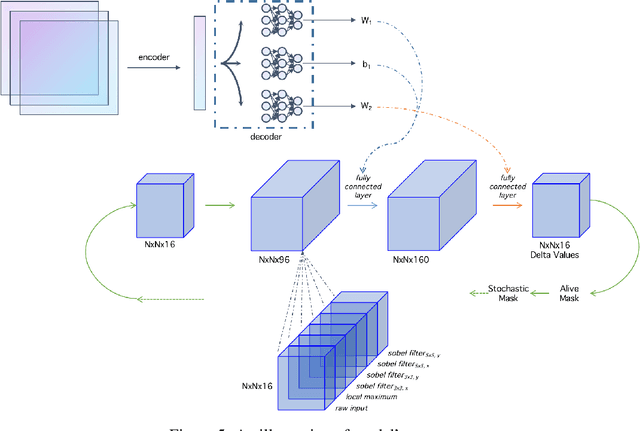
In this paper, we propose a novel approach to generate images (or other artworks) by using neural cellular automatas (NCAs). Rather than training NCAs based on single images one by one, we combined the idea with variational autoencoders (VAEs), and hence explored some applications, such as image restoration and style fusion. The code for model implementation is available online.
Predicting Geographic Information with Neural Cellular Automata
Sep 20, 2020

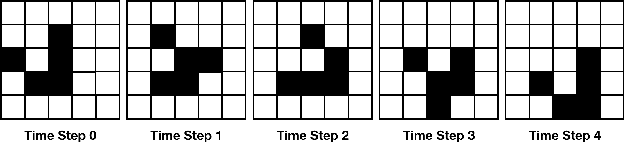

This paper presents a novel framework using neural cellular automata (NCA) to regenerate and predict geographic information. The model extends the idea of using NCA to generate/regenerate a specific image by training the model with various geographic data, and thus, taking the traffic condition map as an example, the model is able to predict traffic conditions by giving certain induction information. Our research verified the analogy between NCA and gene in biology, while the innovation of the model significantly widens the boundary of possible applications based on NCAs. From our experimental results, the model shows great potentials in its usability and versatility which are not available in previous studies. The code for model implementation is available at https://redacted.
Urban2Vec: Incorporating Street View Imagery and POIs for Multi-Modal Urban Neighborhood Embedding
Jan 29, 2020


Understanding intrinsic patterns and predicting spatiotemporal characteristics of cities require a comprehensive representation of urban neighborhoods. Existing works relied on either inter- or intra-region connectivities to generate neighborhood representations but failed to fully utilize the informative yet heterogeneous data within neighborhoods. In this work, we propose Urban2Vec, an unsupervised multi-modal framework which incorporates both street view imagery and point-of-interest (POI) data to learn neighborhood embeddings. Specifically, we use a convolutional neural network to extract visual features from street view images while preserving geospatial similarity. Furthermore, we model each POI as a bag-of-words containing its category, rating, and review information. Analog to document embedding in natural language processing, we establish the semantic similarity between neighborhood ("document") and the words from its surrounding POIs in the vector space. By jointly encoding visual, textual, and geospatial information into the neighborhood representation, Urban2Vec can achieve performances better than baseline models and comparable to fully-supervised methods in downstream prediction tasks. Extensive experiments on three U.S. metropolitan areas also demonstrate the model interpretability, generalization capability, and its value in neighborhood similarity analysis.
Machine Learning for AC Optimal Power Flow
Oct 19, 2019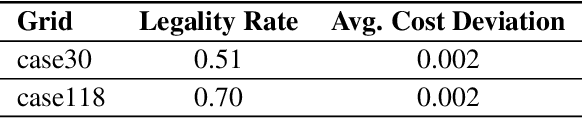

We explore machine learning methods for AC Optimal Powerflow (ACOPF) - the task of optimizing power generation in a transmission network according while respecting physical and engineering constraints. We present two formulations of ACOPF as a machine learning problem: 1) an end-to-end prediction task where we directly predict the optimal generator settings, and 2) a constraint prediction task where we predict the set of active constraints in the optimal solution. We validate these approaches on two benchmark grids.