 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCityPulse: Fine-Grained Assessment of Urban Change with Street View Time Series
Jan 03, 2024Urban transformations have profound societal impact on both individuals and communities at large. Accurately assessing these shifts is essential for understanding their underlying causes and ensuring sustainable urban planning. Traditional measurements often encounter constraints in spatial and temporal granularity, failing to capture real-time physical changes. While street view imagery, capturing the heartbeat of urban spaces from a pedestrian point of view, can add as a high-definition, up-to-date, and on-the-ground visual proxy of urban change. We curate the largest street view time series dataset to date, and propose an end-to-end change detection model to effectively capture physical alterations in the built environment at scale. We demonstrate the effectiveness of our proposed method by benchmark comparisons with previous literature and implementing it at the city-wide level. Our approach has the potential to supplement existing dataset and serve as a fine-grained and accurate assessment of urban change.
SkyScript: A Large and Semantically Diverse Vision-Language Dataset for Remote Sensing
Dec 20, 2023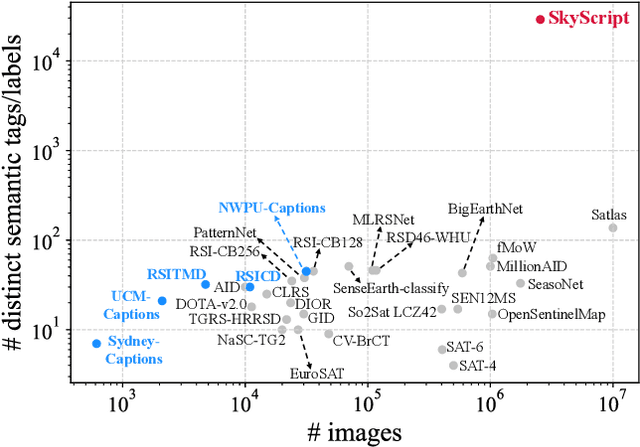
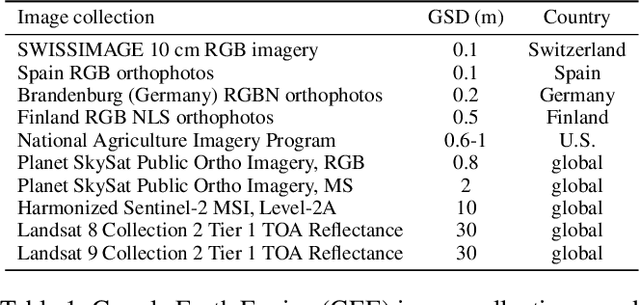

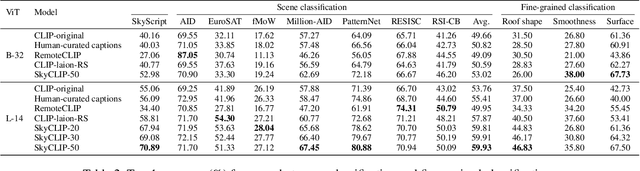
Remote sensing imagery, despite its broad applications in helping achieve Sustainable Development Goals and tackle climate change, has not yet benefited from the recent advancements of versatile, task-agnostic vision language models (VLMs). A key reason is that the large-scale, semantically diverse image-text dataset required for developing VLMs is still absent for remote sensing images. Unlike natural images, remote sensing images and their associated text descriptions cannot be efficiently collected from the public Internet at scale. In this work, we bridge this gap by using geo-coordinates to automatically connect open, unlabeled remote sensing images with rich semantics covered in OpenStreetMap, and thus construct SkyScript, a comprehensive vision-language dataset for remote sensing images, comprising 2.6 million image-text pairs covering 29K distinct semantic tags. With continual pre-training on this dataset, we obtain a VLM that surpasses baseline models with a 6.2% average accuracy gain in zero-shot scene classification across seven benchmark datasets. It also demonstrates the ability of zero-shot transfer for fine-grained object attribute classification and cross-modal retrieval. We hope this dataset can support the advancement of VLMs for various multi-modal tasks in remote sensing, such as open-vocabulary classification, retrieval, captioning, and text-to-image synthesis.
Detecting Neighborhood Gentrification at Scale via Street-level Visual Data
Jan 04, 2023



Neighborhood gentrification plays a significant role in shaping the social and economic well-being of both individuals and communities at large. While some efforts have been made to detect gentrification in cities, existing approaches rely mainly on estimated measures from survey data, require substantial work of human labeling, and are limited in characterizing the neighborhood as a whole. We propose a novel approach to detecting neighborhood gentrification at a large-scale based on the physical appearance of neighborhoods by incorporating historical street-level visual data. We show the effectiveness of the proposed method by comparing results from our approach with gentrification measures from previous literature and case studies. Our approach has the potential to supplement existing indicators of gentrification and become a valid resource for urban researchers and policy makers.
Learning Neighborhood Representation from Multi-Modal Multi-Graph: Image, Text, Mobility Graph and Beyond
May 06, 2021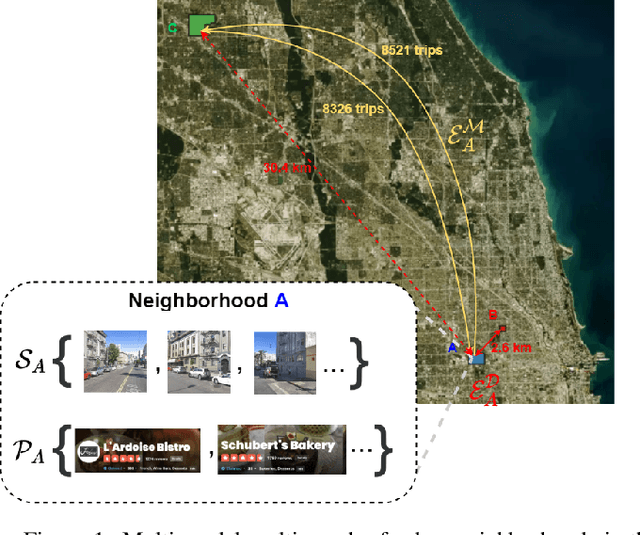

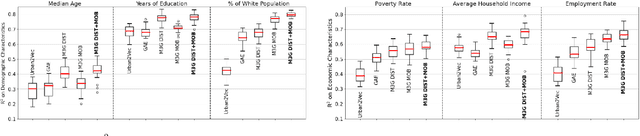

Recent urbanization has coincided with the enrichment of geotagged data, such as street view and point-of-interest (POI). Region embedding enhanced by the richer data modalities has enabled researchers and city administrators to understand the built environment, socioeconomics, and the dynamics of cities better. While some efforts have been made to simultaneously use multi-modal inputs, existing methods can be improved by incorporating different measures of 'proximity' in the same embedding space - leveraging not only the data that characterizes the regions (e.g., street view, local businesses pattern) but also those that depict the relationship between regions (e.g., trips, road network). To this end, we propose a novel approach to integrate multi-modal geotagged inputs as either node or edge features of a multi-graph based on their relations with the neighborhood region (e.g., tiles, census block, ZIP code region, etc.). We then learn the neighborhood representation based on a contrastive-sampling scheme from the multi-graph. Specifically, we use street view images and POI features to characterize neighborhoods (nodes) and use human mobility to characterize the relationship between neighborhoods (directed edges). We show the effectiveness of the proposed methods with quantitative downstream tasks as well as qualitative analysis of the embedding space: The embedding we trained outperforms the ones using only unimodal data as regional inputs.