 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Long Exposure Mobile Photography
Aug 02, 2023


Long exposure photography produces stunning imagery, representing moving elements in a scene with motion-blur. It is generally employed in two modalities, producing either a foreground or a background blur effect. Foreground blur images are traditionally captured on a tripod-mounted camera and portray blurred moving foreground elements, such as silky water or light trails, over a perfectly sharp background landscape. Background blur images, also called panning photography, are captured while the camera is tracking a moving subject, to produce an image of a sharp subject over a background blurred by relative motion. Both techniques are notoriously challenging and require additional equipment and advanced skills. In this paper, we describe a computational burst photography system that operates in a hand-held smartphone camera app, and achieves these effects fully automatically, at the tap of the shutter button. Our approach first detects and segments the salient subject. We track the scene motion over multiple frames and align the images in order to preserve desired sharpness and to produce aesthetically pleasing motion streaks. We capture an under-exposed burst and select the subset of input frames that will produce blur trails of controlled length, regardless of scene or camera motion velocity. We predict inter-frame motion and synthesize motion-blur to fill the temporal gaps between the input frames. Finally, we composite the blurred image with the sharp regular exposure to protect the sharpness of faces or areas of the scene that are barely moving, and produce a final high resolution and high dynamic range (HDR) photograph. Our system democratizes a capability previously reserved to professionals, and makes this creative style accessible to most casual photographers. More information and supplementary material can be found on our project webpage: https://motion-mode.github.io/
* 15 pages, 17 figures
GeoGAN: A Conditional GAN with Reconstruction and Style Loss to Generate Standard Layer of Maps from Satellite Images
Feb 14, 2019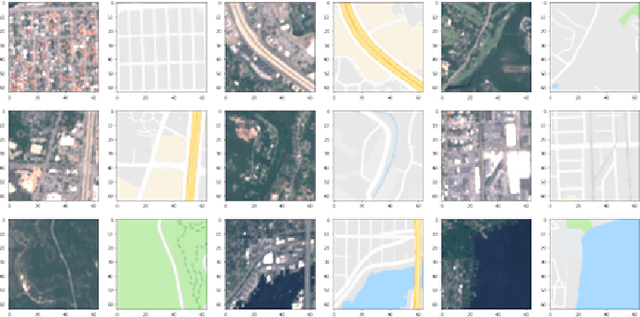
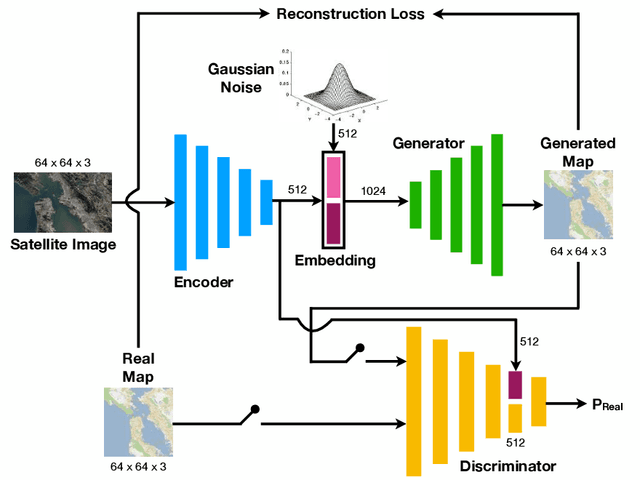
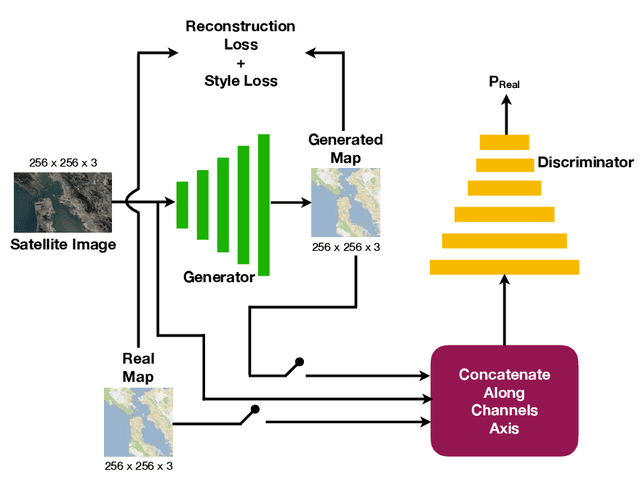
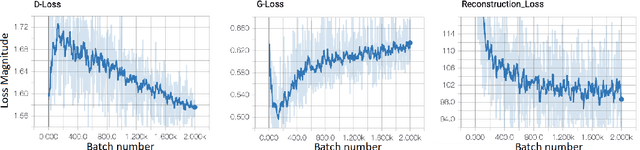
Automatically generating maps from satellite images is an important task. There is a body of literature which tries to address this challenge. We created a more expansive survey of the task by experimenting with different models and adding new loss functions to improve results. We created a database of pairs of satellite images and the corresponding map of the area. Our model translates the satellite image to the corresponding standard layer map image using three main model architectures: (i) a conditional Generative Adversarial Network (GAN) which compresses the images down to a learned embedding, (ii) a generator which is trained as a normalizing flow (RealNVP) model, and (iii) a conditional GAN where the generator translates via a series of convolutions to the standard layer of a map and the discriminator input is the concatenation of the real/generated map and the satellite image. Model (iii) was by far the most promising of three models. To improve the results we also added a reconstruction loss and style transfer loss in addition to the GAN losses. The third model architecture produced the best quality of sampled images. In contrast to the other generative model where evaluation of the model is a challenging problem. since we have access to the real map for a given satellite image, we are able to assign a quantitative metric to the quality of the generated images in addition to inspecting them visually. While we are continuing to work on increasing the accuracy of the model, one challenge has been the coarse resolution of the data which upper-bounds the quality of the results of our model. Nevertheless, as will be seen in the results, the generated map is more accurate in the features it produces since the generator architecture demands a pixel-wise image translation/pixel-wise coloring. A video presentation summarizing this paper is available at: https://youtu.be/Ur0flOX-Ji0