 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Autoregressive Visual Generation and Understanding with Continuous Tokens
Mar 17, 2025We present UniFluid, a unified autoregressive framework for joint visual generation and understanding leveraging continuous visual tokens. Our unified autoregressive architecture processes multimodal image and text inputs, generating discrete tokens for text and continuous tokens for image. We find though there is an inherent trade-off between the image generation and understanding task, a carefully tuned training recipe enables them to improve each other. By selecting an appropriate loss balance weight, the unified model achieves results comparable to or exceeding those of single-task baselines on both tasks. Furthermore, we demonstrate that employing stronger pre-trained LLMs and random-order generation during training is important to achieve high-fidelity image generation within this unified framework. Built upon the Gemma model series, UniFluid exhibits competitive performance across both image generation and understanding, demonstrating strong transferability to various downstream tasks, including image editing for generation, as well as visual captioning and question answering for understanding.
CamCtrl3D: Single-Image Scene Exploration with Precise 3D Camera Control
Jan 10, 2025



We propose a method for generating fly-through videos of a scene, from a single image and a given camera trajectory. We build upon an image-to-video latent diffusion model. We condition its UNet denoiser on the camera trajectory, using four techniques. (1) We condition the UNet's temporal blocks on raw camera extrinsics, similar to MotionCtrl. (2) We use images containing camera rays and directions, similar to CameraCtrl. (3) We reproject the initial image to subsequent frames and use the resulting video as a condition. (4) We use 2D<=>3D transformers to introduce a global 3D representation, which implicitly conditions on the camera poses. We combine all conditions in a ContolNet-style architecture. We then propose a metric that evaluates overall video quality and the ability to preserve details with view changes, which we use to analyze the trade-offs of individual and combined conditions. Finally, we identify an optimal combination of conditions. We calibrate camera positions in our datasets for scale consistency across scenes, and we train our scene exploration model, CamCtrl3D, demonstrating state-of-theart results.
Motion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
Unbounded: A Generative Infinite Game of Character Life Simulation
Oct 24, 2024


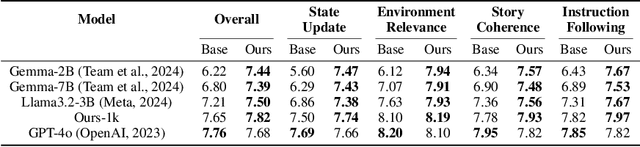
We introduce the concept of a generative infinite game, a video game that transcends the traditional boundaries of finite, hard-coded systems by using generative models. Inspired by James P. Carse's distinction between finite and infinite games, we leverage recent advances in generative AI to create Unbounded: a game of character life simulation that is fully encapsulated in generative models. Specifically, Unbounded draws inspiration from sandbox life simulations and allows you to interact with your autonomous virtual character in a virtual world by feeding, playing with and guiding it - with open-ended mechanics generated by an LLM, some of which can be emergent. In order to develop Unbounded, we propose technical innovations in both the LLM and visual generation domains. Specifically, we present: (1) a specialized, distilled large language model (LLM) that dynamically generates game mechanics, narratives, and character interactions in real-time, and (2) a new dynamic regional image prompt Adapter (IP-Adapter) for vision models that ensures consistent yet flexible visual generation of a character across multiple environments. We evaluate our system through both qualitative and quantitative analysis, showing significant improvements in character life simulation, user instruction following, narrative coherence, and visual consistency for both characters and the environments compared to traditional related approaches.
Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens
Oct 17, 2024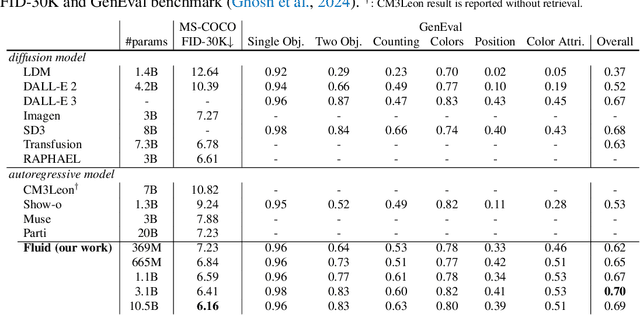
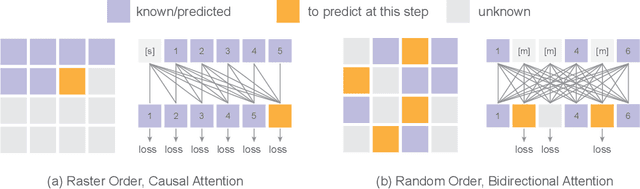
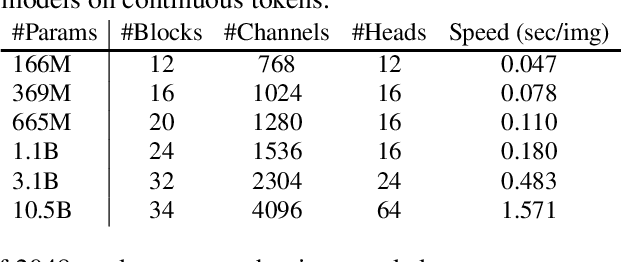
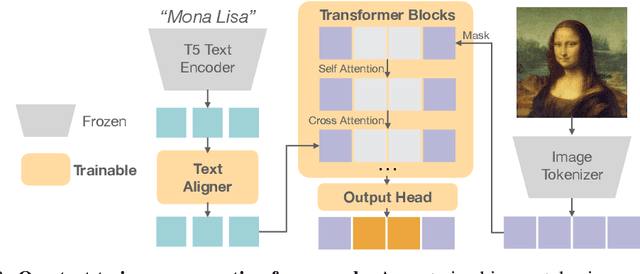
Scaling up autoregressive models in vision has not proven as beneficial as in large language models. In this work, we investigate this scaling problem in the context of text-to-image generation, focusing on two critical factors: whether models use discrete or continuous tokens, and whether tokens are generated in a random or fixed raster order using BERT- or GPT-like transformer architectures. Our empirical results show that, while all models scale effectively in terms of validation loss, their evaluation performance -- measured by FID, GenEval score, and visual quality -- follows different trends. Models based on continuous tokens achieve significantly better visual quality than those using discrete tokens. Furthermore, the generation order and attention mechanisms significantly affect the GenEval score: random-order models achieve notably better GenEval scores compared to raster-order models. Inspired by these findings, we train Fluid, a random-order autoregressive model on continuous tokens. Fluid 10.5B model achieves a new state-of-the-art zero-shot FID of 6.16 on MS-COCO 30K, and 0.69 overall score on the GenEval benchmark. We hope our findings and results will encourage future efforts to further bridge the scaling gap between vision and language models.
VidPanos: Generative Panoramic Videos from Casual Panning Videos
Oct 17, 2024
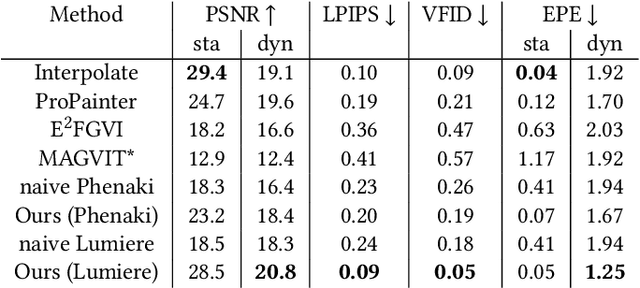
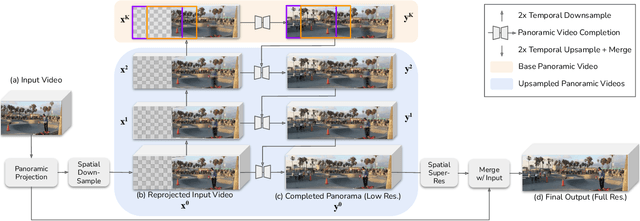
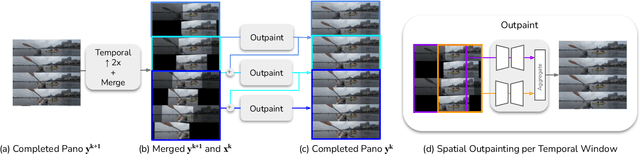
Panoramic image stitching provides a unified, wide-angle view of a scene that extends beyond the camera's field of view. Stitching frames of a panning video into a panoramic photograph is a well-understood problem for stationary scenes, but when objects are moving, a still panorama cannot capture the scene. We present a method for synthesizing a panoramic video from a casually-captured panning video, as if the original video were captured with a wide-angle camera. We pose panorama synthesis as a space-time outpainting problem, where we aim to create a full panoramic video of the same length as the input video. Consistent completion of the space-time volume requires a powerful, realistic prior over video content and motion, for which we adapt generative video models. Existing generative models do not, however, immediately extend to panorama completion, as we show. We instead apply video generation as a component of our panorama synthesis system, and demonstrate how to exploit the strengths of the models while minimizing their limitations. Our system can create video panoramas for a range of in-the-wild scenes including people, vehicles, and flowing water, as well as stationary background features.
High-Resolution Frame Interpolation with Patch-based Cascaded Diffusion
Oct 15, 2024Despite the recent progress, existing frame interpolation methods still struggle with processing extremely high resolution input and handling challenging cases such as repetitive textures, thin objects, and large motion. To address these issues, we introduce a patch-based cascaded pixel diffusion model for frame interpolation, HiFI, that excels in these scenarios while achieving competitive performance on standard benchmarks. Cascades, which generate a series of images from low- to high-resolution, can help significantly with large or complex motion that require both global context for a coarse solution and detailed context for high resolution output. However, contrary to prior work on cascaded diffusion models which perform diffusion on increasingly large resolutions, we use a single model that always performs diffusion at the same resolution and upsamples by processing patches of the inputs and the prior solution. We show that this technique drastically reduces memory usage at inference time and also allows us to use a single model at test time, solving both frame interpolation and spatial up-sampling, saving training cost. We show that HiFI helps significantly with high resolution and complex repeated textures that require global context. HiFI demonstrates comparable or beyond state-of-the-art performance on multiple benchmarks (Vimeo, Xiph, X-Test, SEPE-8K). On our newly introduced dataset that focuses on particularly challenging cases, HiFI also significantly outperforms other baselines on these cases. Please visit our project page for video results: https://hifi-diffusion.github.io
Still-Moving: Customized Video Generation without Customized Video Data
Jul 11, 2024

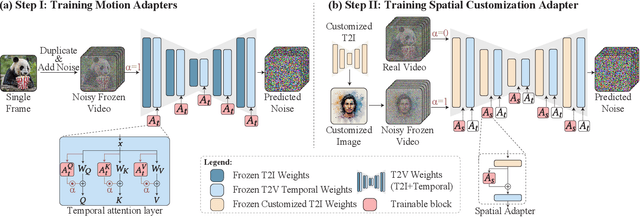

Customizing text-to-image (T2I) models has seen tremendous progress recently, particularly in areas such as personalization, stylization, and conditional generation. However, expanding this progress to video generation is still in its infancy, primarily due to the lack of customized video data. In this work, we introduce Still-Moving, a novel generic framework for customizing a text-to-video (T2V) model, without requiring any customized video data. The framework applies to the prominent T2V design where the video model is built over a text-to-image (T2I) model (e.g., via inflation). We assume access to a customized version of the T2I model, trained only on still image data (e.g., using DreamBooth or StyleDrop). Naively plugging in the weights of the customized T2I model into the T2V model often leads to significant artifacts or insufficient adherence to the customization data. To overcome this issue, we train lightweight $\textit{Spatial Adapters}$ that adjust the features produced by the injected T2I layers. Importantly, our adapters are trained on $\textit{"frozen videos"}$ (i.e., repeated images), constructed from image samples generated by the customized T2I model. This training is facilitated by a novel $\textit{Motion Adapter}$ module, which allows us to train on such static videos while preserving the motion prior of the video model. At test time, we remove the Motion Adapter modules and leave in only the trained Spatial Adapters. This restores the motion prior of the T2V model while adhering to the spatial prior of the customized T2I model. We demonstrate the effectiveness of our approach on diverse tasks including personalized, stylized, and conditional generation. In all evaluated scenarios, our method seamlessly integrates the spatial prior of the customized T2I model with a motion prior supplied by the T2V model.
Magic Insert: Style-Aware Drag-and-Drop
Jul 02, 2024We present Magic Insert, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. This work formalizes the problem of style-aware drag-and-drop and presents a method for tackling it by addressing two sub-problems: style-aware personalization and realistic object insertion in stylized images. For style-aware personalization, our method first fine-tunes a pretrained text-to-image diffusion model using LoRA and learned text tokens on the subject image, and then infuses it with a CLIP representation of the target style. For object insertion, we use Bootstrapped Domain Adaption to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional approaches such as inpainting. Finally, we present a dataset, SubjectPlop, to facilitate evaluation and future progress in this area. Project page: https://magicinsert.github.io/
Probing the 3D Awareness of Visual Foundation Models
Apr 12, 2024Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.