 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenVerse: Versatile Multi-concept Personalization in Token Modulation Space
Jan 21, 2025



We present TokenVerse -- a method for multi-concept personalization, leveraging a pre-trained text-to-image diffusion model. Our framework can disentangle complex visual elements and attributes from as little as a single image, while enabling seamless plug-and-play generation of combinations of concepts extracted from multiple images. As opposed to existing works, TokenVerse can handle multiple images with multiple concepts each, and supports a wide-range of concepts, including objects, accessories, materials, pose, and lighting. Our work exploits a DiT-based text-to-image model, in which the input text affects the generation through both attention and modulation (shift and scale). We observe that the modulation space is semantic and enables localized control over complex concepts. Building on this insight, we devise an optimization-based framework that takes as input an image and a text description, and finds for each word a distinct direction in the modulation space. These directions can then be used to generate new images that combine the learned concepts in a desired configuration. We demonstrate the effectiveness of TokenVerse in challenging personalization settings, and showcase its advantages over existing methods. project's webpage in https://token-verse.github.io/
Still-Moving: Customized Video Generation without Customized Video Data
Jul 11, 2024

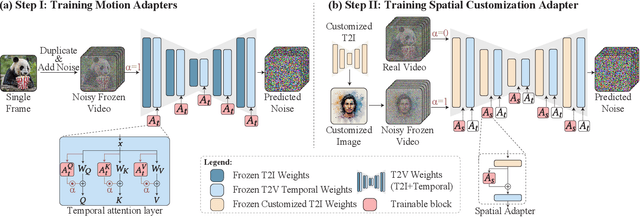

Customizing text-to-image (T2I) models has seen tremendous progress recently, particularly in areas such as personalization, stylization, and conditional generation. However, expanding this progress to video generation is still in its infancy, primarily due to the lack of customized video data. In this work, we introduce Still-Moving, a novel generic framework for customizing a text-to-video (T2V) model, without requiring any customized video data. The framework applies to the prominent T2V design where the video model is built over a text-to-image (T2I) model (e.g., via inflation). We assume access to a customized version of the T2I model, trained only on still image data (e.g., using DreamBooth or StyleDrop). Naively plugging in the weights of the customized T2I model into the T2V model often leads to significant artifacts or insufficient adherence to the customization data. To overcome this issue, we train lightweight $\textit{Spatial Adapters}$ that adjust the features produced by the injected T2I layers. Importantly, our adapters are trained on $\textit{"frozen videos"}$ (i.e., repeated images), constructed from image samples generated by the customized T2I model. This training is facilitated by a novel $\textit{Motion Adapter}$ module, which allows us to train on such static videos while preserving the motion prior of the video model. At test time, we remove the Motion Adapter modules and leave in only the trained Spatial Adapters. This restores the motion prior of the T2V model while adhering to the spatial prior of the customized T2I model. We demonstrate the effectiveness of our approach on diverse tasks including personalized, stylized, and conditional generation. In all evaluated scenarios, our method seamlessly integrates the spatial prior of the customized T2I model with a motion prior supplied by the T2V model.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024



We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Teaching CLIP to Count to Ten
Feb 23, 2023
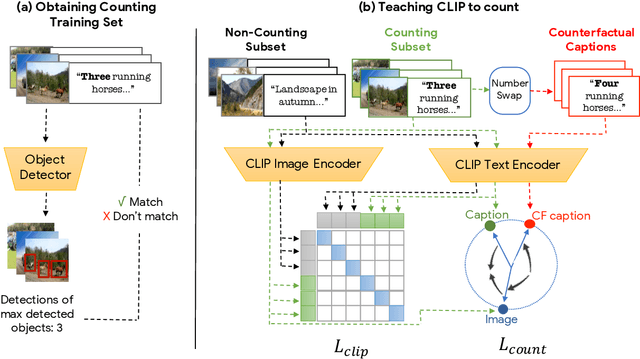
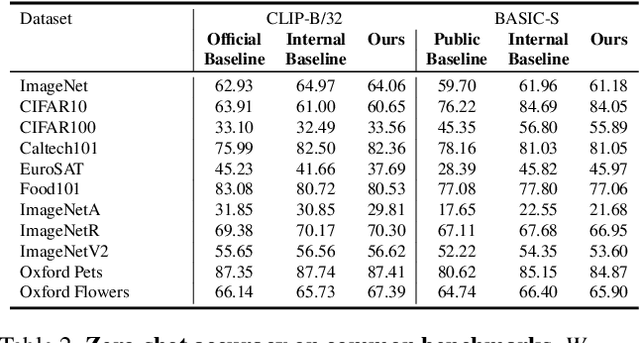

Large vision-language models (VLMs), such as CLIP, learn rich joint image-text representations, facilitating advances in numerous downstream tasks, including zero-shot classification and text-to-image generation. Nevertheless, existing VLMs exhibit a prominent well-documented limitation - they fail to encapsulate compositional concepts such as counting. We introduce a simple yet effective method to improve the quantitative understanding of VLMs, while maintaining their overall performance on common benchmarks. Specifically, we propose a new counting-contrastive loss used to finetune a pre-trained VLM in tandem with its original objective. Our counting loss is deployed over automatically-created counterfactual examples, each consisting of an image and a caption containing an incorrect object count. For example, an image depicting three dogs is paired with the caption "Six dogs playing in the yard". Our loss encourages discrimination between the correct caption and its counterfactual variant which serves as a hard negative example. To the best of our knowledge, this work is the first to extend CLIP's capabilities to object counting. Furthermore, we introduce "CountBench" - a new image-text counting benchmark for evaluating a model's understanding of object counting. We demonstrate a significant improvement over state-of-the-art baseline models on this task. Finally, we leverage our count-aware CLIP model for image retrieval and text-conditioned image generation, demonstrating that our model can produce specific counts of objects more reliably than existing ones.
SpeedNet: Learning the Speediness in Videos
Apr 13, 2020
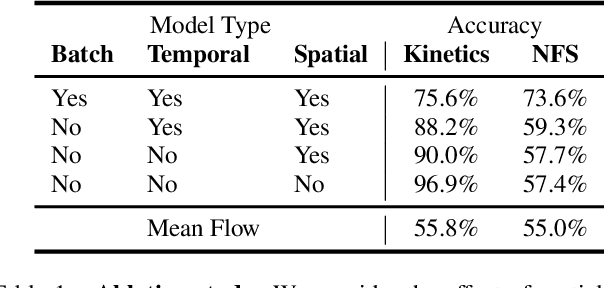
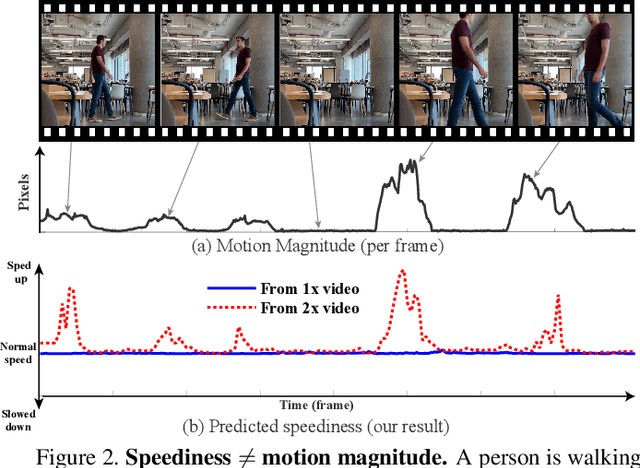
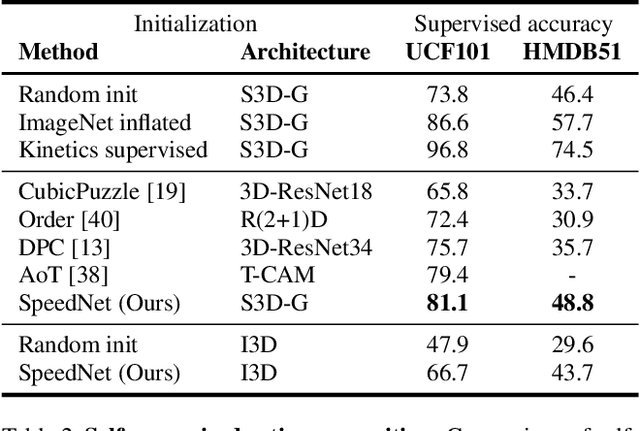
We wish to automatically predict the "speediness" of moving objects in videos---whether they move faster, at, or slower than their "natural" speed. The core component in our approach is SpeedNet---a novel deep network trained to detect if a video is playing at normal rate, or if it is sped up. SpeedNet is trained on a large corpus of natural videos in a self-supervised manner, without requiring any manual annotations. We show how this single, binary classification network can be used to detect arbitrary rates of speediness of objects. We demonstrate prediction results by SpeedNet on a wide range of videos containing complex natural motions, and examine the visual cues it utilizes for making those predictions. Importantly, we show that through predicting the speed of videos, the model learns a powerful and meaningful space-time representation that goes beyond simple motion cues. We demonstrate how those learned features can boost the performance of self-supervised action recognition, and can be used for video retrieval. Furthermore, we also apply SpeedNet for generating time-varying, adaptive video speedups, which can allow viewers to watch videos faster, but with less of the jittery, unnatural motions typical to videos that are sped up uniformly.
Neural separation of observed and unobserved distributions
Nov 30, 2018



Separating mixed distributions is a long standing challenge for machine learning and signal processing. Applications include: single-channel multi-speaker separation (cocktail party problem), singing voice separation and separating reflections from images. Most current methods either rely on making strong assumptions on the source distributions (e.g. sparsity, low rank, repetitiveness) or rely on having training samples of each source in the mixture. In this work, we tackle the scenario of extracting an unobserved distribution additively mixed with a signal from an observed (arbitrary) distribution. We introduce a new method: Neural Egg Separation - an iterative method that learns to separate the known distribution from progressively finer estimates of the unknown distribution. In some settings, Neural Egg Separation is initialization sensitive, we therefore introduce GLO Masking which ensures a good initialization. Extensive experiments show that our method outperforms current methods that use the same level of supervision and often achieves similar performance to full supervision.
Dynamic Temporal Alignment of Speech to Lips
Aug 19, 2018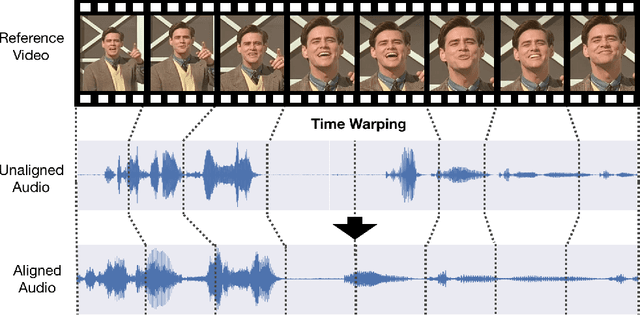
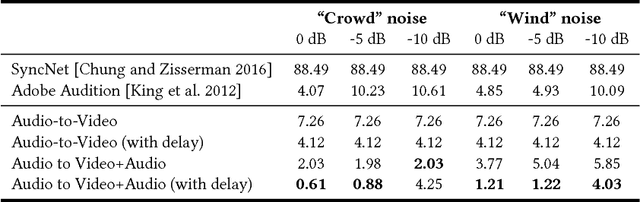
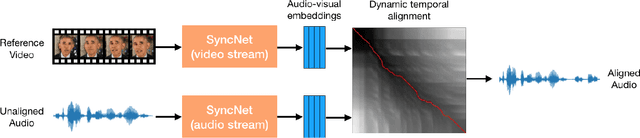
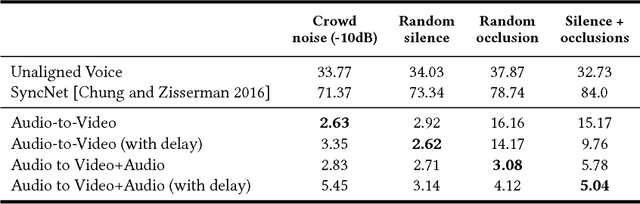
Many speech segments in movies are re-recorded in a studio during postproduction, to compensate for poor sound quality as recorded on location. Manual alignment of the newly-recorded speech with the original lip movements is a tedious task. We present an audio-to-video alignment method for automating speech to lips alignment, stretching and compressing the audio signal to match the lip movements. This alignment is based on deep audio-visual features, mapping the lips video and the speech signal to a shared representation. Using this shared representation we compute the lip-sync error between every short speech period and every video frame, followed by the determination of the optimal corresponding frame for each short sound period over the entire video clip. We demonstrate successful alignment both quantitatively, using a human perception-inspired metric, as well as qualitatively. The strongest advantage of our audio-to-video approach is in cases where the original voice in unclear, and where a constant shift of the sound can not give a perfect alignment. In these cases state-of-the-art methods will fail.
Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
Aug 09, 2018



We present a joint audio-visual model for isolating a single speech signal from a mixture of sounds such as other speakers and background noise. Solving this task using only audio as input is extremely challenging and does not provide an association of the separated speech signals with speakers in the video. In this paper, we present a deep network-based model that incorporates both visual and auditory signals to solve this task. The visual features are used to "focus" the audio on desired speakers in a scene and to improve the speech separation quality. To train our joint audio-visual model, we introduce AVSpeech, a new dataset comprised of thousands of hours of video segments from the Web. We demonstrate the applicability of our method to classic speech separation tasks, as well as real-world scenarios involving heated interviews, noisy bars, and screaming children, only requiring the user to specify the face of the person in the video whose speech they want to isolate. Our method shows clear advantage over state-of-the-art audio-only speech separation in cases of mixed speech. In addition, our model, which is speaker-independent (trained once, applicable to any speaker), produces better results than recent audio-visual speech separation methods that are speaker-dependent (require training a separate model for each speaker of interest).
* Accepted to SIGGRAPH 2018. Project webpage: https://looking-to-listen.github.io
Seeing Through Noise: Visually Driven Speaker Separation and Enhancement
Feb 09, 2018
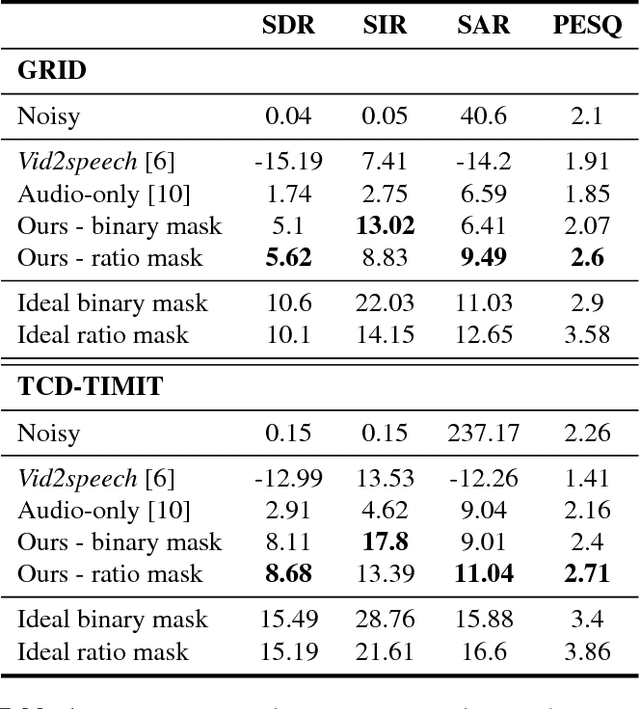
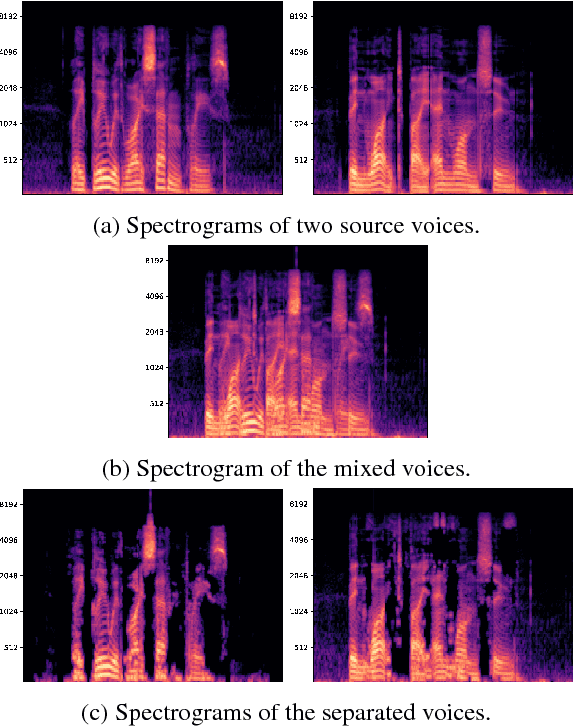
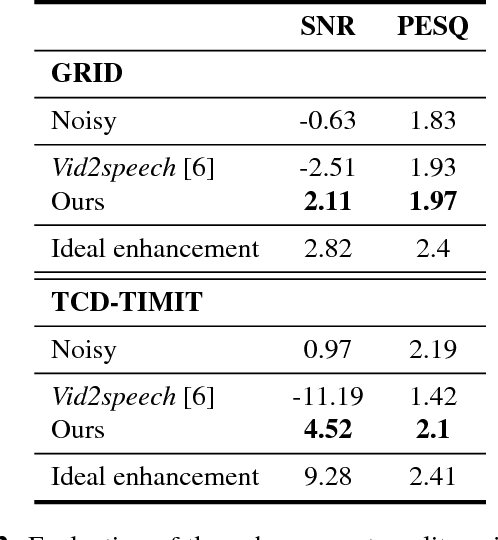
Isolating the voice of a specific person while filtering out other voices or background noises is challenging when video is shot in noisy environments. We propose audio-visual methods to isolate the voice of a single speaker and eliminate unrelated sounds. First, face motions captured in the video are used to estimate the speaker's voice, by passing the silent video frames through a video-to-speech neural network-based model. Then the speech predictions are applied as a filter on the noisy input audio. This approach avoids using mixtures of sounds in the learning process, as the number of such possible mixtures is huge, and would inevitably bias the trained model. We evaluate our method on two audio-visual datasets, GRID and TCD-TIMIT, and show that our method attains significant SDR and PESQ improvements over the raw video-to-speech predictions, and a well-known audio-only method.
Improved Speech Reconstruction from Silent Video
Aug 29, 2017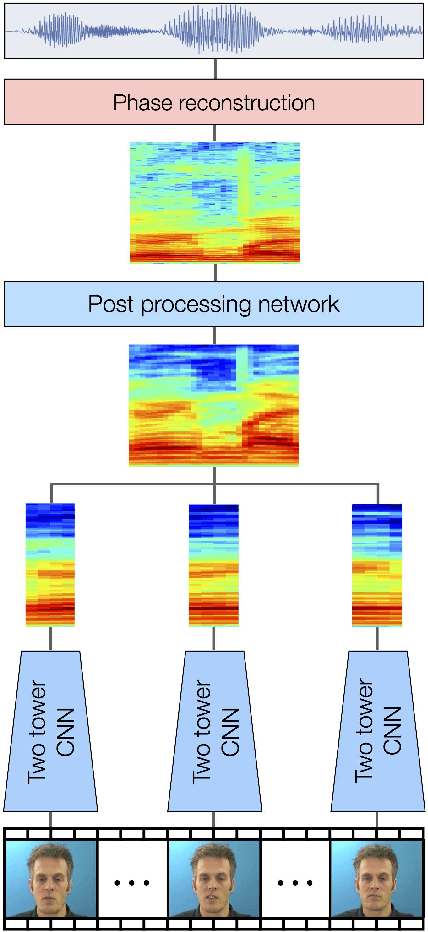

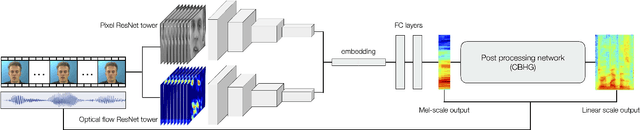

Speechreading is the task of inferring phonetic information from visually observed articulatory facial movements, and is a notoriously difficult task for humans to perform. In this paper we present an end-to-end model based on a convolutional neural network (CNN) for generating an intelligible and natural-sounding acoustic speech signal from silent video frames of a speaking person. We train our model on speakers from the GRID and TCD-TIMIT datasets, and evaluate the quality and intelligibility of reconstructed speech using common objective measurements. We show that speech predictions from the proposed model attain scores which indicate significantly improved quality over existing models. In addition, we show promising results towards reconstructing speech from an unconstrained dictionary.