 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image is Worth More Than a Thousand Words: Towards Disentanglement in the Wild
Jun 29, 2021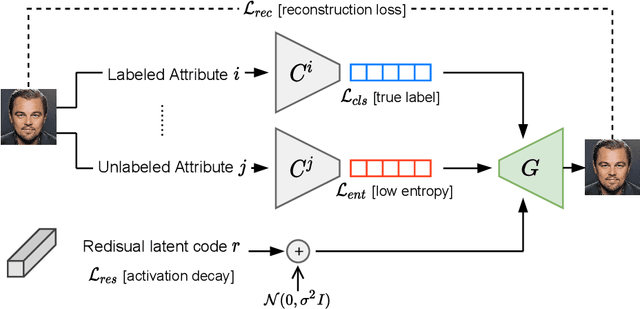
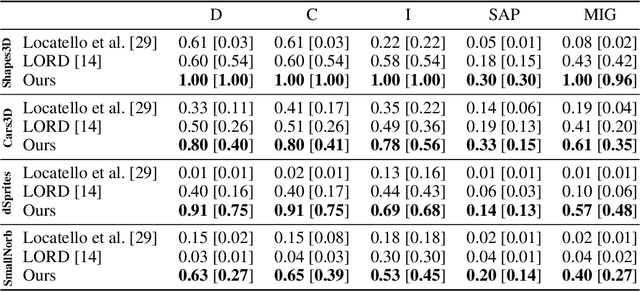

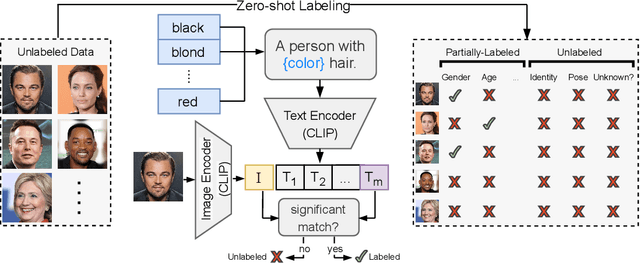
Unsupervised disentanglement has been shown to be theoretically impossible without inductive biases on the models and the data. As an alternative approach, recent methods rely on limited supervision to disentangle the factors of variation and allow their identifiability. While annotating the true generative factors is only required for a limited number of observations, we argue that it is infeasible to enumerate all the factors of variation that describe a real-world image distribution. To this end, we propose a method for disentangling a set of factors which are only partially labeled, as well as separating the complementary set of residual factors that are never explicitly specified. Our success in this challenging setting, demonstrated on synthetic benchmarks, gives rise to leveraging off-the-shelf image descriptors to partially annotate a subset of attributes in real image domains (e.g. of human faces) with minimal manual effort. Specifically, we use a recent language-image embedding model (CLIP) to annotate a set of attributes of interest in a zero-shot manner and demonstrate state-of-the-art disentangled image manipulation results.
Scaling-up Disentanglement for Image Translation
Mar 25, 2021
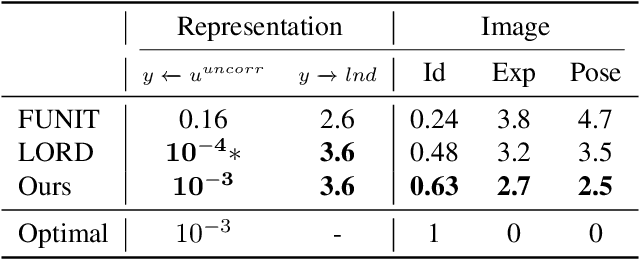

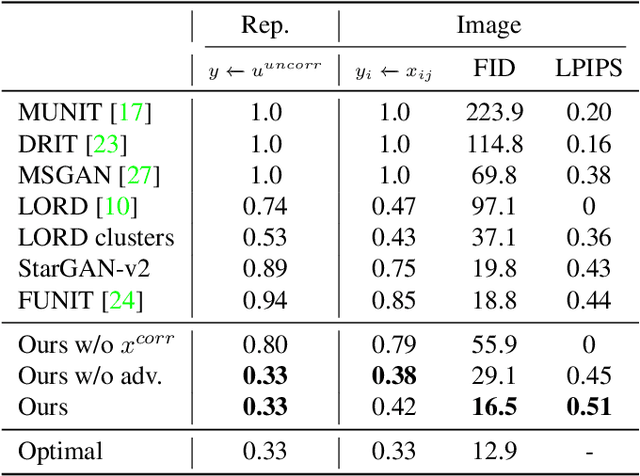
Image translation methods typically aim to manipulate a set of labeled attributes (given as supervision at training time e.g. domain label) while leaving the unlabeled attributes intact. Current methods achieve either: (i) disentanglement, which exhibits low visual fidelity and can only be satisfied where the attributes are perfectly uncorrelated. (ii) visually-plausible translations, which are clearly not disentangled. In this work, we propose OverLORD, a single framework for disentangling labeled and unlabeled attributes as well as synthesizing high-fidelity images, which is composed of two stages; (i) Disentanglement: Learning disentangled representations with latent optimization. Differently from previous approaches, we do not rely on adversarial training or any architectural biases. (ii) Synthesis: Training feed-forward encoders for inferring the learned attributes and tuning the generator in an adversarial manner to increase the perceptual quality. When the labeled and unlabeled attributes are correlated, we model an additional representation that accounts for the correlated attributes and improves disentanglement. We highlight that our flexible framework covers multiple image translation settings e.g. attribute manipulation, pose-appearance translation, segmentation-guided synthesis and shape-texture transfer. In an extensive evaluation, we present significantly better disentanglement with higher translation quality and greater output diversity than state-of-the-art methods.
Improving Style-Content Disentanglement in Image-to-Image Translation
Jul 09, 2020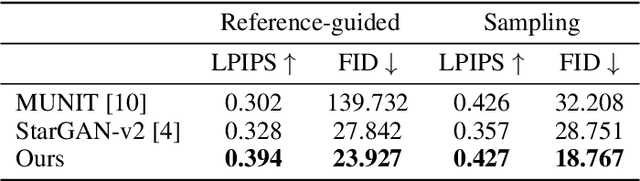

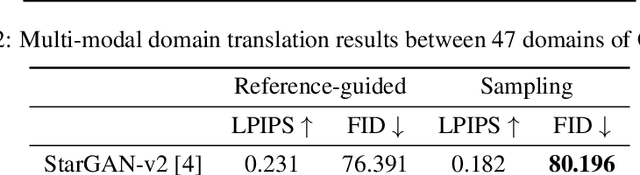

Unsupervised image-to-image translation methods have achieved tremendous success in recent years. However, it can be easily observed that their models contain significant entanglement which often hurts the translation performance. In this work, we propose a principled approach for improving style-content disentanglement in image-to-image translation. By considering the information flow into each of the representations, we introduce an additional loss term which serves as a content-bottleneck. We show that the results of our method are significantly more disentangled than those produced by current methods, while further improving the visual quality and translation diversity.
Latent Optimization for Non-adversarial Representation Disentanglement
Jun 27, 2019



Disentanglement between pose and content is a key task for artificial intelligence and has attracted much research interest. Current methods for disentanglement include adversarial training and introducing cycle constraints. In this work, we present a novel disentanglement method which does not use adversarial training, achieving state-of-the-art performance. Our method uses latent optimization of an architecture borrowed from style-transfer, to enforce separation of pose and content. We overcome the test generalization issues of latent optimization, by a novel two-stage approach. In extensive experiments, our method is shown to achieve better disentanglement performance than both adversarial and non-adversarial methods that use the same level of supervision.
Style Generator Inversion for Image Enhancement and Animation
Jun 05, 2019
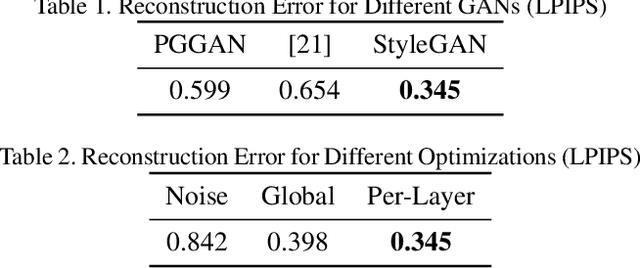


One of the main motivations for training high quality image generative models is their potential use as tools for image manipulation. Recently, generative adversarial networks (GANs) have been able to generate images of remarkable quality. Unfortunately, adversarially-trained unconditional generator networks have not been successful as image priors. One of the main requirements for a network to act as a generative image prior, is being able to generate every possible image from the target distribution. Adversarial learning often experiences mode-collapse, which manifests in generators that cannot generate some modes of the target distribution. Another requirement often not satisfied is invertibility i.e. having an efficient way of finding a valid input latent code given a required output image. In this work, we show that differently from earlier GANs, the very recently proposed style-generators are quite easy to invert. We use this important observation to propose style generators as general purpose image priors. We show that style generators outperform other GANs as well as Deep Image Prior as priors for image enhancement tasks. The latent space spanned by style-generators satisfies linear identity-pose relations. The latent space linearity, combined with invertibility, allows us to animate still facial images without supervision. Extensive experiments are performed to support the main contributions of this paper.
Visual Speech Enhancement
Jun 13, 2018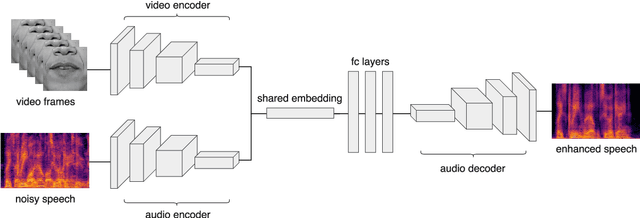
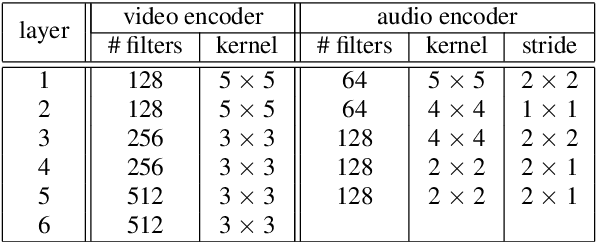

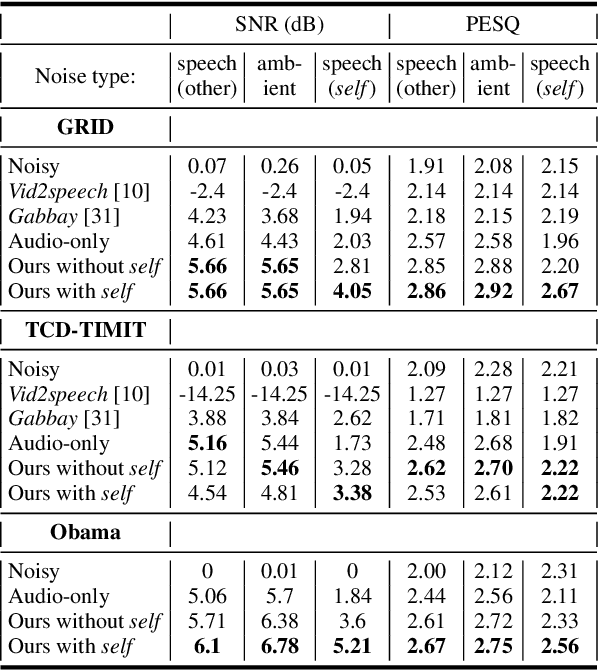
When video is shot in noisy environment, the voice of a speaker seen in the video can be enhanced using the visible mouth movements, reducing background noise. While most existing methods use audio-only inputs, improved performance is obtained with our visual speech enhancement, based on an audio-visual neural network. We include in the training data videos to which we added the voice of the target speaker as background noise. Since the audio input is not sufficient to separate the voice of a speaker from his own voice, the trained model better exploits the visual input and generalizes well to different noise types. The proposed model outperforms prior audio visual methods on two public lipreading datasets. It is also the first to be demonstrated on a dataset not designed for lipreading, such as the weekly addresses of Barack Obama.
Seeing Through Noise: Visually Driven Speaker Separation and Enhancement
Feb 09, 2018
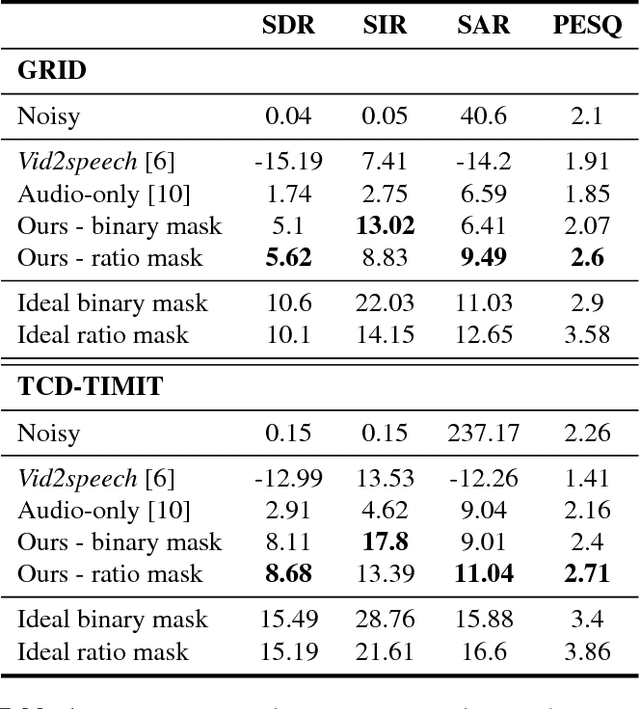
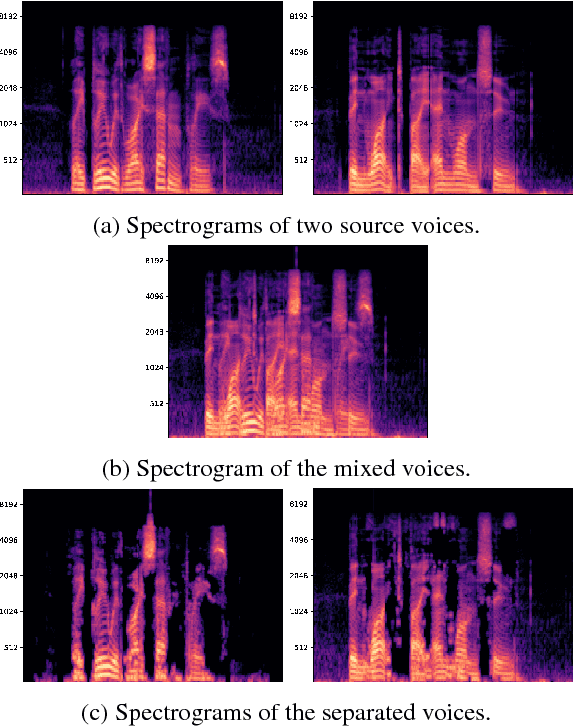
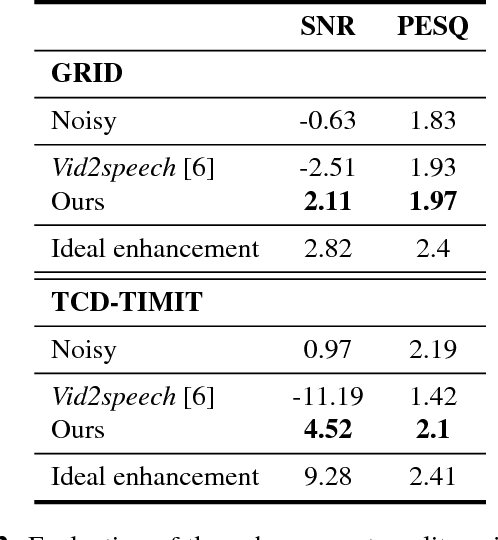
Isolating the voice of a specific person while filtering out other voices or background noises is challenging when video is shot in noisy environments. We propose audio-visual methods to isolate the voice of a single speaker and eliminate unrelated sounds. First, face motions captured in the video are used to estimate the speaker's voice, by passing the silent video frames through a video-to-speech neural network-based model. Then the speech predictions are applied as a filter on the noisy input audio. This approach avoids using mixtures of sounds in the learning process, as the number of such possible mixtures is huge, and would inevitably bias the trained model. We evaluate our method on two audio-visual datasets, GRID and TCD-TIMIT, and show that our method attains significant SDR and PESQ improvements over the raw video-to-speech predictions, and a well-known audio-only method.