 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Generator Inversion for Image Enhancement and Animation
Paper and Code

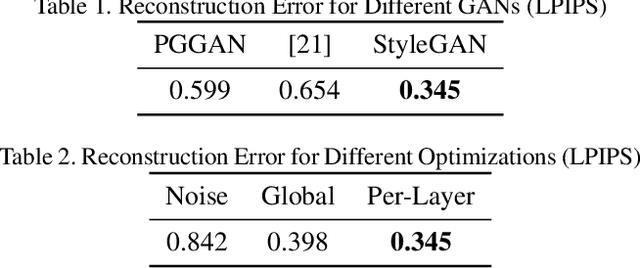


One of the main motivations for training high quality image generative models is their potential use as tools for image manipulation. Recently, generative adversarial networks (GANs) have been able to generate images of remarkable quality. Unfortunately, adversarially-trained unconditional generator networks have not been successful as image priors. One of the main requirements for a network to act as a generative image prior, is being able to generate every possible image from the target distribution. Adversarial learning often experiences mode-collapse, which manifests in generators that cannot generate some modes of the target distribution. Another requirement often not satisfied is invertibility i.e. having an efficient way of finding a valid input latent code given a required output image. In this work, we show that differently from earlier GANs, the very recently proposed style-generators are quite easy to invert. We use this important observation to propose style generators as general purpose image priors. We show that style generators outperform other GANs as well as Deep Image Prior as priors for image enhancement tasks. The latent space spanned by style-generators satisfies linear identity-pose relations. The latent space linearity, combined with invertibility, allows us to animate still facial images without supervision. Extensive experiments are performed to support the main contributions of this paper.