 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChirp Parameter Optimization and Distributed Detection for Cooperative RSMA-AFDM Systems
Jun 11, 2026Affine frequency division multiplexing (AFDM) exhibits excellent Doppler robustness and the ability to characterize doubly selective channels. However, its signal dispersion characteristics make it challenging to directly adopt traditional time-frequency multiple access schemes. To address this issue, we introduce cooperative rate splitting multiple access (RSMA) for AFDM systems. The flexible configuration of AFDM chirp parameters can reduce the correlation between users' equivalent channels, which decreases the interference from RSMA private streams. We conduct a theoretical analysis of the cooperative RSMA-AFDM system and demonstrate that minimizing the overlap in the channel column spaces among users can effectively enhance the system performance. Guided by this analysis, we design a chirp parameter optimization scheme that reduces multi-user interference and maximizes diversity gain. To fully exploit the diversity gain brought by the proposed chirp parameter optimization, two expectation propagation (EP)-based distributed cooperative detection schemes are proposed. First, a decision-fusion-based method is developed, where local information and cooperative information are fused by maximum ratio combining, achieving a globally consistent estimate of the common stream. Second, we develop a belief-consensus EP-based detection scheme. In each iteration, user nodes exchange and fuse the first- and second-order statistics of the common stream, and the resulting beliefs gradually converge to a consistent global decision, which significantly improves the overall reliability.
Efficient Hybrid SE(3)-Equivariant Visuomotor Flow Policy via Spherical Harmonics for Robot Manipulation
Mar 24, 2026While existing equivariant methods enhance data efficiency, they suffer from high computational intensity, reliance on single-modality inputs, and instability when combined with fast-sampling methods. In this work, we propose E3Flow, a novel framework that addresses the critical limitations of equivariant diffusion policies. E3Flow overcomes these challenges, successfully unifying efficient rectified flow with stable, multi-modal equivariant learning for the first time. Our framework is built upon spherical harmonic representations to ensure rigorous SO(3) equivariance. We introduce a novel invariant Feature Enhancement Module (FEM) that dynamically fuses hybrid visual modalities (point clouds and images), injecting rich visual cues into the spherical harmonic features. We evaluate E3Flow on 8 manipulation tasks from the MimicGen and further conduct 4 real-world experiments to validate its effectiveness in physical environments. Simulation results show that E3Flow achieves a 3.12% improvement in average success rate over the state-of-the-art Spherical Diffusion Policy (SDP) while simultaneously delivering a 7x inference speedup. E3Flow thus demonstrates a new and highly effective trade-off between performance, efficiency, and data efficiency for robotic policy learning. Code: https://github.com/zql-kk/E3Flow.
Superimposed-Pilot OTFS Under Fractional Doppler: Modular End-to-End Learning
Jan 30, 2026Orthogonal time frequency space (OTFS) modulation has emerged as a promising candidate to overcome the performance degradation of orthogonal frequency division multiplexing (OFDM), which are commonly encountered in high-mobility wireless communication scenarios. However, conventional OTFS transceivers rely on multiple separately designed signal-processing modules, whose isolated optimization often limits global optimal performance. To overcome limitations, this paper proposes a modular deep learning (DL) based end-to-end OTFS transceiver framework that consists of trainable and interchangeable neural network (NN) modules, including constellation mapping/demapping, superimposed pilot placement, inverse Zak (IZak)/Zak transforms, and a U-Net-enhanced NN tailored for joint channel estimation and detection (JCED), while explicitly accounting for the impact of the cyclic prefix. This physics-informed modular architecture provides flexibility for integration with conventional OTFS systems and adaptability to different communication configurations. Simulations demonstrate that the proposed design significantly outperforms baseline methods in terms of both normalized mean squared error (NMSE) and detection reliability, maintaining robustness under integer and fractional Doppler conditions. The results highlight the potential of DL-based end-to-end optimization to enable practical and high-performance OTFS transceivers for next-generation high-mobility networks.
FlowPolicy: Enabling Fast and Robust 3D Flow-based Policy via Consistency Flow Matching for Robot Manipulation
Dec 06, 2024Robots can acquire complex manipulation skills by learning policies from expert demonstrations, which is often known as vision-based imitation learning. Generating policies based on diffusion and flow matching models has been shown to be effective, particularly in robotics manipulation tasks. However, recursion-based approaches are often inference inefficient in working from noise distributions to policy distributions, posing a challenging trade-off between efficiency and quality. This motivates us to propose FlowPolicy, a novel framework for fast policy generation based on consistency flow matching and 3D vision. Our approach refines the flow dynamics by normalizing the self-consistency of the velocity field, enabling the model to derive task execution policies in a single inference step. Specifically, FlowPolicy conditions on the observed 3D point cloud, where consistency flow matching directly defines straight-line flows from different time states to the same action space, while simultaneously constraining their velocity values, that is, we approximate the trajectories from noise to robot actions by normalizing the self-consistency of the velocity field within the action space, thus improving the inference efficiency. We validate the effectiveness of FlowPolicy on Adroit and Metaworld, demonstrating a 7$\times$ increase in inference speed while maintaining competitive average success rates compared to state-of-the-art policy models. Codes will be made publicly available.
Adaptive Paradigm Synergy: Can a Cross-Paradigm Objective Enhance Long-Tailed Learning?
Oct 30, 2024Self-supervised learning (SSL) has achieved impressive results across several computer vision tasks, even rivaling supervised methods. However, its performance degrades on real-world datasets with long-tailed distributions due to difficulties in capturing inherent class imbalances. Although supervised long-tailed learning offers significant insights, the absence of labels in SSL prevents direct transfer of these strategies.To bridge this gap, we introduce Adaptive Paradigm Synergy (APS), a cross-paradigm objective that seeks to unify the strengths of both paradigms. Our approach reexamines contrastive learning from a spatial structure perspective, dynamically adjusting the uniformity of latent space structure through adaptive temperature tuning. Furthermore, we draw on a re-weighting strategy from supervised learning to compensate for the shortcomings of temperature adjustment in explicit quantity perception.Extensive experiments on commonly used long-tailed datasets demonstrate that APS improves performance effectively and efficiently. Our findings reveal the potential for deeper integration between supervised and self-supervised learning, paving the way for robust models that handle real-world class imbalance.
PointRegGPT: Boosting 3D Point Cloud Registration using Generative Point-Cloud Pairs for Training
Jul 19, 2024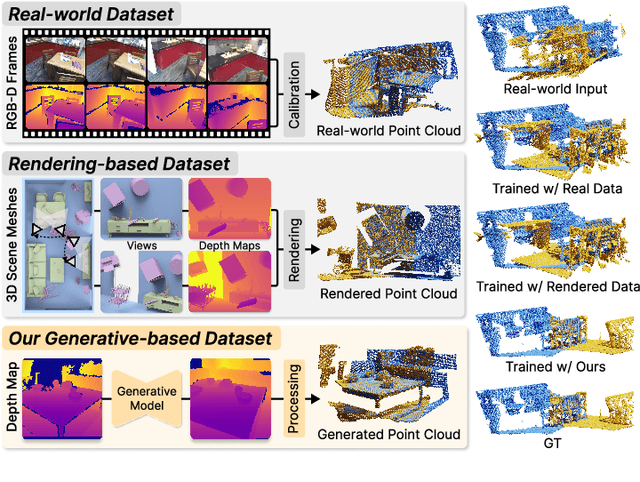
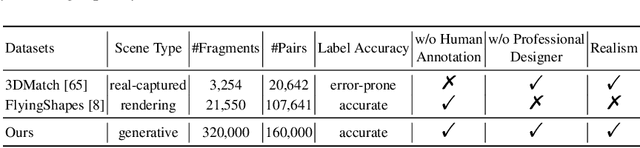


Data plays a crucial role in training learning-based methods for 3D point cloud registration. However, the real-world dataset is expensive to build, while rendering-based synthetic data suffers from domain gaps. In this work, we present PointRegGPT, boosting 3D point cloud registration using generative point-cloud pairs for training. Given a single depth map, we first apply a random camera motion to re-project it into a target depth map. Converting them to point clouds gives a training pair. To enhance the data realism, we formulate a generative model as a depth inpainting diffusion to process the target depth map with the re-projected source depth map as the condition. Also, we design a depth correction module to alleviate artifacts caused by point penetration during the re-projection. To our knowledge, this is the first generative approach that explores realistic data generation for indoor point cloud registration. When equipped with our approach, several recent algorithms can improve their performance significantly and achieve SOTA consistently on two common benchmarks. The code and dataset will be released on https://github.com/Chen-Suyi/PointRegGPT.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024



We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
SpectralNeRF: Physically Based Spectral Rendering with Neural Radiance Field
Dec 14, 2023
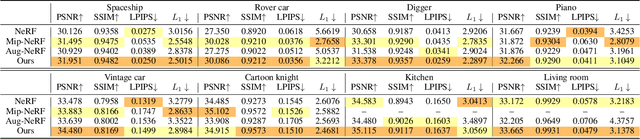


In this paper, we propose SpectralNeRF, an end-to-end Neural Radiance Field (NeRF)-based architecture for high-quality physically based rendering from a novel spectral perspective. We modify the classical spectral rendering into two main steps, 1) the generation of a series of spectrum maps spanning different wavelengths, 2) the combination of these spectrum maps for the RGB output. Our SpectralNeRF follows these two steps through the proposed multi-layer perceptron (MLP)-based architecture (SpectralMLP) and Spectrum Attention UNet (SAUNet). Given the ray origin and the ray direction, the SpectralMLP constructs the spectral radiance field to obtain spectrum maps of novel views, which are then sent to the SAUNet to produce RGB images of white-light illumination. Applying NeRF to build up the spectral rendering is a more physically-based way from the perspective of ray-tracing. Further, the spectral radiance fields decompose difficult scenes and improve the performance of NeRF-based methods. Comprehensive experimental results demonstrate the proposed SpectralNeRF is superior to recent NeRF-based methods when synthesizing new views on synthetic and real datasets. The codes and datasets are available at https://github.com/liru0126/SpectralNeRF.
Exposure Fusion for Hand-held Camera Inputs with Optical Flow and PatchMatch
Apr 10, 2023This paper proposes a hybrid synthesis method for multi-exposure image fusion taken by hand-held cameras. Motions either due to the shaky camera or caused by dynamic scenes should be compensated before any content fusion. Any misalignment can easily cause blurring/ghosting artifacts in the fused result. Our hybrid method can deal with such motions and maintain the exposure information of each input effectively. In particular, the proposed method first applies optical flow for a coarse registration, which performs well with complex non-rigid motion but produces deformations at regions with missing correspondences. The absence of correspondences is due to the occlusions of scene parallax or the moving contents. To correct such error registration, we segment images into superpixels and identify problematic alignments based on each superpixel, which is further aligned by PatchMatch. The method combines the efficiency of optical flow and the accuracy of PatchMatch. After PatchMatch correction, we obtain a fully aligned image stack that facilitates a high-quality fusion that is free from blurring/ghosting artifacts. We compare our method with existing fusion algorithms on various challenging examples, including the static/dynamic, the indoor/outdoor and the daytime/nighttime scenes. Experiment results demonstrate the effectiveness and robustness of our method.
FINet: Dual Branches Feature Interaction for Partial-to-Partial Point Cloud Registration
Jun 07, 2021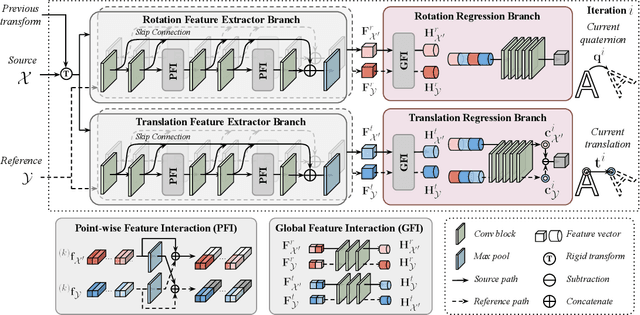
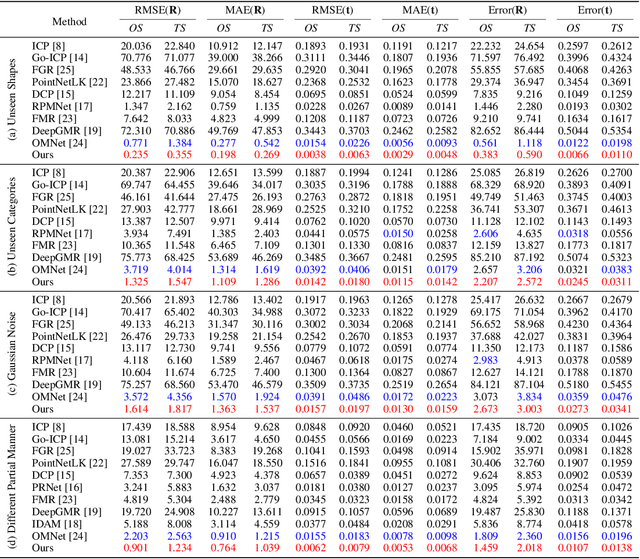
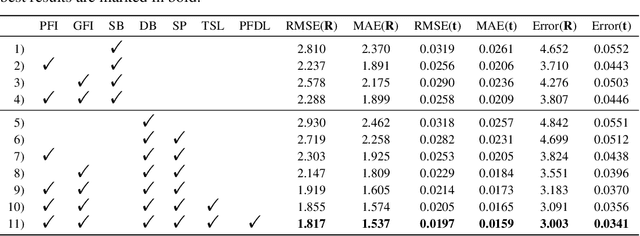
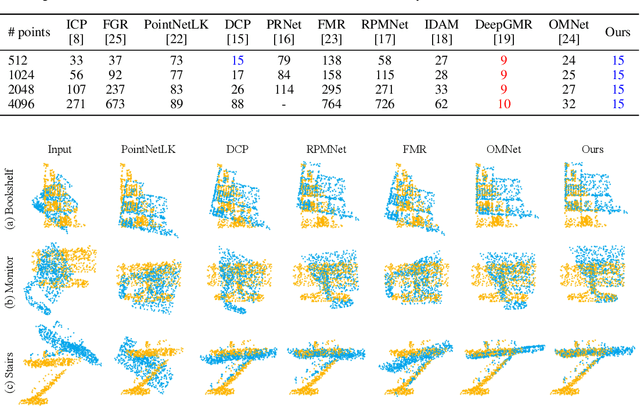
Data association is important in the point cloud registration. In this work, we propose to solve the partial-to-partial registration from a new perspective, by introducing feature interactions between the source and the reference clouds at the feature extraction stage, such that the registration can be realized without the explicit mask estimation or attentions for the overlapping detection as adopted previously. Specifically, we present FINet, a feature interaction-based structure with the capability to enable and strengthen the information associating between the inputs at multiple stages. To achieve this, we first split the features into two components, one for the rotation and one for the translation, based on the fact that they belong to different solution spaces, yielding a dual branches structure. Second, we insert several interaction modules at the feature extractor for the data association. Third, we propose a transformation sensitivity loss to obtain rotation-attentive and translation-attentive features. Experiments demonstrate that our method performs higher precision and robustness compared to the state-of-the-art traditional and learning-based methods.