 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNet: Learning Overlapping Mask for Partial-to-Partial Point Cloud Registration
Mar 03, 2021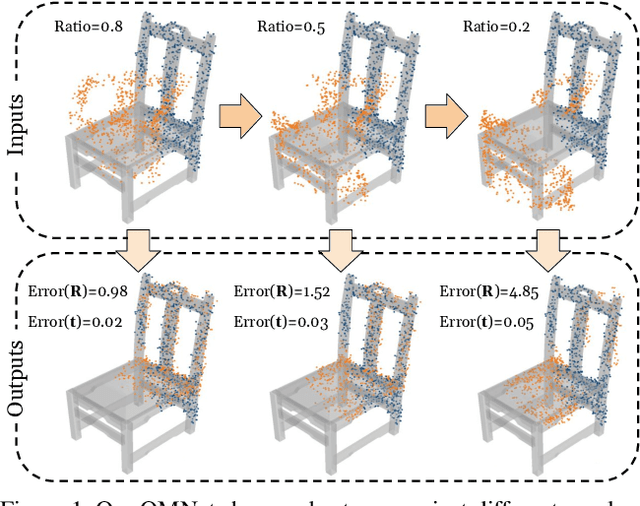

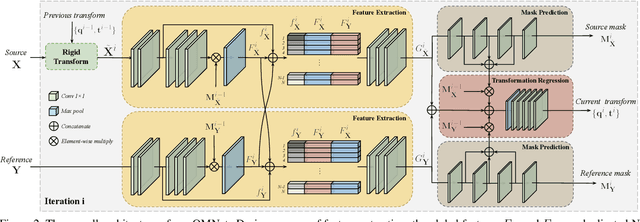
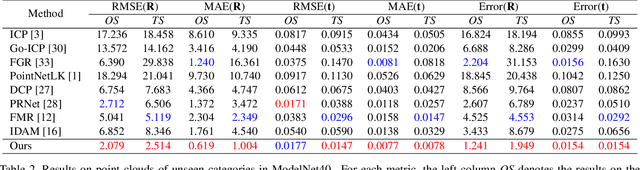
Point cloud registration is a key task in many computational fields. Previous correspondence matching based methods require the point clouds to have distinctive geometric structures to fit a 3D rigid transformation according to point-wise sparse feature matches. However, the accuracy of transformation heavily relies on the quality of extracted features, which are prone to errors with respect partiality and noise of the inputs. In addition, they can not utilize the geometric knowledge of all regions. On the other hand, previous global feature based deep learning approaches can utilize the entire point cloud for the registration, however they ignore the negative effect of non-overlapping points when aggregating global feature from point-wise features. In this paper, we present OMNet, a global feature based iterative network for partial-to-partial point cloud registration. We learn masks in a coarse-to-fine manner to reject non-overlapping regions, which converting the partial-to-partial registration to the registration of the same shapes. Moreover, the data used in previous works are only sampled once from CAD models for each object, resulting the same point cloud for the source and the reference. We propose a more practical manner for data generation, where a CAD model is sampled twice for the source and the reference point clouds, avoiding over-fitting issues that commonly exist previously. Experimental results show that our approach achieves state-of-the-art performance compared to traditional and deep learning methods.
JigsawGAN: Self-supervised Learning for Solving Jigsaw Puzzles with Generative Adversarial Networks
Jan 19, 2021
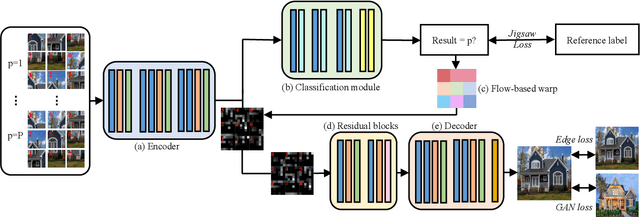
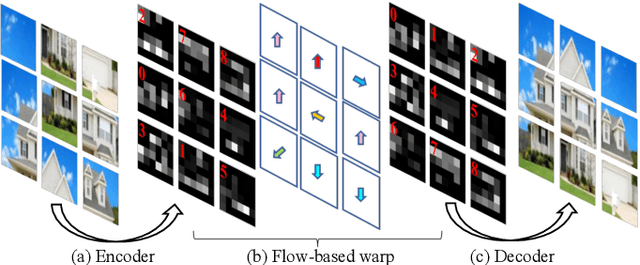

The paper proposes a solution based on Generative Adversarial Network (GAN) for solving jigsaw puzzles. The problem assumes that an image is cut into equal square pieces, and asks to recover the image according to pieces information. Conventional jigsaw solvers often determine piece relationships based on the piece boundaries, which ignore the important semantic information. In this paper, we propose JigsawGAN, a GAN-based self-supervised method for solving jigsaw puzzles with unpaired images (with no prior knowledge of the initial images). We design a multi-task pipeline that includes, (1) a classification branch to classify jigsaw permutations, and (2) a GAN branch to recover features to images with correct orders. The classification branch is constrained by the pseudo-labels generated according to the shuffled pieces. The GAN branch concentrates on the image semantic information, among which the generator produces the natural images to fool the discriminator with reassembled pieces, while the discriminator distinguishes whether a given image belongs to the synthesized or the real target manifold. These two branches are connected by a flow-based warp that is applied to warp features to correct order according to the classification results. The proposed method can solve jigsaw puzzles more efficiently by utilizing both semantic information and edge information simultaneously. Qualitative and quantitative comparisons against several leading prior methods demonstrate the superiority of our method.
RIN: Textured Human Model Recovery and Imitation with a Single Image
Nov 29, 2020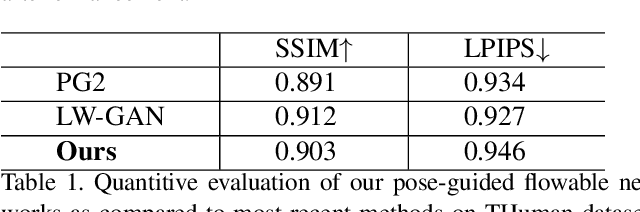
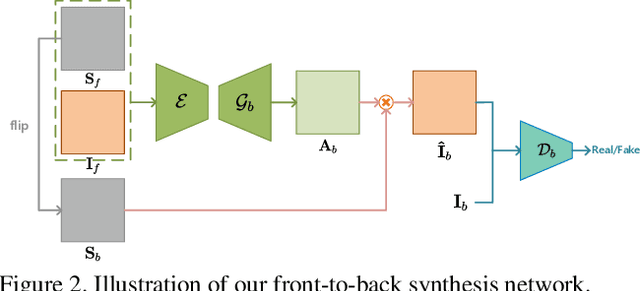

Human imitation has become topical recently, driven by GAN's ability to disentangle human pose and body content. However, the latest methods hardly focus on 3D information, and to avoid self-occlusion, a massive amount of input images are needed. In this paper, we propose RIN, a novel volume-based framework for reconstructing a textured 3D model from a single picture and imitating a subject with the generated model. Specifically, to estimate most of the human texture, we propose a U-Net-like front-to-back translation network. With both front and back images input, the textured volume recovery module allows us to color a volumetric human. A sequence of 3D poses then guides the colored volume via Flowable Disentangle Networks as a volume-to-volume translation task. To project volumes to a 2D plane during training, we design a differentiable depth-aware renderer. Our experiments demonstrate that our volume-based model is adequate for human imitation, and the back view can be estimated reliably using our network. While prior works based on either 2D pose or semantic map often fail for the unstable appearance of a human, our framework can still produce concrete results, which are competitive to those imagined from multi-view input.