 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepySpatial: Generating 3D Visual Programs for Zero-Shot Spatial Reasoning
Mar 01, 2026Multi-modal Large Language Models (MLLMs) have demonstrated strong capabilities in general-purpose perception and reasoning, but they still struggle with tasks that require spatial understanding of the 3D world. To address this, we introduce pySpatial, a visual programming framework that equips MLLMs with the ability to interface with spatial tools via Python code generation. Given an image sequence and a natural-language query, the model composes function calls to spatial tools including 3D reconstruction, camera-pose recovery, novel-view rendering, etc. These operations convert raw 2D inputs into an explorable 3D scene, enabling MLLMs to reason explicitly over structured spatial representations. Notably, pySpatial requires no gradient-based fine-tuning and operates in a fully zero-shot setting. Experimental evaluations on the challenging MindCube and Omni3D-Bench benchmarks demonstrate that our framework pySpatial consistently surpasses strong MLLM baselines; for instance, it outperforms GPT-4.1-mini by 12.94% on MindCube. Furthermore, we conduct real-world indoor navigation experiments where the robot can successfully traverse complex environments using route plans generated by pySpatial, highlighting the practical effectiveness of our approach.
Towards Realistic Scene Generation with LiDAR Diffusion Models
Mar 31, 2024Diffusion models (DMs) excel in photo-realistic image synthesis, but their adaptation to LiDAR scene generation poses a substantial hurdle. This is primarily because DMs operating in the point space struggle to preserve the curve-like patterns and 3D geometry of LiDAR scenes, which consumes much of their representation power. In this paper, we propose LiDAR Diffusion Models (LiDMs) to generate LiDAR-realistic scenes from a latent space tailored to capture the realism of LiDAR scenes by incorporating geometric priors into the learning pipeline. Our method targets three major desiderata: pattern realism, geometry realism, and object realism. Specifically, we introduce curve-wise compression to simulate real-world LiDAR patterns, point-wise coordinate supervision to learn scene geometry, and patch-wise encoding for a full 3D object context. With these three core designs, our method achieves competitive performance on unconditional LiDAR generation in 64-beam scenario and state of the art on conditional LiDAR generation, while maintaining high efficiency compared to point-based DMs (up to 107$\times$ faster). Furthermore, by compressing LiDAR scenes into a latent space, we enable the controllability of DMs with various conditions such as semantic maps, camera views, and text prompts. Our code and pretrained weights are available at https://github.com/hancyran/LiDAR-Diffusion.
GeoMAE: Masked Geometric Target Prediction for Self-supervised Point Cloud Pre-Training
May 15, 2023
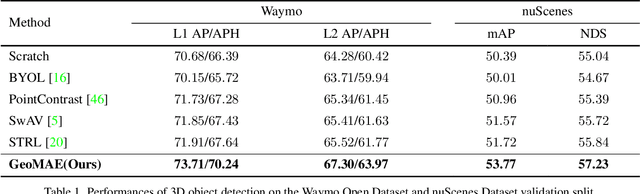
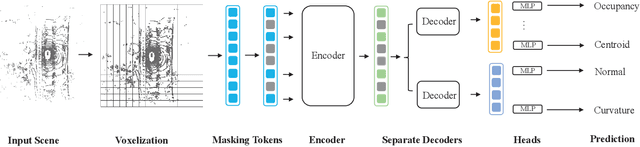
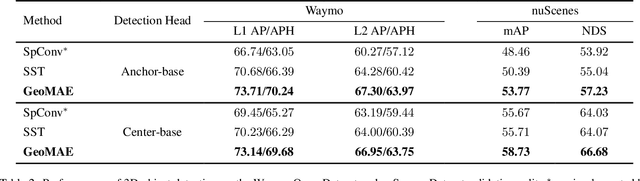
This paper tries to address a fundamental question in point cloud self-supervised learning: what is a good signal we should leverage to learn features from point clouds without annotations? To answer that, we introduce a point cloud representation learning framework, based on geometric feature reconstruction. In contrast to recent papers that directly adopt masked autoencoder (MAE) and only predict original coordinates or occupancy from masked point clouds, our method revisits differences between images and point clouds and identifies three self-supervised learning objectives peculiar to point clouds, namely centroid prediction, normal estimation, and curvature prediction. Combined with occupancy prediction, these four objectives yield an nontrivial self-supervised learning task and mutually facilitate models to better reason fine-grained geometry of point clouds. Our pipeline is conceptually simple and it consists of two major steps: first, it randomly masks out groups of points, followed by a Transformer-based point cloud encoder; second, a lightweight Transformer decoder predicts centroid, normal, and curvature for points in each voxel. We transfer the pre-trained Transformer encoder to a downstream peception model. On the nuScene Datset, our model achieves 3.38 mAP improvment for object detection, 2.1 mIoU gain for segmentation, and 1.7 AMOTA gain for multi-object tracking. We also conduct experiments on the Waymo Open Dataset and achieve significant performance improvements over baselines as well.
Surface Representation for Point Clouds
May 13, 2022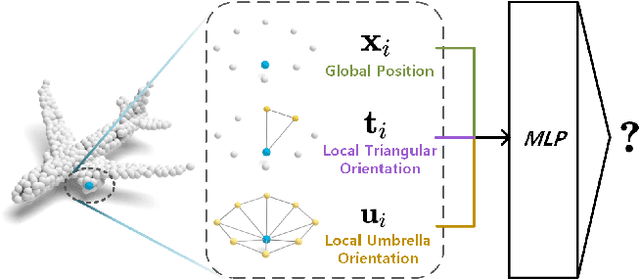
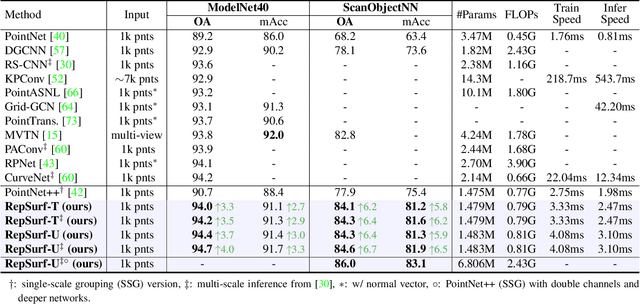
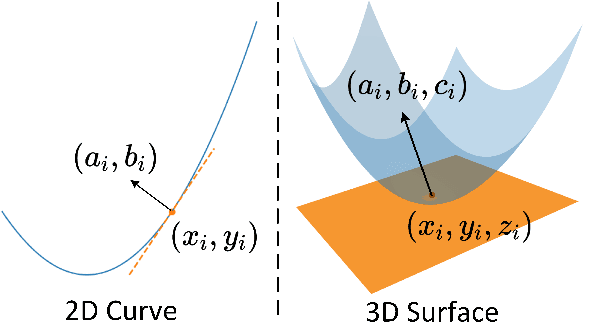
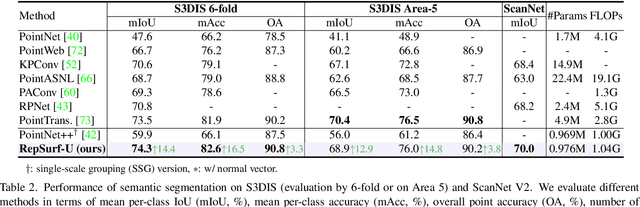
Most prior work represents the shapes of point clouds by coordinates. However, it is insufficient to describe the local geometry directly. In this paper, we present \textbf{RepSurf} (representative surfaces), a novel representation of point clouds to \textbf{explicitly} depict the very local structure. We explore two variants of RepSurf, Triangular RepSurf and Umbrella RepSurf inspired by triangle meshes and umbrella curvature in computer graphics. We compute the representations of RepSurf by predefined geometric priors after surface reconstruction. RepSurf can be a plug-and-play module for most point cloud models thanks to its free collaboration with irregular points. Based on a simple baseline of PointNet++ (SSG version), Umbrella RepSurf surpasses the previous state-of-the-art by a large margin for classification, segmentation and detection on various benchmarks in terms of performance and efficiency. With an increase of around \textbf{0.008M} number of parameters, \textbf{0.04G} FLOPs, and \textbf{1.12ms} inference time, our method achieves \textbf{94.7\%} (+0.5\%) on ModelNet40, and \textbf{84.6\%} (+1.8\%) on ScanObjectNN for classification, while \textbf{74.3\%} (+0.8\%) mIoU on S3DIS 6-fold, and \textbf{70.0\%} (+1.6\%) mIoU on ScanNet for segmentation. For detection, previous state-of-the-art detector with our RepSurf obtains \textbf{71.2\%} (+2.1\%) mAP$\mathit{_{25}}$, \textbf{54.8\%} (+2.0\%) mAP$\mathit{_{50}}$ on ScanNetV2, and \textbf{64.9\%} (+1.9\%) mAP$\mathit{_{25}}$, \textbf{47.7\%} (+2.5\%) mAP$\mathit{_{50}}$ on SUN RGB-D. Our lightweight Triangular RepSurf performs its excellence on these benchmarks as well. The code is publicly available at \url{https://github.com/hancyran/RepSurf}.
Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework
Feb 15, 2022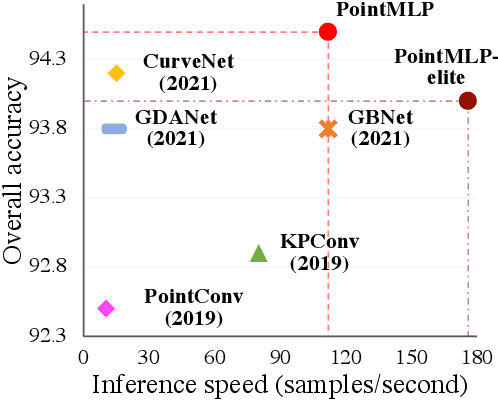

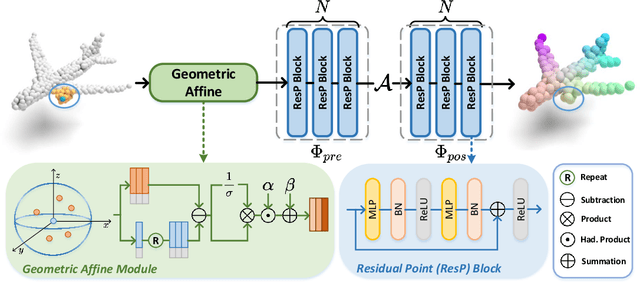
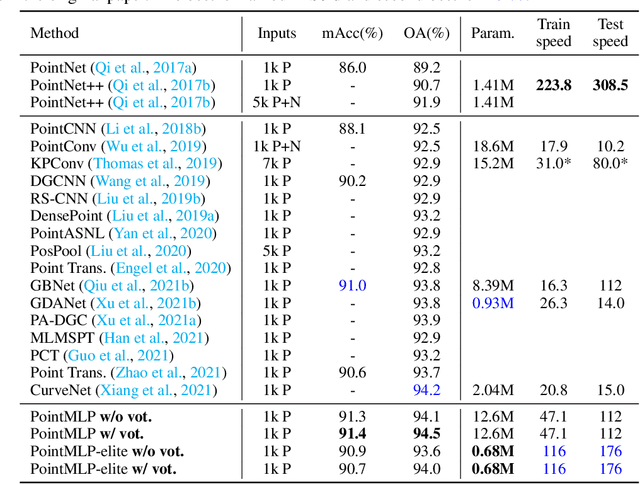
Point cloud analysis is challenging due to irregularity and unordered data structure. To capture the 3D geometries, prior works mainly rely on exploring sophisticated local geometric extractors using convolution, graph, or attention mechanisms. These methods, however, incur unfavorable latency during inference, and the performance saturates over the past few years. In this paper, we present a novel perspective on this task. We notice that detailed local geometrical information probably is not the key to point cloud analysis -- we introduce a pure residual MLP network, called PointMLP, which integrates no sophisticated local geometrical extractors but still performs very competitively. Equipped with a proposed lightweight geometric affine module, PointMLP delivers the new state-of-the-art on multiple datasets. On the real-world ScanObjectNN dataset, our method even surpasses the prior best method by 3.3% accuracy. We emphasize that PointMLP achieves this strong performance without any sophisticated operations, hence leading to a superior inference speed. Compared to most recent CurveNet, PointMLP trains 2x faster, tests 7x faster, and is more accurate on ModelNet40 benchmark. We hope our PointMLP may help the community towards a better understanding of point cloud analysis. The code is available at https://github.com/ma-xu/pointMLP-pytorch.
Learning Inner-Group Relations on Point Clouds
Aug 27, 2021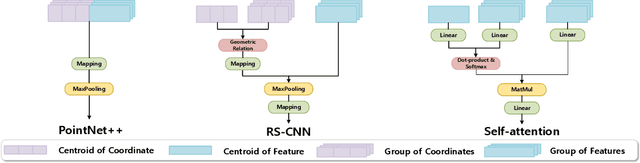
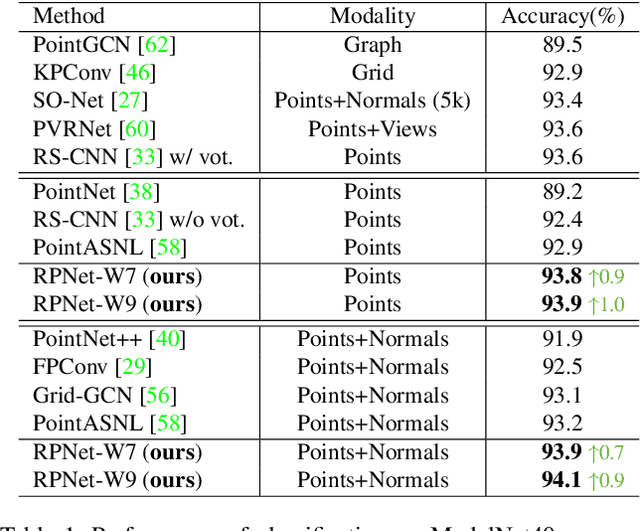
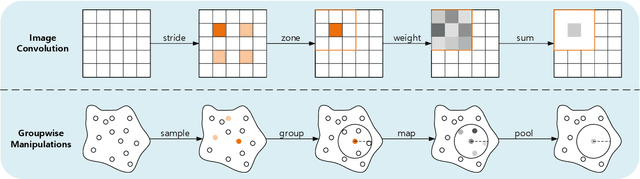
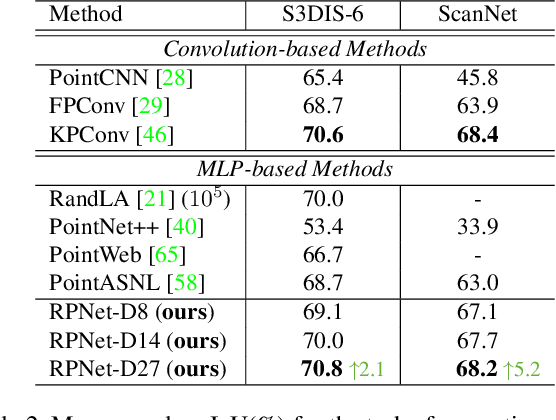
The prevalence of relation networks in computer vision is in stark contrast to underexplored point-based methods. In this paper, we explore the possibilities of local relation operators and survey their feasibility. We propose a scalable and efficient module, called group relation aggregator. The module computes a feature of a group based on the aggregation of the features of the inner-group points weighted by geometric relations and semantic relations. We adopt this module to design our RPNet. We further verify the expandability of RPNet, in terms of both depth and width, on the tasks of classification and segmentation. Surprisingly, empirical results show that wider RPNet fits for classification, while deeper RPNet works better on segmentation. RPNet achieves state-of-the-art for classification and segmentation on challenging benchmarks. We also compare our local aggregator with PointNet++, with around 30% parameters and 50% computation saving. Finally, we conduct experiments to reveal the robustness of RPNet with regard to rigid transformation and noises.
RIN: Textured Human Model Recovery and Imitation with a Single Image
Nov 29, 2020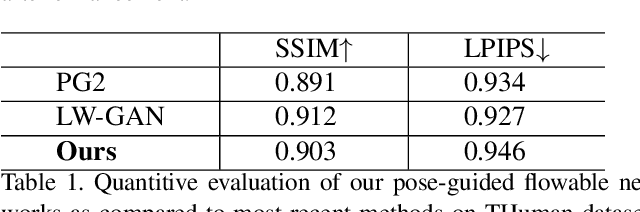
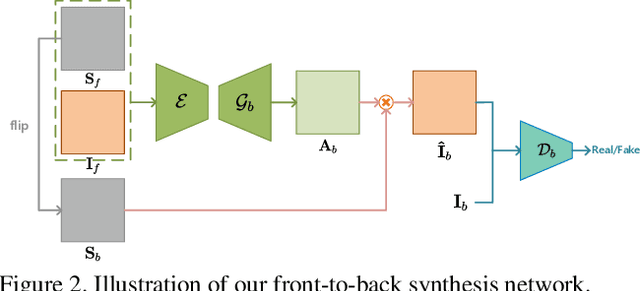
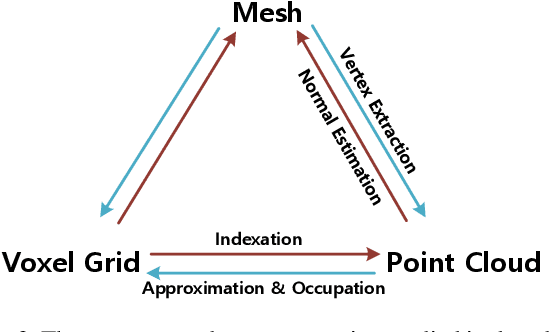

Human imitation has become topical recently, driven by GAN's ability to disentangle human pose and body content. However, the latest methods hardly focus on 3D information, and to avoid self-occlusion, a massive amount of input images are needed. In this paper, we propose RIN, a novel volume-based framework for reconstructing a textured 3D model from a single picture and imitating a subject with the generated model. Specifically, to estimate most of the human texture, we propose a U-Net-like front-to-back translation network. With both front and back images input, the textured volume recovery module allows us to color a volumetric human. A sequence of 3D poses then guides the colored volume via Flowable Disentangle Networks as a volume-to-volume translation task. To project volumes to a 2D plane during training, we design a differentiable depth-aware renderer. Our experiments demonstrate that our volume-based model is adequate for human imitation, and the back view can be estimated reliably using our network. While prior works based on either 2D pose or semantic map often fail for the unstable appearance of a human, our framework can still produce concrete results, which are competitive to those imagined from multi-view input.
Deeper or Wider Networks of Point Clouds with Self-attention?
Nov 29, 2020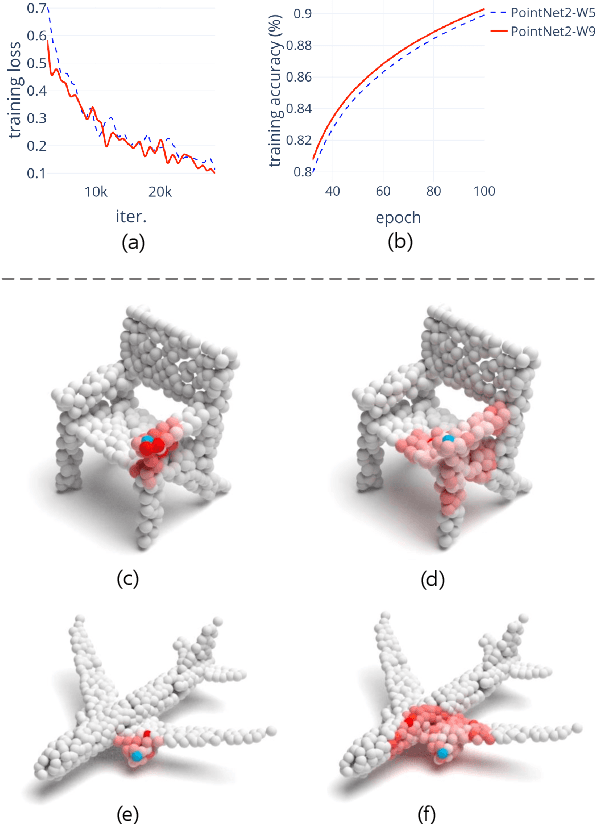
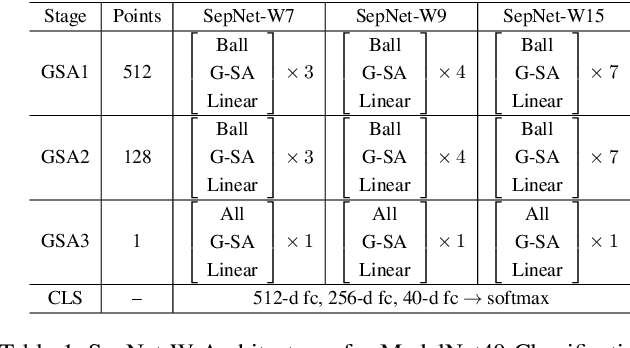
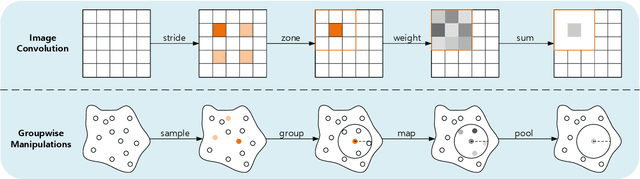
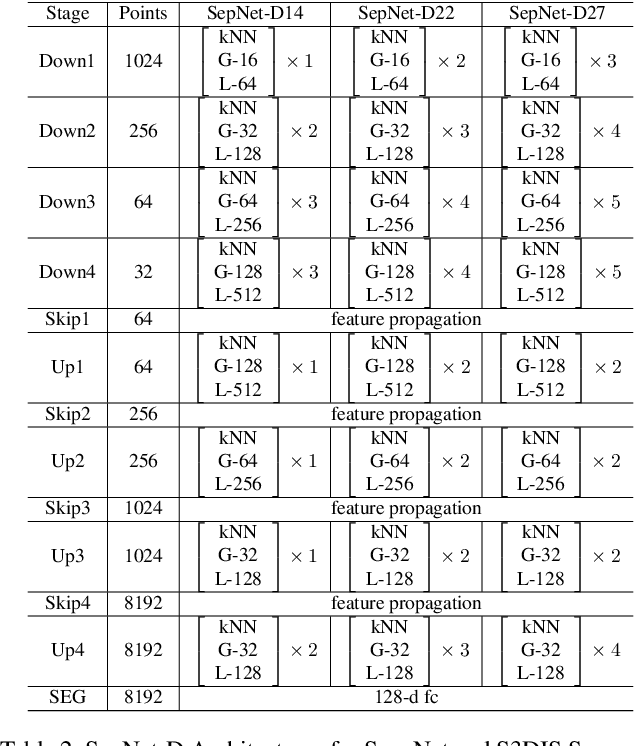
Prevalence of deeper networks driven by self-attention is in stark contrast to underexplored point-based methods. In this paper, we propose groupwise self-attention as the basic block to construct our network: SepNet. Our proposed module can effectively capture both local and global dependencies. This module computes the features of a group based on the summation of the weighted features of any point within the group. For convenience, we generalize groupwise operations to assemble this module. To further facilitate our networks, we deepen and widen SepNet on the tasks of segmentation and classification respectively, and verify its practicality. Specifically, SepNet achieves state-of-the-art for the tasks of classification and segmentation on most of the datasets. We show empirical evidence that SepNet can obtain extra accuracy in classification or segmentation from increased width or depth, respectively.